📝 Original Info
- Title: 길이최적 토크나이저로 토큰 수와 연산 효율 크게 향상
- ArXiv ID: 2511.20849
- Date: 2025-11-25
- Authors: Dong Dong, Weijie Su
📝 Abstract
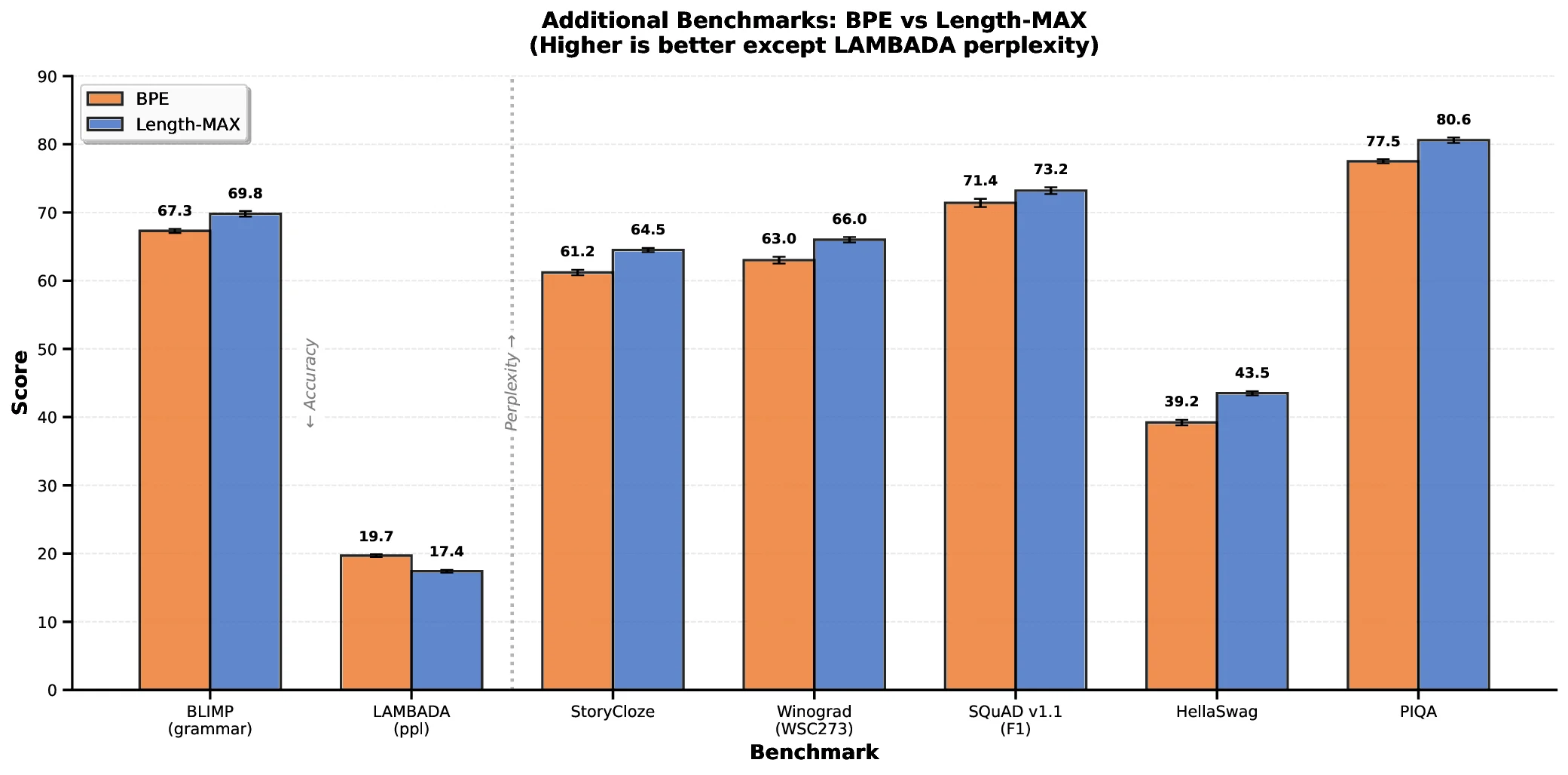
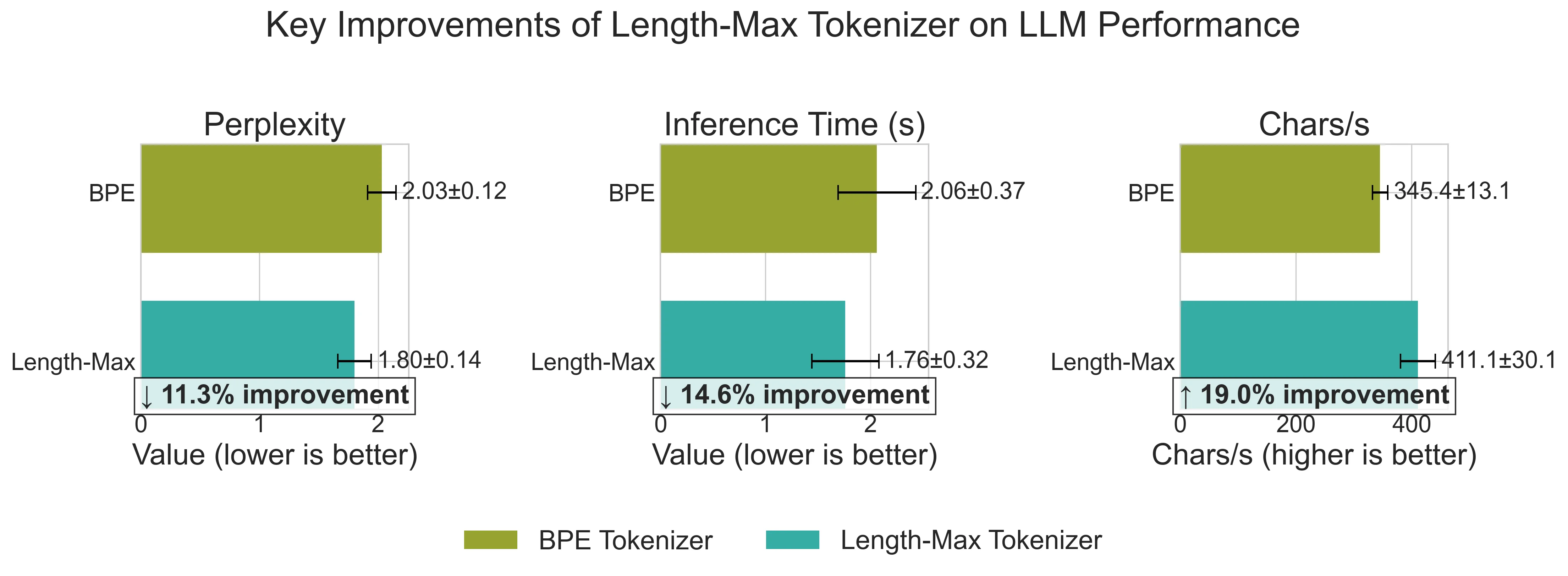
We introduce a new tokenizer for language models that minimizes the average tokens per character, thereby reducing the number of tokens needed to represent text during training and to generate text during inference. Our method, which we refer to as the Length-MAX tokenizer, obtains its vocabulary by casting a length-weighted objective maximization as a graph partitioning problem and developing a greedy approximation algorithm. On FineWeb and diverse domains, it yields 14-18% fewer tokens than Byte Pair Encoding (BPE) across vocabulary sizes from 10K to 50K, and the reduction is 13.0% when the size is 64K. Training GPT-2 models at 124M, 355M, and 1.3B parameters from scratch with five runs each shows 18.5%, 17.2%, and 18.5% fewer steps, respectively, to reach a fixed validation loss, and 13.7%, 12.7%, and 13.7% lower inference latency, together with a 16% throughput gain at 124M, while consistently improving on downstream tasks including reducing LAMBADA perplexity by 11.7% and enhancing HellaSwag accuracy by 4.3%. Moreover, the Length-MAX tokenizer achieves 99.62% vocabulary coverage and the out-of-vocabulary rate remains low at 0.12% on test sets. These results demonstrate that optimizing for average token length, rather than frequency alone, offers an effective approach to more efficient language modeling without sacrificing-and often improving-downstream performance. The tokenizer is compatible with production systems and reduces embedding and KV-cache memory by 18% at inference.
