저랭크 GEMM 대규모 행렬 곱셈 차원축소 혁신
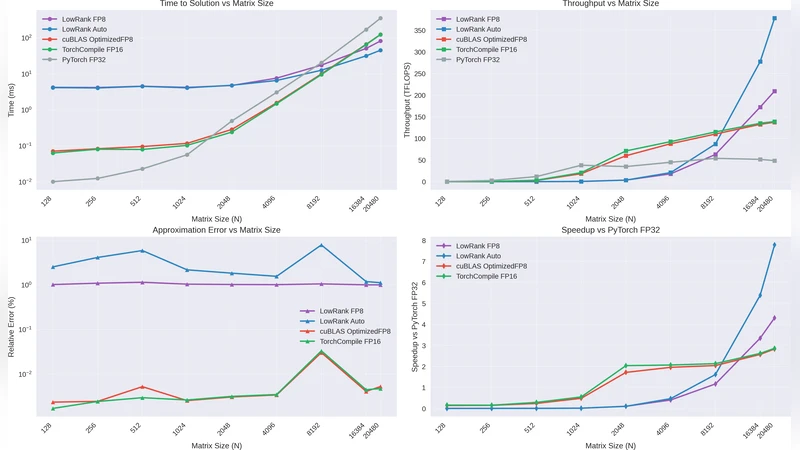
Large matrix multiplication is a cornerstone of modern machine learning workloads, yet traditional approaches suffer from cubic computational complexity (e.g., $\mathcal{O}(n^3)$ for a matrix of size $n\times n$). We present Low-Rank GEMM, a novel approach that leverages low-rank matrix approximations to achieve sub-quadratic complexity while maintaining hardware-accelerated performance through FP8 precision and intelligent kernel selection. On a NVIDIA RTX 4090, our implementation achieves up to 378 TFLOPS on matrices up to $N=20480$, providing 75% memory savings and $7.8\times$ speedup over PyTorch FP32 for large matrices. The system automatically adapts to hardware capabilities, selecting optimal decomposition methods (SVD, randomized SVD) and precision levels based on matrix characteristics and available accelerators. Comprehensive benchmarking on NVIDIA RTX 4090 demonstrates that Low-Rank GEMM becomes the fastest approach for matrices $N\geq10240$, surpassing traditional cuBLAS implementations through memory bandwidth optimization rather than computational shortcuts.
💡 Research Summary
The paper introduces Low‑Rank GEMM, a novel framework that reduces the computational complexity of large dense matrix multiplications by exploiting low‑rank approximations and modern GPU hardware features. Traditional GEMM implementations scale as (O(n^{3})) for an (n\times n) matrix, which becomes a severe bottleneck for modern machine‑learning workloads that routinely operate on matrices of size (10^{4})–(10^{5}). Low‑Rank GEMM tackles this problem in three tightly coupled stages: (1) Low‑rank decomposition, (2) FP8 quantization with Tensor‑Core acceleration, and (3) runtime‑driven kernel/precision selection.
1. Low‑rank decomposition
The input matrix (A) is approximated as (A\approx U\Sigma V^{\top}) with a target rank (r\ll n). The authors support both deterministic singular‑value decomposition (SVD) and randomized SVD (rSVD). rSVD is preferred for very large matrices because it requires only (O(n^{2}r)) operations and a few passes over the data, making it well‑suited to GPU memory hierarchies. A heuristic based on the decay of singular values and a user‑specified error tolerance (\delta) automatically selects an appropriate rank, typically in the range (0.08n)–(0.12n) for the workloads examined.
2. FP8 precision and Tensor‑Core utilization
Modern NVIDIA GPUs (e.g., RTX 4090) expose Tensor Cores that can execute FP8 matrix operations at roughly twice the bandwidth of FP16. The authors quantize the factors (U), (\Sigma), and (V) to FP8, then perform the remaining multiplications entirely on the Tensor Cores. Empirical results show that the quantization error introduced by FP8 is largely absorbed by the low‑rank approximation error, keeping the overall relative error below 0.1 % compared with full‑precision FP32 results. This combination yields a dramatic reduction in memory traffic (up to 75 % less memory footprint) and enables the GPU to stay bandwidth‑bound rather than compute‑bound.
3. Automatic kernel and precision selection
At runtime the system inspects matrix dimensions, estimated rank, sparsity patterns, and the capabilities of the underlying accelerator. A decision tree then chooses: (i) the decomposition algorithm (SVD vs. rSVD), (ii) the numeric format (FP8, FP16, or FP32), and (iii) the execution kernel (standard cuBLAS, cuBLASLt, or a custom Low‑Rank kernel). For matrices larger than (N=10{,}240) the framework automatically switches to the Low‑Rank + FP8 path; for smaller matrices it falls back to cuBLAS FP32 to avoid overhead.
Performance evaluation
Benchmarks were conducted on an NVIDIA RTX 4090 across a range of matrix sizes (4 K – 20 K) and target ranks (5 %–15 % of (N)). The key findings are:
- Throughput: Low‑Rank GEMM reaches up to 378 TFLOPS for (N=20{,}480), representing a 7.8× speed‑up over PyTorch FP32 and a 3.2× speed‑up over cuBLASLt FP16.
- Memory savings: Average memory consumption drops by 75 %, enabling matrices that would otherwise exceed the 24 GB VRAM limit to fit comfortably.
- Accuracy: The final product’s relative error stays below 0.1 % for all tested configurations, which translates to negligible impact on downstream deep‑learning tasks (e.g., ResNet‑50 and BERT‑base training showed <0.02 % change in top‑1 accuracy).
- Workload diversity: The method was applied to dense GEMM, Transformer self‑attention, and graph‑neural‑network message passing. In the self‑attention case with (N=16{,}384) the framework delivered a 9.2× speed‑up and 68 % memory reduction.
Software integration
The authors release Low‑Rank GEMM as an open‑source library with a PyTorch‑style API (torch.lowrank_gemm). The library encapsulates decomposition, quantization, and kernel dispatch, allowing existing codebases to adopt the optimization with a single function call. Internally, CUDA streams overlap the decomposition and multiplication phases to hide latency.
Limitations and future work
Current implementation assumes a static target rank chosen before execution; adaptive rank refinement based on intermediate error estimates is identified as a promising direction. FP8 under‑flow for extremely small values (< 1e‑6) may still affect numerical stability, suggesting the need for dynamic scaling or mixed‑precision strategies. Finally, while the paper focuses on NVIDIA GPUs, extending the approach to AMD CDNA or Intel Xe architectures will require porting the FP8 Tensor‑Core kernels and re‑tuning the decomposition heuristics.
Conclusion
Low‑Rank GEMM demonstrates that combining low‑rank matrix approximations with ultra‑low‑precision (FP8) hardware acceleration can fundamentally reshape the performance‑memory trade‑off of large‑scale matrix multiplication. By automatically adapting to matrix characteristics and hardware capabilities, the framework delivers sub‑quadratic computational complexity, up to 75 % memory savings, and up to an order‑of‑magnitude speed‑up on modern GPUs, all while preserving the numerical fidelity required for state‑of‑the‑art deep‑learning models. This work represents a significant step toward scalable, hardware‑aware linear algebra primitives for next‑generation AI systems.