📝 Original Info
- Title: LLM 기반 오프라인 환경 설계로 실시간 협동 MARL 안정성 강화
- ArXiv ID: 2511.19253
- Date: 2025-11-24
- Authors: Boyuan Wu
📝 Abstract
Cooperative multi-agent reinforcement learning (MARL) is constrained by two core design bottlenecks: dense reward engineering and curriculum design. Handcrafted rewards often misalign with global objectives, while static curricula fail to prevent agents from getting trapped in local optima. Large language models (LLMs) have been used to address some of these issues, but most work adopts an LLM-as-Agent paradigm that keeps the model in the control loop, incurring prohibitive latency and token costs for real-time systems. We propose MAESTRO (Multi-Agent Environment Shaping through Task and Reward Optimization), which shifts the LLM's role from online controller to offline training architect. MAESTRO treats training as a dual-loop optimization problem: an LLM shapes the learning environment, while a standard MARL backbone optimizes the policy. The LLM instantiates two generative components: (i) a semantic curriculum generator that synthesizes diverse, performance-conditioned traffic scenarios, and (ii) an automated reward and policy synthesizer that fills executable Python templates to produce reward shaping signals and prior policy logits. Prior policies are used only as a regularizer during actor updates (via MSE penalties that decay over training); the deployed controller is a standalone MADDPG policy with no LLM calls. Reward shaping is additively combined with environment rewards, with a difficulty-dependent weight. We evaluate MAESTRO on a 16-intersection real-world traffic network (Hangzhou) and compare three configurations: A2 (adaptive LLM curriculum with template rewards), A7 (full MAESTRO with LLM curriculum and LLM-shaped rewards), and A8 (alternative LLM curriculum with template rewards). A8 attains the highest mean return (160.23) but exhibits high variability (CV 2.95%). A7 achieves slightly lower mean return (158.87) but substantially higher stability: 2.6× lower variance than A2 (CV 0.76% vs. 1.95%) and 3.9× lower than A8, yielding a 2.3× higher risk-adjusted return (Sharpe Ratio 1.53 vs. 0.67). A7's worst seed (157.76) exceeds the baseline mean (157.04), providing strong deployment reliability. These results indicate that constrained, template-based LLM reward shaping combined with an adaptive curriculum produces robust cooperative policies suitable for real-time control. Code is available at https://github.com/BrianWu1010/MAESTRO.git.
💡 Deep Analysis
Deep Dive into LLM 기반 오프라인 환경 설계로 실시간 협동 MARL 안정성 강화.
Cooperative multi-agent reinforcement learning (MARL) is constrained by two core design bottlenecks: dense reward engineering and curriculum design. Handcrafted rewards often misalign with global objectives, while static curricula fail to prevent agents from getting trapped in local optima. Large language models (LLMs) have been used to address some of these issues, but most work adopts an LLM-as-Agent paradigm that keeps the model in the control loop, incurring prohibitive latency and token costs for real-time systems. We propose MAESTRO (Multi-Agent Environment Shaping through Task and Reward Optimization), which shifts the LLM’s role from online controller to offline training architect. MAESTRO treats training as a dual-loop optimization problem: an LLM shapes the learning environment, while a standard MARL backbone optimizes the policy. The LLM instantiates two generative components: (i) a semantic curriculum generator that synthesizes diverse, performance-conditioned traffic scena
📄 Full Content
MAESTRO: Multi-Agent Environment Shaping
through Task and Reward Optimization
Boyuan Wu∗
Department of Mechanical and Industrial Engineering
University of Toronto
Toronto, ON, Canada
Abstract
Cooperative multi-agent reinforcement learning (MARL) is constrained by two
core design bottlenecks: dense reward engineering and curriculum design. Hand-
crafted rewards often misalign with global objectives, while static curricula fail
to prevent agents from getting trapped in local optima. Large language models
(LLMs) have been used to address some of these issues, but most work adopts
an LLM-as-Agent paradigm that keeps the model in the control loop, incurring
prohibitive latency and token costs for real-time systems.