💡 Deep Analysis
Deep Dive into 길이최적 토크나이저로 토큰 수와 연산 효율 크게 향상.
We introduce a new tokenizer for language models that minimizes the average tokens per character, thereby reducing the number of tokens needed to represent text during training and to generate text during inference. Our method, which we refer to as the Length-MAX tokenizer, obtains its vocabulary by casting a length-weighted objective maximization as a graph partitioning problem and developing a greedy approximation algorithm. On FineWeb and diverse domains, it yields 14-18% fewer tokens than Byte Pair Encoding (BPE) across vocabulary sizes from 10K to 50K, and the reduction is 13.0% when the size is 64K. Training GPT-2 models at 124M, 355M, and 1.3B parameters from scratch with five runs each shows 18.5%, 17.2%, and 18.5% fewer steps, respectively, to reach a fixed validation loss, and 13.7%, 12.7%, and 13.7% lower inference latency, together with a 16% throughput gain at 124M, while consistently improving on downstream tasks including reducing LAMBADA perplexity by 11.7% and enhancin
📄 Full Content
Tokenization, the segmentation of text into discrete units, shapes both the computational efficiency and representational quality of modern language models (Jurafsky and Martin, 2009;Rust et al., 2020). Since the introduction of Byte Pair Encoding (BPE) (Sennrich et al., 2016), the dominant paradigm has centered on frequency-driven merging: iteratively combining the most common symbol pairs to construct compact vocabularies. BPE and its variants have succeeded across diverse applications, but they share a common limitation. By prioritizing token frequency above all else, these methods favor short, high-frequency substrings, fragmenting text into longer token sequences than necessary. Because attention complexity scales quadratically with sequence length, this fragmentation increases training time, inference latency, and memory consumption. Longer sequences also hinder models from maintaining long-range dependencies, degrading performance on tasks that require reasoning across extended contexts (Child et al., 2019;Press et al., 2020;Clark et al., 2022).
