Title: From Passive Perception to Active Memory: A Weakly Supervised Image Manipulation Localization Framework Driven by Coarse-Grained Annotations
ArXiv ID: 2511.20359
Date: 2025-11-25
Authors: Researchers from original ArXiv paper
📝 Abstract
Image manipulation localization (IML) faces a fundamental trade-off between minimizing annotation cost and achieving fine-grained localization accuracy. Existing fully-supervised IML methods depend heavily on dense pixel-level mask annotations, which limits scalability to large datasets or real-world deployment. In contrast, the majority of existing weakly-supervised IML approaches are based on image-level labels, which greatly reduce annotation effort but typically lack precise spatial localization. To address this dilemma, we propose BoxPromptIML, a novel weakly-supervised IML framework that effectively balances annotation cost and localization performance. Specifically, we propose a coarse region annotation strategy, which can generate relatively accurate manipulation masks at lower cost. To improve model efficiency and facilitate deployment, we further design an efficient lightweight student model, which learns to perform fine-grained localization through knowledge distillation from a fixed teacher model based on the Segment Anything Model (SAM). Moreover, inspired by the human subconscious memory mechanism, our feature fusion module employs a dualguidance strategy that actively contextualizes recalled prototypical patterns with real-time observational cues derived from the input. Instead of passive feature extraction, this strategy enables a dynamic process of knowledge recollection, where long-term memory is adapted to the specific context of the current image, significantly enhancing localization accuracy and robustness. Extensive experiments across both indistribution and out-of-distribution datasets show that Box-PromptIML outperforms or rivals fully-supervised models, while maintaining strong generalization, low annotation cost, and efficient deployment characteristics.
💡 Deep Analysis
Deep Dive into From Passive Perception to Active Memory: A Weakly Supervised Image Manipulation Localization Framework Driven by Coarse-Grained Annotations.
Image manipulation localization (IML) faces a fundamental trade-off between minimizing annotation cost and achieving fine-grained localization accuracy. Existing fully-supervised IML methods depend heavily on dense pixel-level mask annotations, which limits scalability to large datasets or real-world deployment. In contrast, the majority of existing weakly-supervised IML approaches are based on image-level labels, which greatly reduce annotation effort but typically lack precise spatial localization. To address this dilemma, we propose BoxPromptIML, a novel weakly-supervised IML framework that effectively balances annotation cost and localization performance. Specifically, we propose a coarse region annotation strategy, which can generate relatively accurate manipulation masks at lower cost. To improve model efficiency and facilitate deployment, we further design an efficient lightweight student model, which learns to perform fine-grained localization through knowledge distillation fro
📄 Full Content
Ensuring the authenticity of digital images has become increasingly challenging due to the widespread availability of powerful image editing and generation technologies. These technologies, such as advanced copy-move (He et al. 2024),
cut-paste techniques and GAN-based manipulation, have been misused in misinformation, deepfake content (Gu et al. 2024), and financial fraud, posing serious risks to social trust and public safety. As a result, IML has emerged as a vital research topic in the fields of computer vision and multimedia forensics.
Although recent advances have improved IML capabilities, the field still faces a critical trade-off between localization accuracy and annotation cost, as also evidenced by the unified benchmark analysis in ForensicHub (Du et al. 2025). A major bottleneck lies in the scarcity of real-world manipulated images with high-quality groundtruth masks (Novozamsky, Mahdian, and Saic 2020). This scarcity is largely due to the prohibitively high cost of manually annotating fine-grained manipulation boundaries, especially when the tampered objects involve intricate textures or complex edges. Creating such pixel-level masks typically requires annotators to perform meticulous per-pixel comparisons along object boundaries, making the process extremely time-consuming and labor-intensive. This challenge has significantly hindered the scalability of IML datasets and the broader development of the field. To mitigate this issue, some weakly supervised IML methods have been proposed, typically leveraging image-level labels to minimize annotation effort, though they generally lack precise spatial supervision.
To the best of our knowledge, there is currently no quantitative analysis of how long it takes humans to annotate different types of supervision for real-world manipulated images. To address this gap, we conducted a controlled user study involving 10 volunteers, who were asked to annotate 100 tampered images along with their corresponding authentic versions. These image pairs were selected from realworld manipulation examples in the IMD2020 (Novozamsky, Mahdian, and Saic 2020) and In-the-Wild (Huh et al. 2018) datasets. During annotation, participants were allowed to refer to both the tampered and original images to assist in identifying manipulated regions. The labeling tasks included generating pixel-level manipulation masks, imagelevel real/fake labels, and coarse bounding boxes. The time required for each annotation type was carefully recorded, and cross-validation was performed among participants to ensure annotation quality and consistency. All annotations were conducted using the CVAT platform.
