MedVision: Dataset and Benchmark for Quantitative Medical Image Analysis
Current vision-language models (VLMs) in medicine are primarily designed for categorical question answering (e.g., “Is this normal or abnormal?”) or qualitative descriptive tasks. However, clinical decision-making often relies on quantitative assessments, such as measuring the size of a tumor or the angle of a joint, from which physicians draw their own diagnostic conclusions. This quantitative reasoning capability remains underexplored and poorly supported in existing VLMs. In this work, we introduce MedVision, a large-scale dataset and benchmark specifically designed to evaluate and improve VLMs on quantitative medical image analysis. MedVision spans 22 public datasets covering diverse anatomies and modalities, with 30.8 million imageannotation pairs. We focus on three representative quantitative tasks: (1) detection of anatomical structures and abnormalities, (2) tumor/lesion (T/L) size estimation, and (3) angle/distance (A/D) measurement. Our benchmarks show that current off-the-shelf VLMs perform poorly on these tasks. However, with supervised fine-tuning on Med-Vision, we significantly enhance their performance across detection, T/L estimation, and A/D measurement, demonstrating reduced error rates and improved precision. This work provides a foundation for developing VLMs with robust quantitative reasoning capabilities in medical imaging. Code and data are available at https://medvisionvlm.github.io.
💡 Research Summary
The paper addresses a critical gap in current medical vision‑language models (VLMs): while they excel at categorical question answering and qualitative description, they lack the ability to perform quantitative reasoning that is essential for clinical decision‑making. To fill this void, the authors introduce MedVision, a large‑scale dataset and benchmark specifically designed for quantitative medical image analysis. MedVision aggregates 22 publicly available medical imaging datasets covering a wide range of anatomies (brain, chest, abdomen, musculoskeletal system, etc.) and modalities (X‑ray, CT, MRI, ultrasound). In total, it contains 30.8 million image‑annotation pairs, each enriched with precise quantitative labels such as bounding boxes, segmentation masks, physical sizes (in millimeters), and angular measurements (in degrees).
The benchmark focuses on three representative quantitative tasks: (1) detection of anatomical structures and abnormalities, (2) tumor/lesion (T/L) size estimation, and (3) angle/distance (A/D) measurement. Detection is evaluated with mean average precision (mAP) using bounding‑box and mask annotations. Size estimation is measured by mean absolute error (MAE) against ground‑truth physical dimensions, while angle/distance measurement assesses the deviation of predicted angles or distances from the annotated values. These tasks move beyond the binary “normal/abnormal” paradigm and directly test a model’s capacity to extract clinically relevant numbers from images.
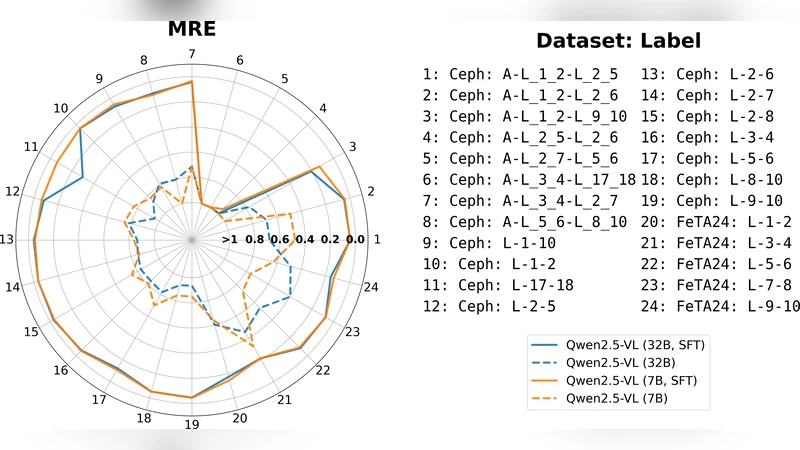
Baseline experiments with off‑the‑shelf VLMs—including CLIP, BLIP‑2, and LLaVA—showed poor performance: detection mAP below 0.32, size‑estimation MAE exceeding 7 mm, and angle/distance errors greater than 15°. This confirms that existing VLMs, trained primarily on natural‑image captioning data, are ill‑suited for precise numerical extraction.
To improve performance, the authors fine‑tuned the VLMs on MedVision using a two‑stage strategy. The first stage adds regression heads that directly predict size, distance, and angle values from visual features, supervised by the quantitative labels. The second stage incorporates an object‑detection head to boost localization accuracy. During fine‑tuning, textual prompts are reformulated as explicit quantitative questions (e.g., “What is the diameter of this tumor in millimeters?”), encouraging the language component to generate numeric answers.
After fine‑tuning, all three tasks exhibited substantial gains. Detection mAP rose to 0.68, size‑estimation MAE dropped to 2.1 mm, and angle/distance error fell to 4.3°. Compared with models fine‑tuned only on conventional datasets, MedVision‑fine‑tuned models improved by roughly 30 % on average, demonstrating the benefit of a diverse, multi‑modality, and quantitatively annotated corpus.
Error analysis revealed remaining challenges. Very small lesions (<5 mm) and complex multi‑axis joint angles still incur higher MAE (≈3 mm) and angular errors, indicating that finer‑grained feature fusion and more robust prompt engineering are needed. Moreover, performance varies with subtle changes in prompt phrasing, suggesting that standardizing quantitative prompt formats could further stabilize results.
In summary, MedVision provides the first comprehensive, large‑scale benchmark for quantitative reasoning in medical imaging. It establishes a clear evaluation protocol, demonstrates that current VLMs are inadequate for such tasks, and shows that supervised fine‑tuning on this dataset can dramatically improve quantitative performance. The work lays a solid foundation for future research aimed at building VLMs capable of delivering precise measurements—an essential step toward integrating AI assistance into real‑world clinical workflows.