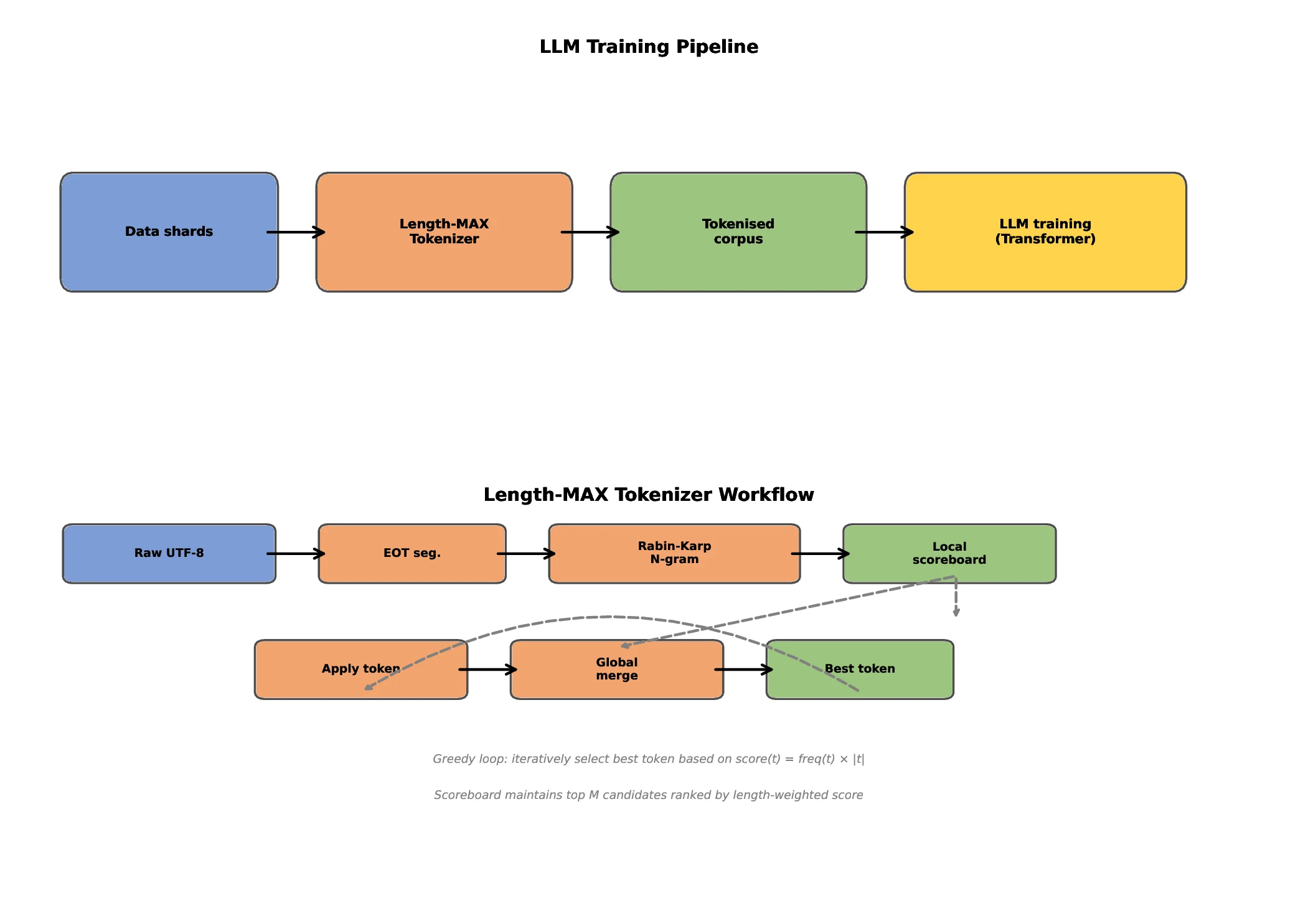
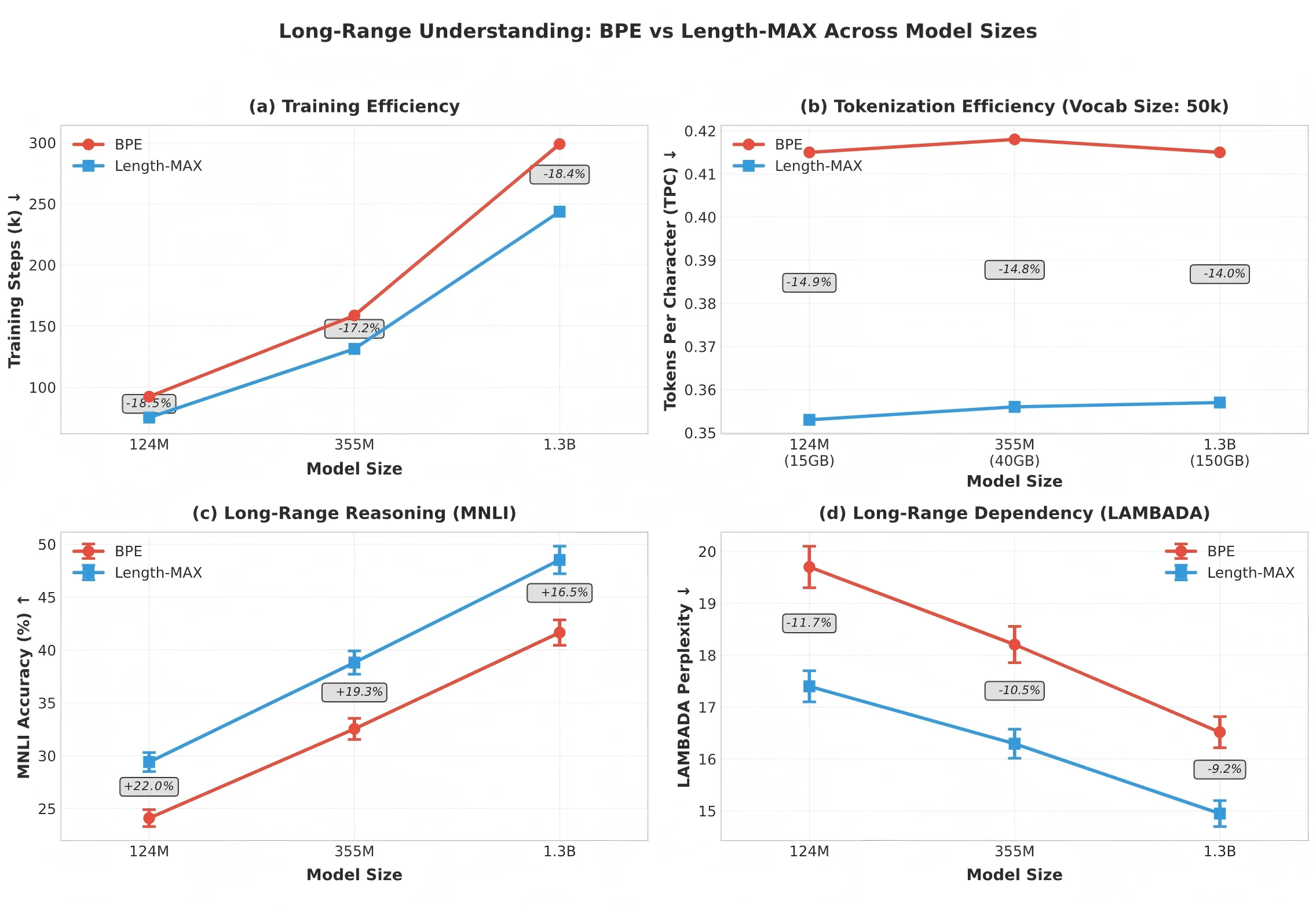
We introduce Length-MAX, a tokenizer that optimizes a length-weighted objective rather than frequency alone. Length-MAX maximizes the product score(t) = freq(t) × |t|, rewarding longer substrings that maintain high corpus coverage. On FineWeb across vocabulary sizes from 10k to 50k, Length-MAX reduces tokens per character (TPC) by 14-18% compared to BPE. Training GPT-2 models at 124M, 355M, and 1.3B parameters from scratch (five runs each) shows 18.5%, 17.2%, and 18.5% fewer steps to reach a fixed validation loss, and 13.7%, 12.7%, and 13.7% lower inference latency, with 16% throughput gain at 124M. Memory consumption for embeddings and key-value caches falls by 18%. On downstream tasks, LAMBADA perplexity decreases by 11.7% and HellaSwag accuracy increases by 4.3 points.