We propose MAESTRO (Multi-Agent Environment Shaping through Task and
Reward Optimization), which shifts the LLM’s role from online controller to offline
training architect. MAESTRO treats training as a dual-loop optimization problem:
an LLM shapes the learning environment, while a standard MARL backbone
optimizes the policy. The LLM instantiates two generative components: (i) a
semantic curriculum generator that synthesizes diverse, performance-conditioned
traffic scenarios, and (ii) an automated reward and policy synthesizer that fills
executable Python templates to produce reward shaping signals and prior policy
logits. Prior policies are used only as a regularizer during actor updates (via
MSE penalties that decay over training); the deployed controller is a standalone
MADDPG policy with no LLM calls. Reward shaping is additively combined with
environment rewards, with a difficulty-dependent weight.
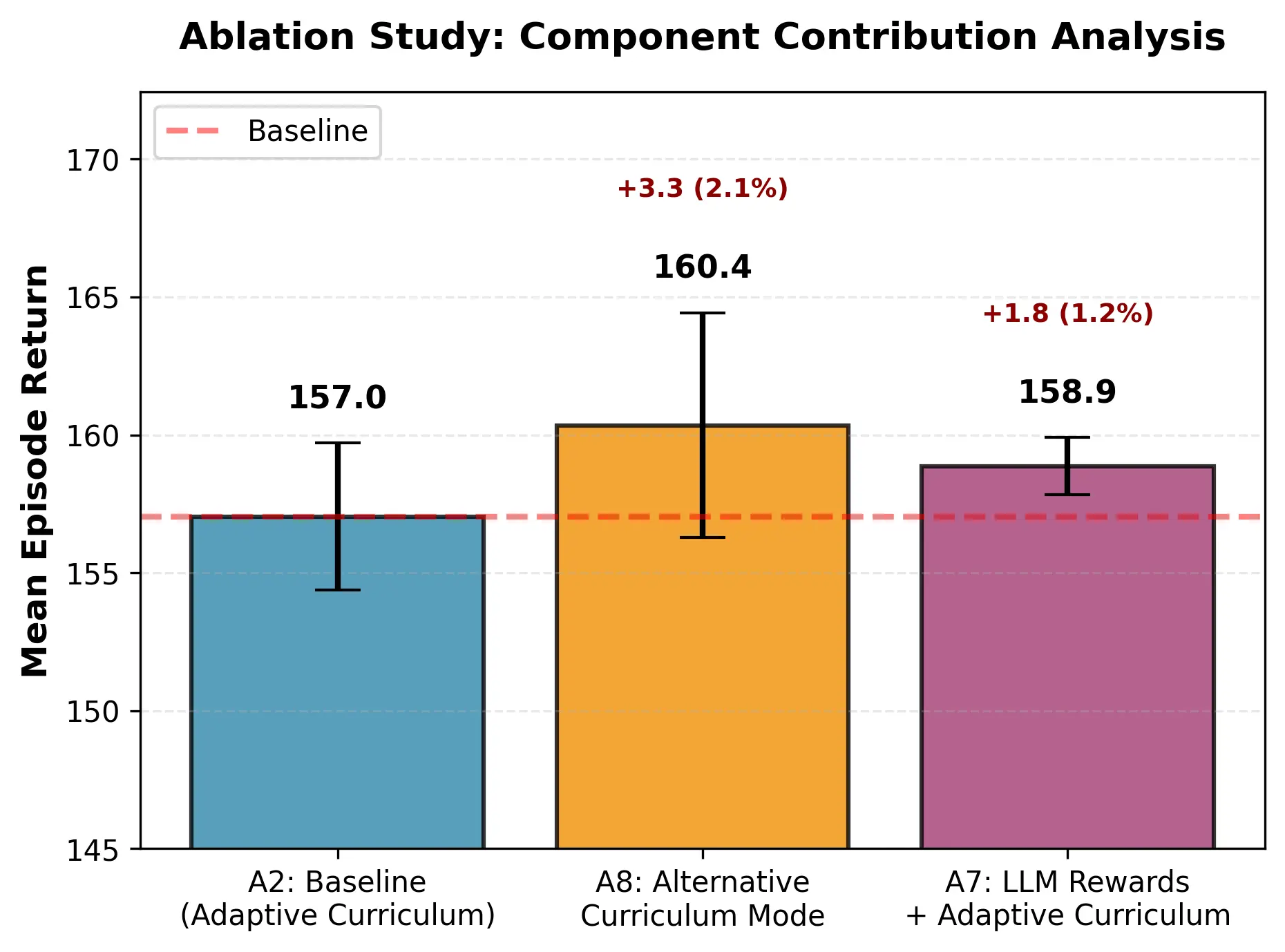
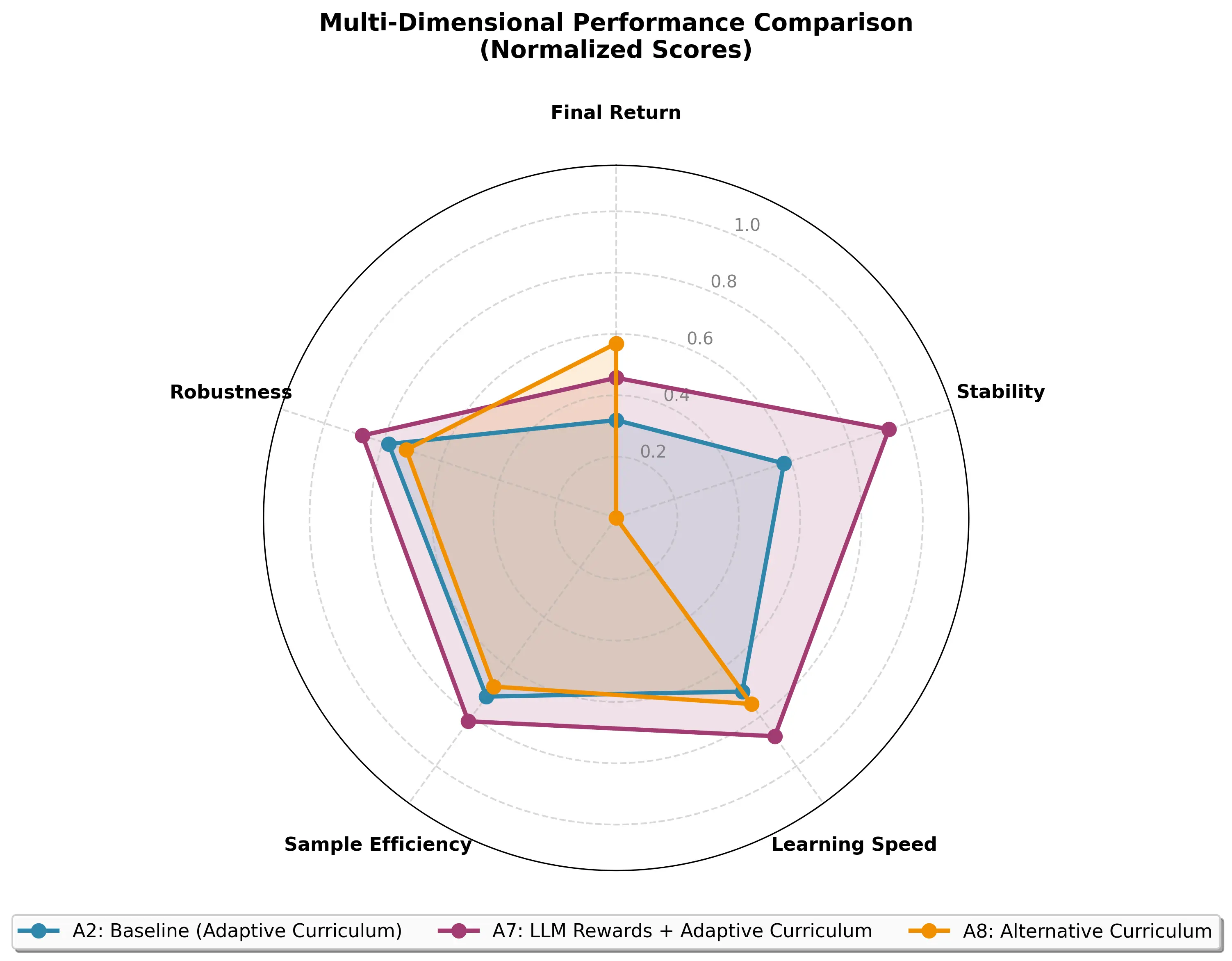
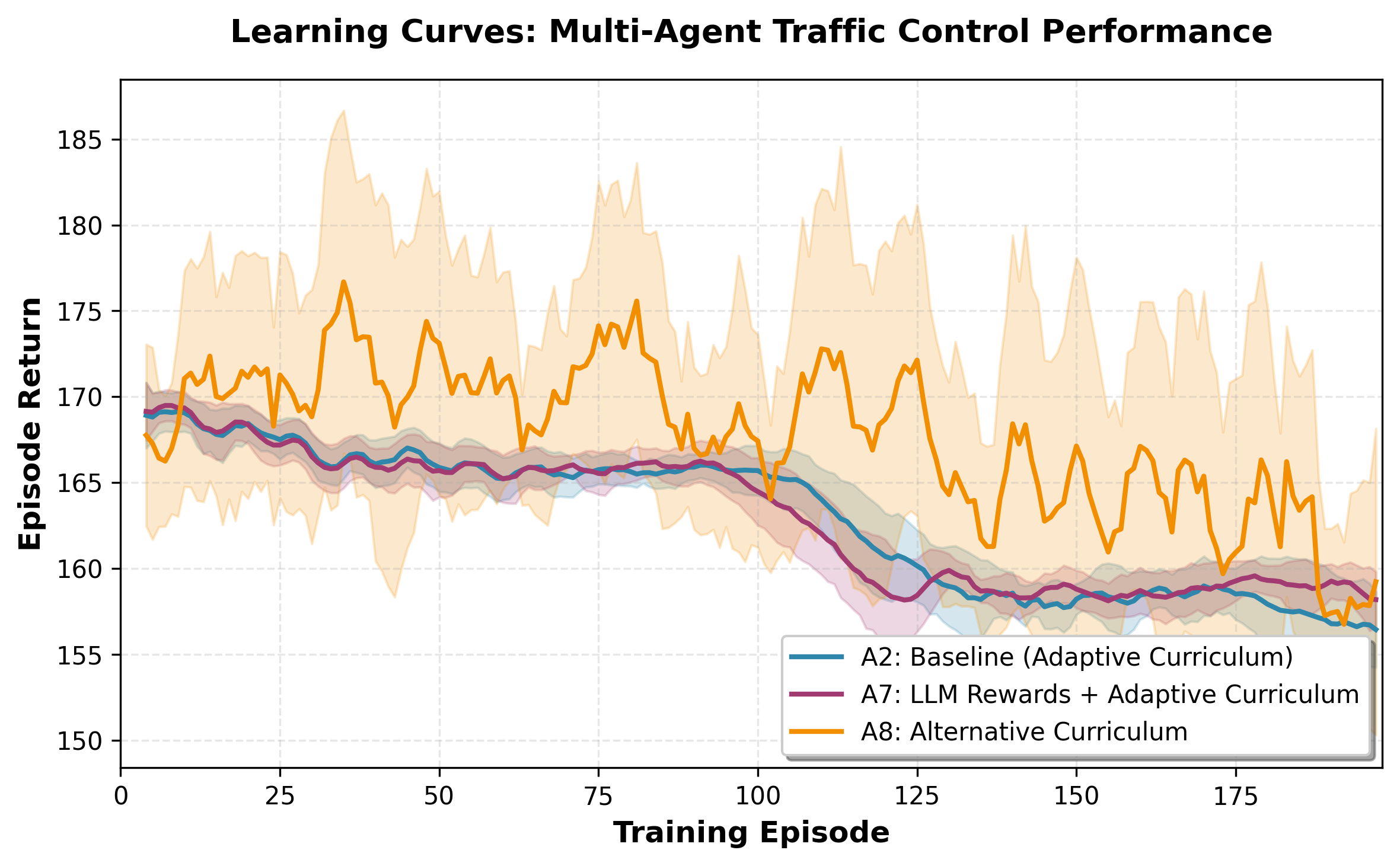
We evaluate MAESTRO on a 16-intersection real-world traffic network (Hangzhou)
and compare three configurations: A2 (adaptive LLM curriculum with template
rewards), A7 (full MAESTRO with LLM curriculum and LLM-shaped rewards),
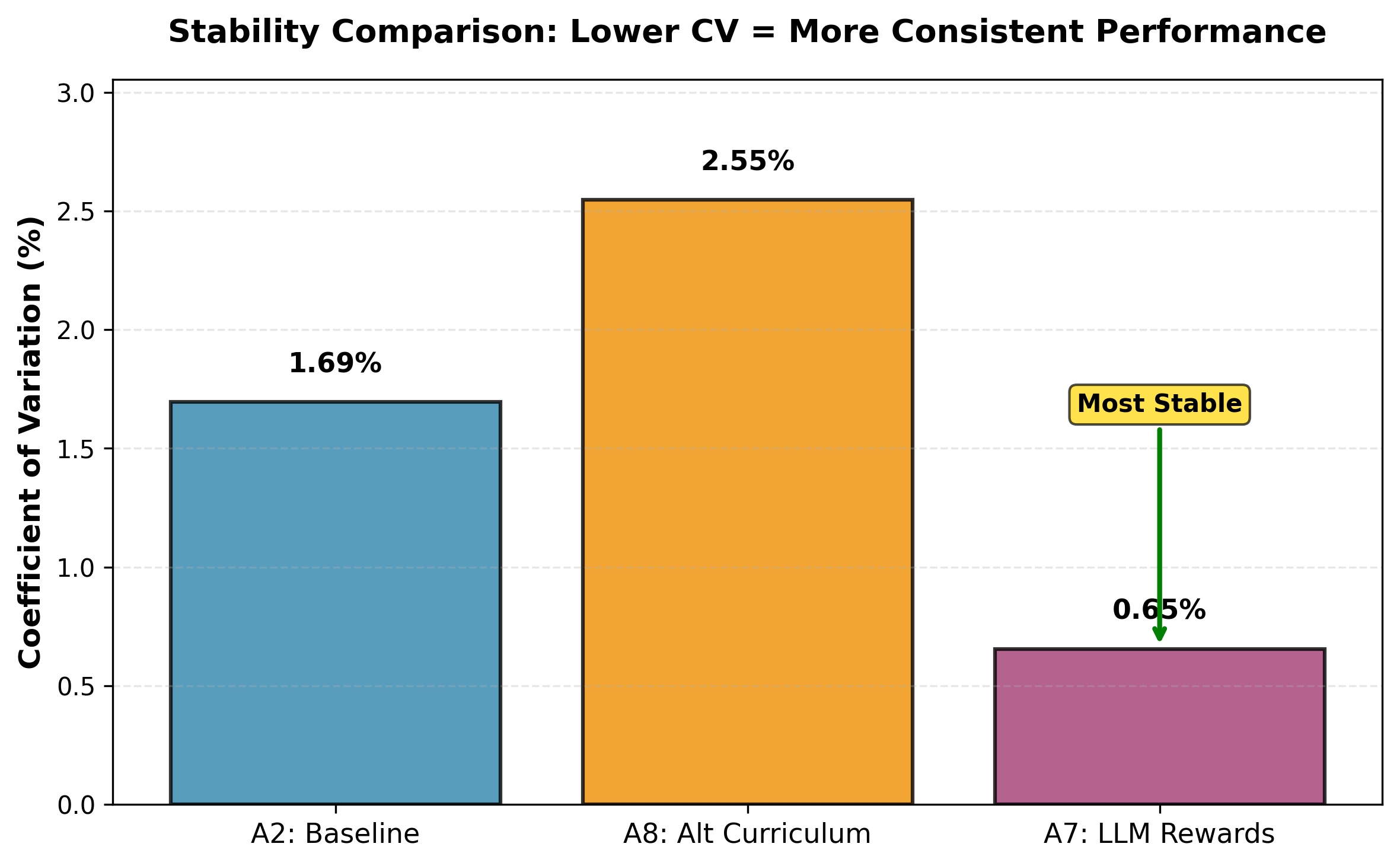
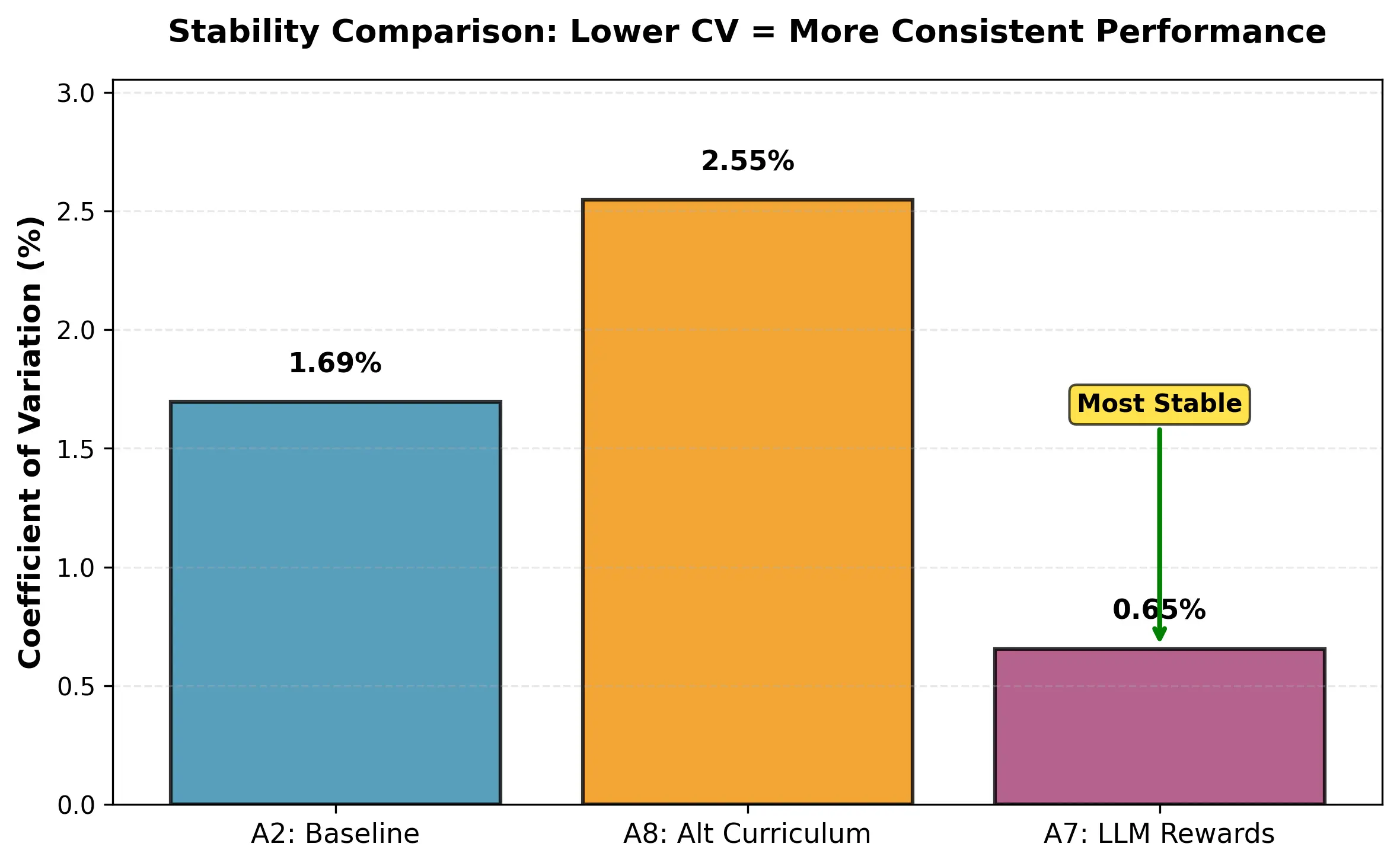
and A8 (alternative LLM curriculum with template rewards). A8 attains the highest
mean return (160.23) but exhibits high variability (CV 2.95%). A7 achieves slightly
lower mean return (158.87) but substantially higher stability: 2.6× lower variance
than A2 (CV 0.76% vs. 1.95%) and 3.9× lower than A8, yielding a 2.3× higher
risk-adjusted return (Sharpe Ratio 1.53 vs. 0.67). A7’s worst seed (157.76) exceeds
the baseline mean (157.04), providing strong deployment reliability. These results
indicate that constrained, template-based LLM reward shaping combined with an
adaptive curriculum produces robust cooperative policies suitable for real-time
control.
Code is available at https://github.com/BrianWu1010/MAESTRO.git.
1
Introduction
Cooperative multi-agent reinforcement learning (MARL) is a natural framework for decentralized
control problems such as warehouse logistics, sensor networks, and urban traffic signal control (TSC).