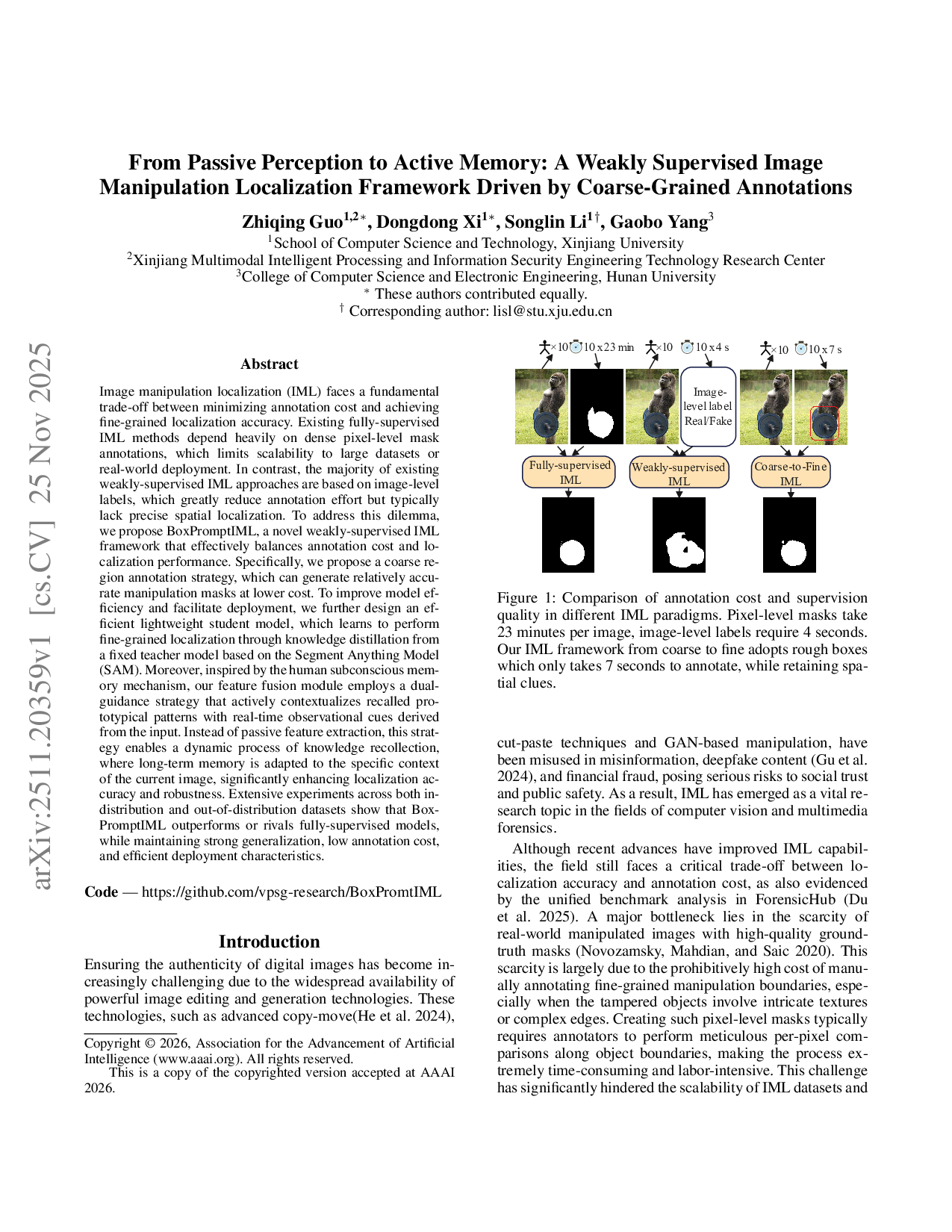
As illustrated in Figure 1, we compare three representative supervision strategies in IML:
• Fully-supervised IML, which relies on pixel-level manipulation masks and offers the highest localization accuracy, but suffers from prohibitively high annotation cost-up to 23 minutes per image in our user study. • Weakly-supervised IML methods that rely on imagelevel real/fake labels significantly reduce annotation effort (4 seconds per image), but fails to provide any spatial guidance, often resulting in poor localization. • The proposed Coarse-to-Fine IML, which uses rough bounding box annotations and reduces annotation time to about 7 seconds per image, while still preserving essential spatial information.