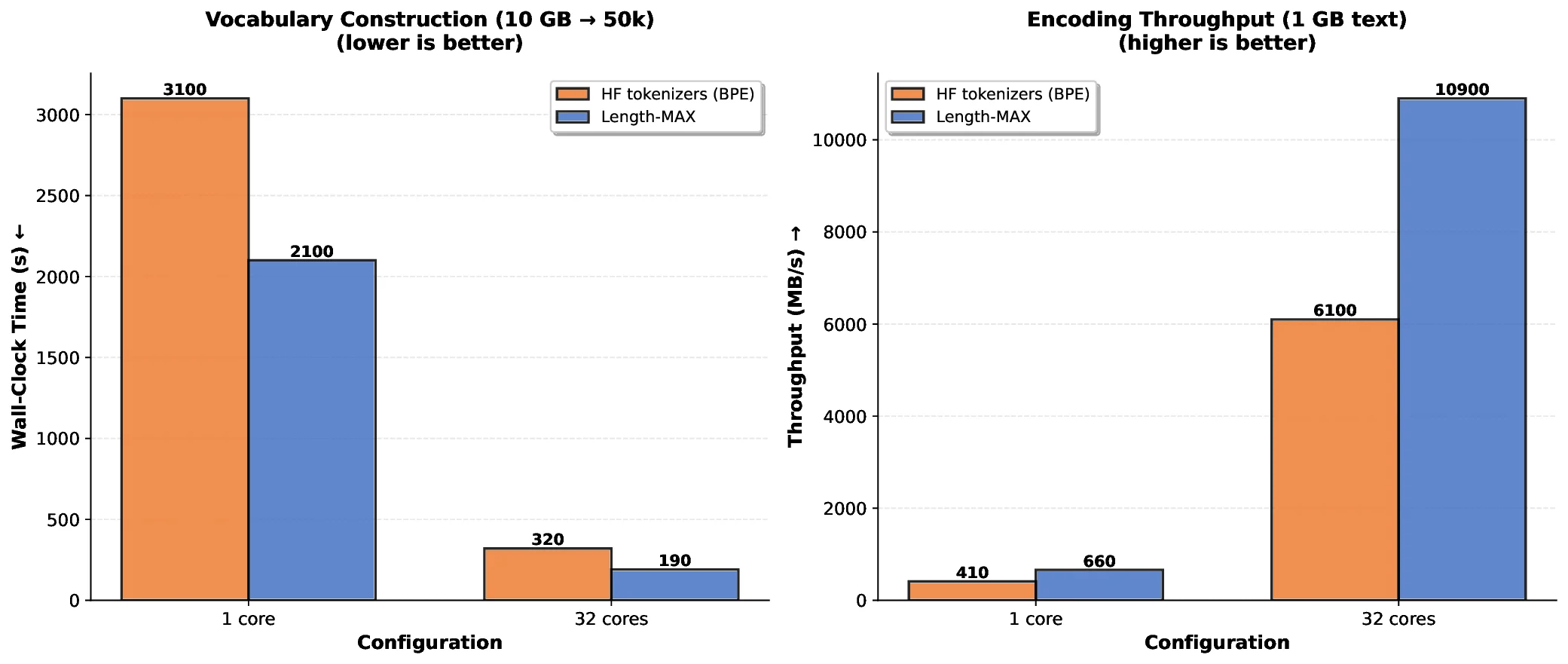
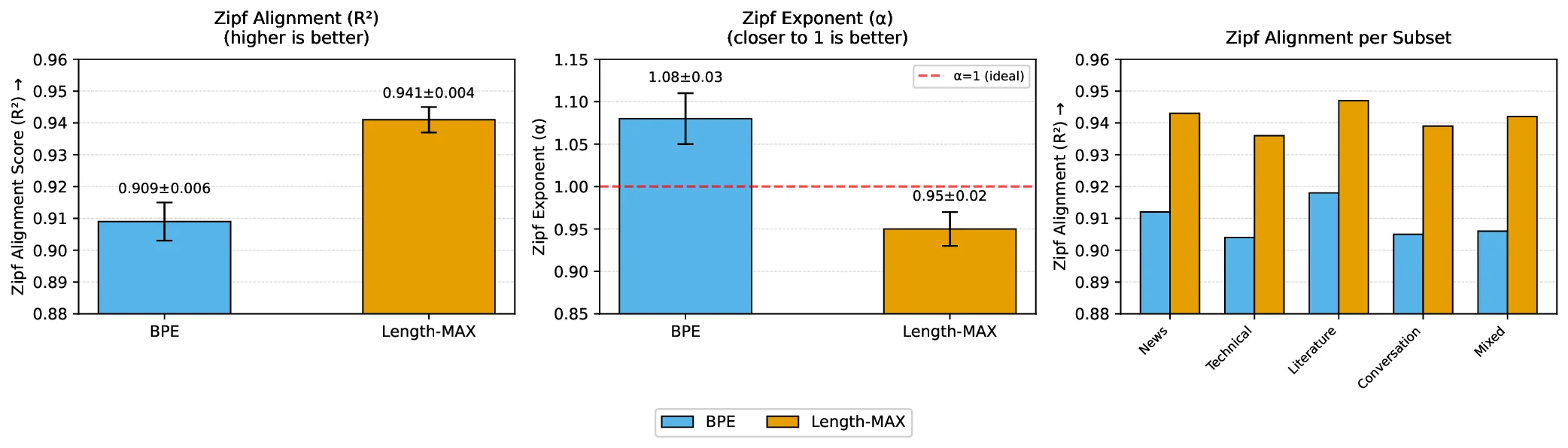
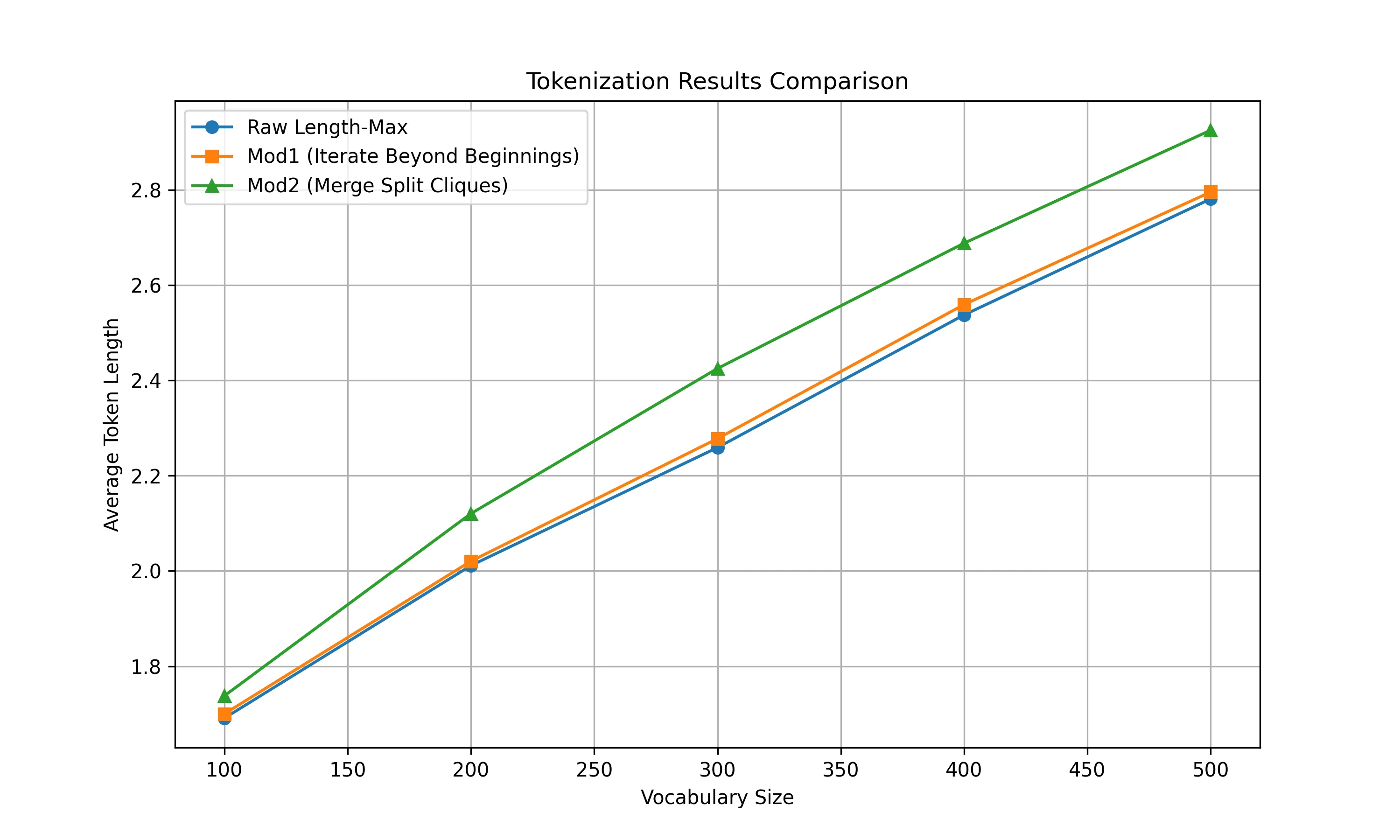
At 64k and 100k vocabularies, TPC reductions remain at 13.0% and 9.8% respectively. A FLOPs-based scaling curve suggests similar efficiency gains at 7B parameters. Our length-weighted objective operates on a different dimension than boundary-aware methods such as SuperBPE (Liu et al., 2025), making the two approaches orthogonal and potentially complementary. We formalize the problem as maximizing length-weighted coverage over a corpus, which we demonstrate is NP-hard through reduction to graph partitioning (Garey and Johnson, 1979). We develop a greedy O(N ) approximation algorithm using a scoreboard architecture with Rabin-Karp rolling hash (Karp and Rabin, 1987). This design enables parallel processing across hundreds of CPU cores, achieving 87% efficiency at 256 cores. Trained vocabularies compile into deterministic finite automata (DFAs) that decode 3-4 times faster than naive approaches. Zipf alignment analysis shows that Length-MAX preserves the power-law frequency structure known to correlate with model quality (R 2 = 0.941, α = 0.95 ± 0.02).
