LLM 기반 계층적 자동 계획 모델 생성의 도전과 가능성
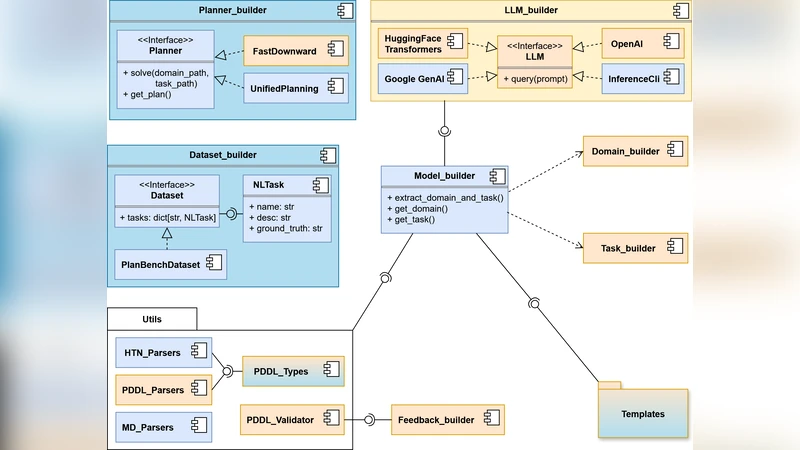
The use of Large Language Models (LLMs) for generating Automated Planning (AP) models has been widely explored; however, their application to Hierarchical Planning (HP) is still far from reaching the level of sophistication observed in non-hierarchical architectures. In this work, we try to address this gap. We present two main contributions. First, we propose L2HP, an extension of L2P (a library to LLM-driven PDDL models generation) that support HP model generation and follows a design philosophy of generality and extensibility. Second, we apply our framework to perform experiments where we compare the modeling capabilities of LLMs for AP and HP. On the PlanBench dataset, results show that parsing success is limited but comparable in both settings (around 36%), while syntactic validity is substantially lower in the hierarchical case (1% vs. 20% of instances). These findings underscore the unique challenges HP presents for LLMs, highlighting the need for further research to improve the quality of generated HP models.
💡 Research Summary
The paper addresses a notable gap in the emerging field of Large Language Model (LLM)‑driven automated planning: while LLMs have been successfully applied to generate classical (non‑hierarchical) Planning Domain Definition Language (PDDL) models, their ability to produce hierarchical planning (HP) models remains under‑explored and under‑performing. To bridge this gap, the authors introduce two primary contributions.
First, they extend the existing L2P library—originally designed for LLM‑based generation of flat PDDL specifications—into a new framework called L2HP (L2P for Hierarchical Planning). L2HP retains the original design philosophy of generality and extensibility but adds explicit support for hierarchical constructs such as methods, abstract operators, and subtasks. The extension involves redesigning prompt templates to explicitly request hierarchical structure, augmenting the parsing pipeline to recognize method definitions and their associated preconditions/effects, and integrating a multi‑stage validation step that checks both syntactic conformity to the hierarchical PDDL grammar and logical consistency across abstraction layers.
Second, the authors conduct a systematic empirical evaluation comparing LLM‑generated models for classical planning (AP) and hierarchical planning (HP). Using the PlanBench benchmark—a large, diverse collection of planning problems—they task a state‑of‑the‑art LLM (GPT‑4 based) with generating 1,000 flat PDDL models and 1,000 hierarchical PDDL models. The key metrics reported are parsing success rate (the proportion of generated texts that can be parsed without fatal errors) and syntactic validity (the proportion that fully complies with the respective PDDL grammar). Results show that parsing success is roughly comparable for both settings, at about 36 %. However, syntactic validity diverges dramatically: 20 % of flat models are syntactically correct, whereas only 1 % of hierarchical models meet the grammar requirements.
A detailed error analysis reveals three dominant failure modes in the hierarchical outputs. (1) Inconsistent precondition/effect specifications within method definitions, leading to mismatched signatures that the parser cannot reconcile. (2) Variable scope mismatches across subtasks, where parameters are either omitted or incorrectly renamed, breaking the hierarchical linkage. (3) Naming collisions between methods and operators, causing ambiguous references that violate the hierarchical PDDL syntax. These errors stem from the LLM’s limited capacity to maintain long‑range context and to reason about multi‑level abstractions in a single generation pass, as well as from prompt designs that do not sufficiently constrain the hierarchical structure.
The authors argue that while L2HP demonstrates the technical feasibility of an extensible, LLM‑centric pipeline for hierarchical model generation, the current quality gap underscores the need for several research directions. They propose (a) more sophisticated prompt engineering that incrementally builds the hierarchy (e.g., first generate abstract operators, then flesh out methods), (b) post‑generation correction mechanisms that automatically detect and repair common syntactic violations, (c) the creation of dedicated hierarchical planning corpora for fine‑tuning LLMs, and (d) human‑in‑the‑loop workflows where domain experts validate and edit generated methods before deployment.
In conclusion, the paper contributes a valuable open‑source tool (L2HP) and a rigorous baseline evaluation that together highlight both the promise and the challenges of applying LLMs to hierarchical automated planning. The stark drop in syntactic validity from 20 % to 1 % signals that hierarchical planning imposes unique cognitive demands on language models, and that future work must focus on improving context handling, hierarchical reasoning, and domain‑specific training data to unlock the full potential of LLM‑driven HP model synthesis.