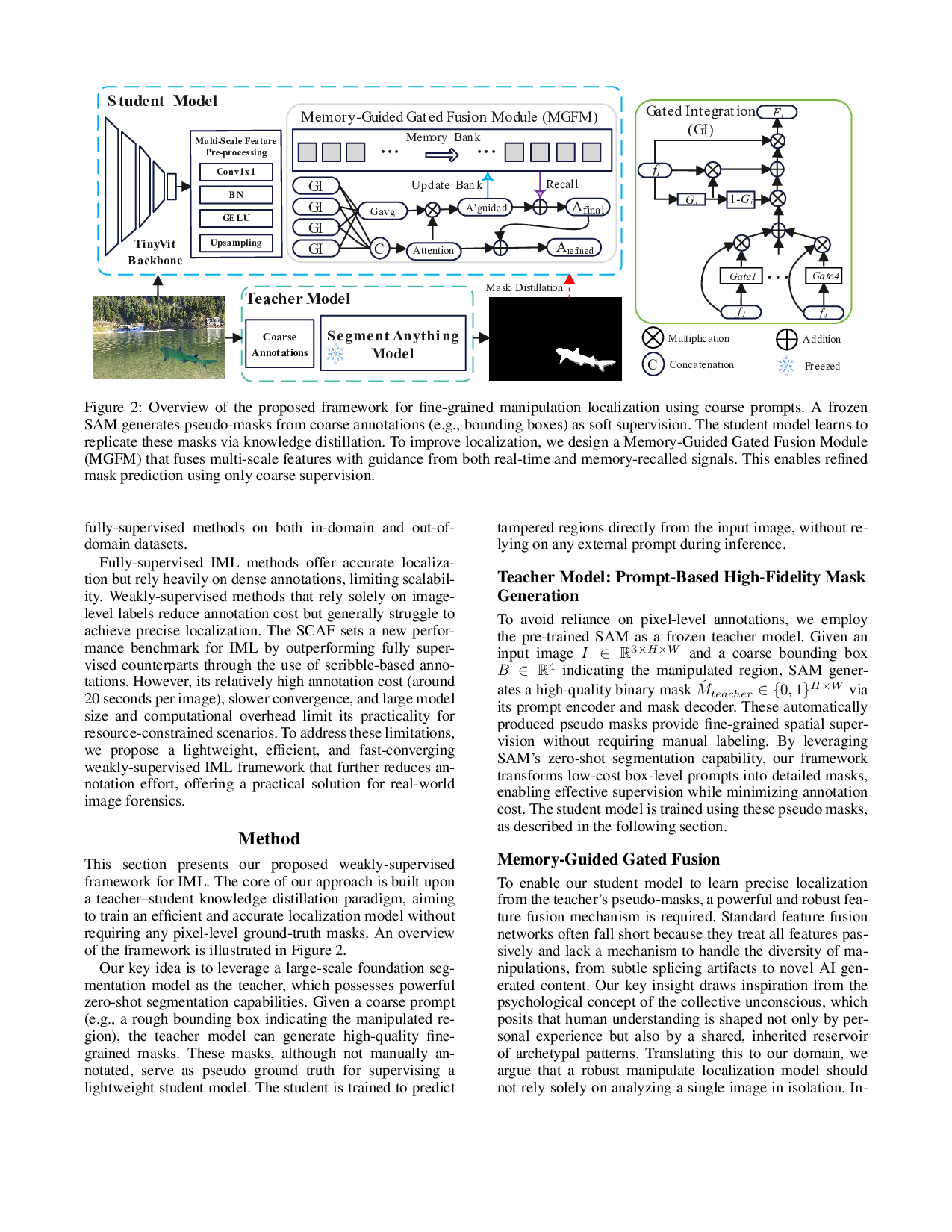
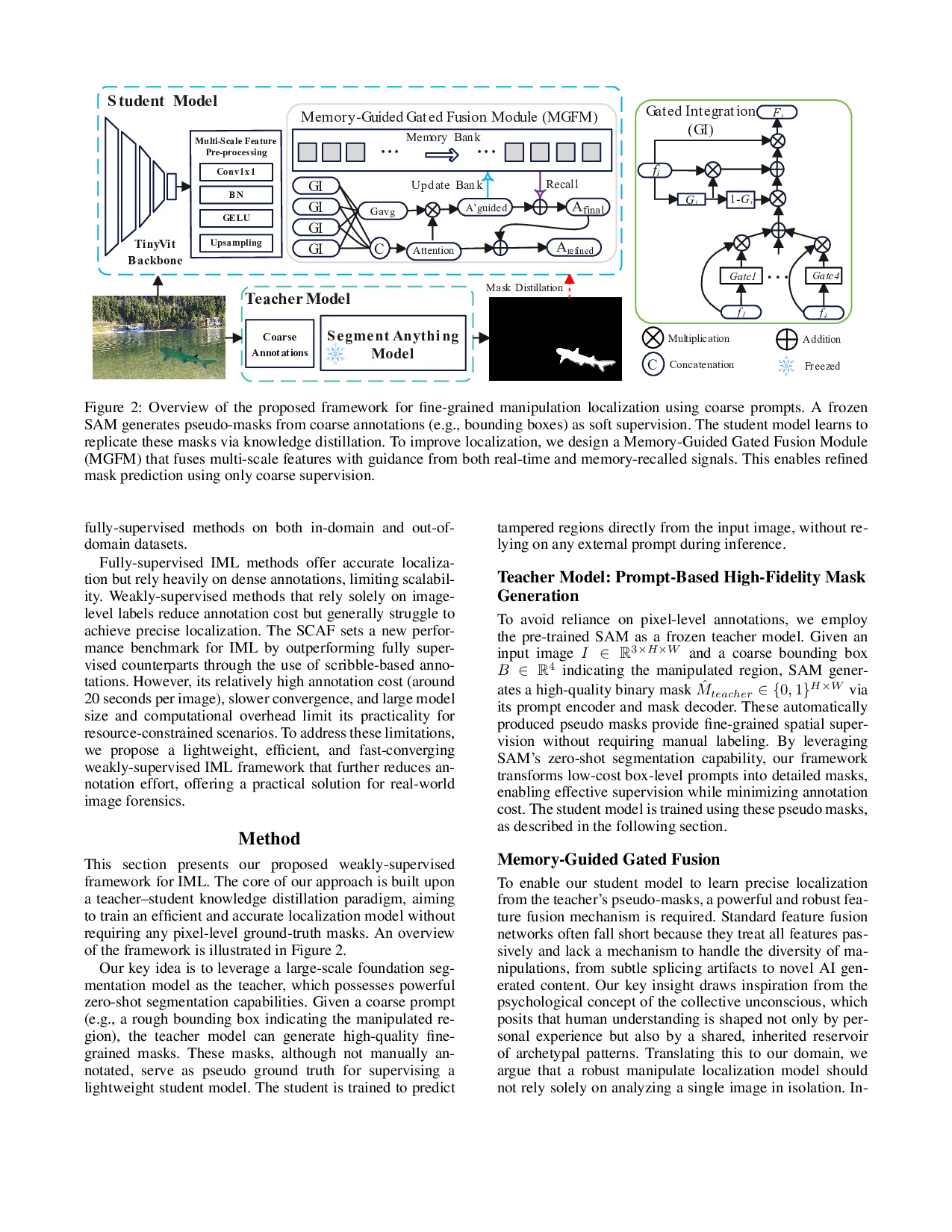
The results above clearly show that rough bounding box annotation offers a compelling cost-performance trade-off, reducing labeling effort by over 98% compared to full supervision, while preserving essential spatial cues for learning. This motivates the need for a middle-ground solution that preserves spatial localization signals without incurring the high cost of pixel-level annotations. Thus, we design a coarse-to-fine localization approach in which simple bounding boxes act as inexpensive yet informative prompts to guide the model training. A frozen SAM (Kirillov et al. 2023) is then used to transform these coarse prompts into fine-grained pseudo masks. These pseudo masks serve as soft supervision signals to train a lightweight student model, which can independently localize manipulation during inference. Inspired by theories of collective memory and selective attention, we design a Memory-Guided Gated Fusion Module (MGFM) to further enhance the localization performance of the student model. This module maintains a learnable memory bank that stores prototypical manipulation patterns, and employs a gating mechanism to selectively fuse multi-scale features based on their relevance. Memory bank is structurally advantageous as it decouples knowledge aggregation from the network’s weights