∗Email: boyuan.wu@mail.utoronto.ca
Preprint.
arXiv:2511.19253v2 [cs.LG] 10 Dec 2025
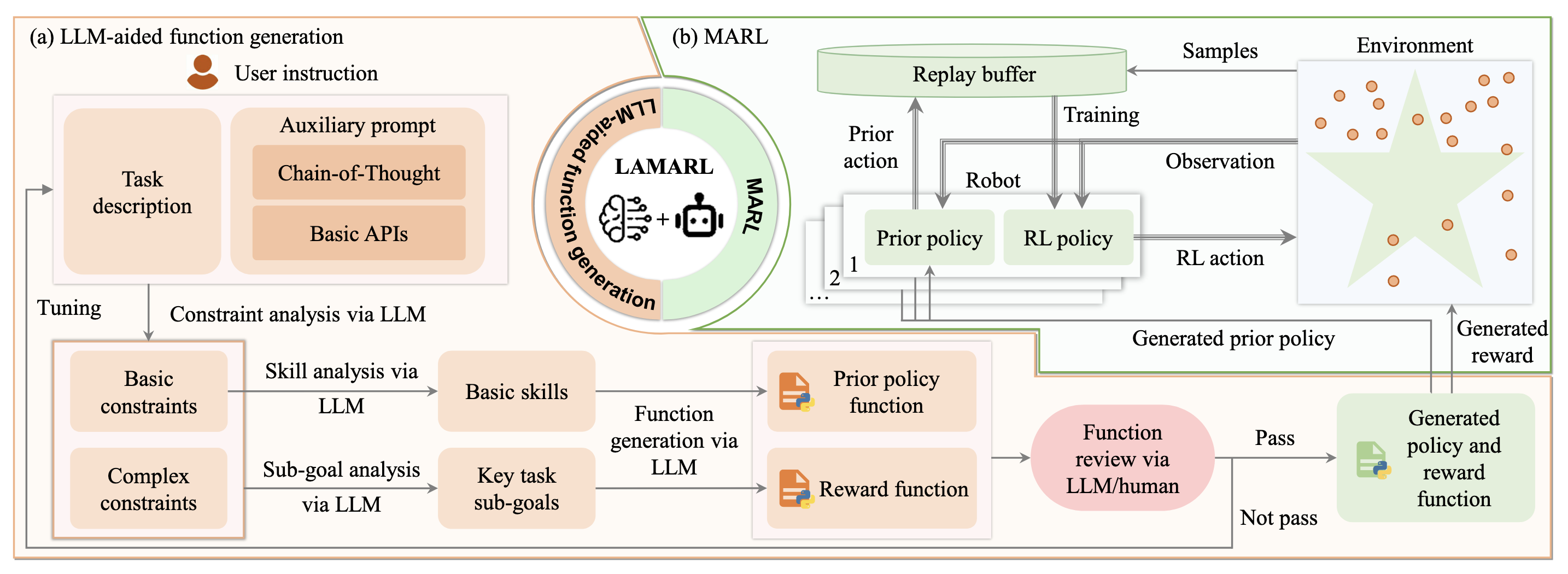
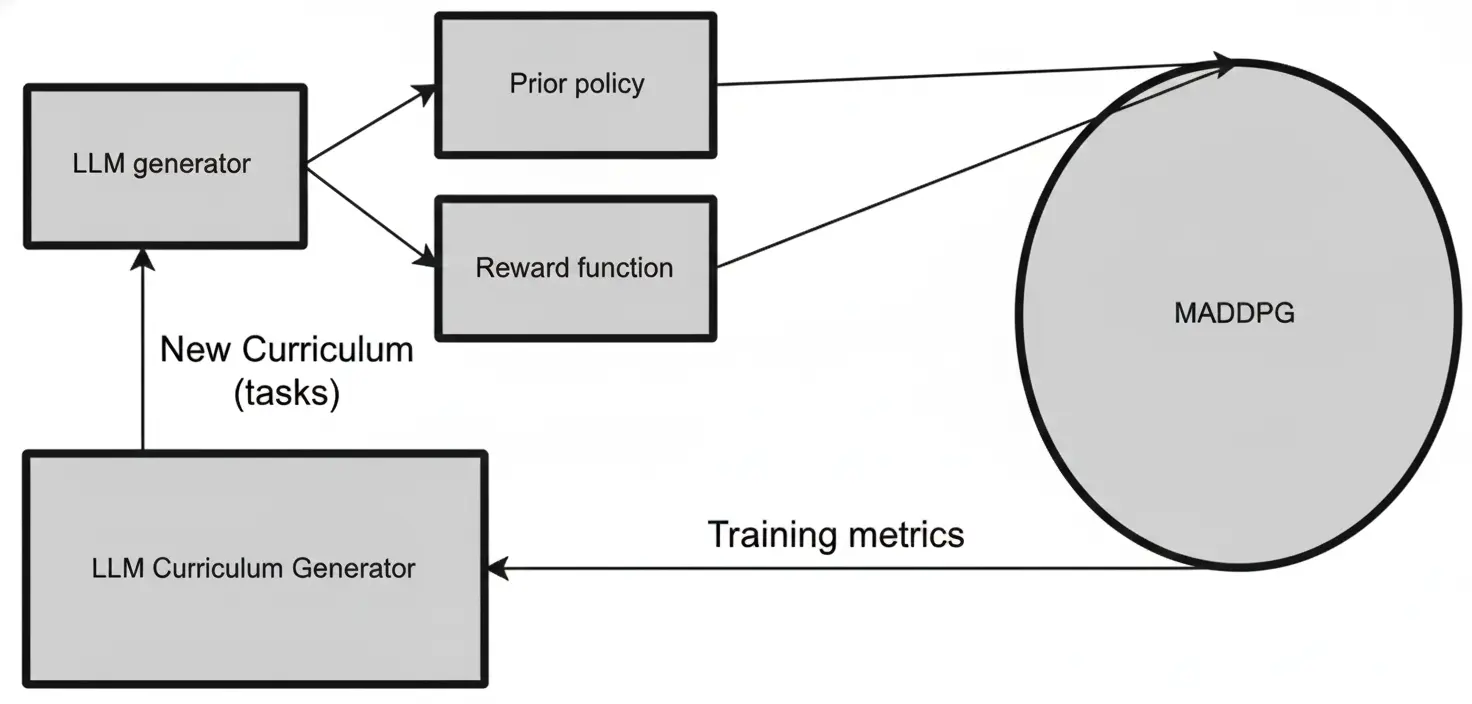
Figure 1: MAESTRO workflow. The LLM (Architect) generates curriculum contexts and parameter-
izes executable templates for reward shaping and prior policy logits. MARL agents (Learners) train
under this shaped environment using MADDPG. Performance feedback drives curriculum updates
and, in A7, periodic regeneration of reward and policy templates. LLM calls occur only during
training, not deployment.
In principle, centralized training with decentralized execution allows agents to coordinate via learned
policies while acting on local observations. In practice, scaling MARL to realistic, non-stationary
environments remains difficult due to two persistent design challenges: curriculum design and reward
engineering.
Curriculum learning (CL) addresses exploration by exposing agents to gradually harder tasks. How-
ever, effective curricula require domain knowledge to ensure that tasks are both diverse and aligned
with the target deployment regime [1]. Reward design is equally critical: dense rewards may mis-
specify long-term objectives [2], while sparse global rewards provide weak learning signals. Crafting
rewards that generalize across dynamic regimes is labor-intensive and brittle.
LLMs offer rich semantic priors that could automate both curricula and rewards. Yet most existing
integrations follow an LLM-as-Agent paradigm: the LLM directly selects actions or high-level
decisions in the control loop [3–5]. This can yield strong zero-shot behavior but incurs high latency
and token costs, limiting its applicability to real-time, safety-critical systems. It also underuses the
LLM’s strength as a high-level designer.
Our approach: LLM-as-Architect.
We propose MAESTRO (Multi-Agent Environment Shaping
through Task and Reward Optimization), which repositions the LLM as an offline architect of the
training process. Rather than emitting actions, the LLM designs the training environment: it generates
curriculum contexts and fills parameterized templates for reward shaping and prior policy logits. A
standard MADDPG backbone then optimizes a policy under this shaped environment and reward.
MAE
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.