This work makes several contributions. First, we propose a length-weighted objective that optimizes freq(t) × |t| rather than frequency alone. Second, we formalize the problem as NP-hard graph partitioning and develop a greedy O(N ) approximation with monotonicity guarantees. Third, we present a production-ready implementation with scoreboard-based parallelism (87% efficiency at 256 cores) and DFA-based decoding (3-4× faster). Fourth, we demonstrate that Length-MAX reduces TPC by 14-18%, accelerates training by 18.5% at 124M (p < 0.001), lowers inference latency by 13.7%, and cuts memory by 18%, validated across five independent runs. Finally, we show through Zipf alignment analysis (R 2 = 0.941, α = 0.95 ± 0.02) that these improvements preserve the power-law structure known to correlate with model quality.
Subword tokenization. Modern tokenization relies on data-driven subword methods: BPE (Sennrich et al., 2016), WordPiece (Schuster and Nakajima, 2012), and SentencePiece (Kudo and Richardson, 2018). These methods handle out-of-vocabulary (OOV) words gracefully by decomposing unseen terms into known subword units. However, their frequency-driven merge strategies favor short, high-frequency fragments, fragmenting text into longer sequences. This increases attention complexity quadratically and slows both training and inference (Child et al., 2019;Press et al., 2020;Clark et al., 2022).
Linguistically informed methods. Methods like MorphPiece (Jabbar, 2023), FLOTA (Hofmann et al., 2022), and SuperBPE (Liu et al., 2025) incorporate linguistic structure into tokenization. Recent work by Liu et al. (2025) employs curriculum learning to construct “superwords” spanning word boundaries, achieving 33% sequence length reduction at 200k vocabularies. Su-perBPE’s boundary-aware heuristics and our length-weighted objective address different dimensions: SuperBPE refines which substrings to prioritize through linguistic boundaries, while Length-MAX optimizes directly for substring length. These approaches are orthogonal and potentially complementary.
Eng
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.