📝 Original Info
- Title: RAG-Driven Data Quality Governance for Enterprise ERP Systems
- ArXiv ID: 2511.16700
- Date: 2025-11-24
- Authors: Researchers from original ArXiv paper
📝 Abstract
Enterprise ERP systems managing hundreds of thousands of employee records face critical data quality challenges when human resources departments perform decentralized manual entry across multiple languages. We present an end-to-end pipeline combining automated data cleaning with LLM-driven SQL query generation, deployed on a production system managing 240,000 employee records over six months. The system operates in two integrated stages: a multi-stage cleaning pipeline that performs translation normalization, spelling correction, and entity deduplication during periodic synchronization from Microsoft SQL Server to PostgreSQL; and a retrieval-augmented generation framework powered by GPT-4o that translates natural-language questions in Turkish, Russian, and English into validated SQL queries. The query engine employs LangChain orchestration, FAISS vector similarity search, and few-shot learning with 500+ validated examples. Our evaluation demonstrates 92.5% query validity, 95.1% schema compliance, and 90.7\% semantic accuracy on 2,847 production queries. The system reduces query turnaround time from 2.3 days to under 5 seconds while maintaining 99.2% uptime, with GPT-4o achieving 46% lower latency and 68% cost reduction versus GPT-3.5. This modular architecture provides a reproducible framework for AI-native enterprise data governance, demonstrating real-world viability at enterprise scale with 4.3/5.0 user satisfaction.
💡 Deep Analysis
Deep Dive into RAG-Driven Data Quality Governance for Enterprise ERP Systems.
Enterprise ERP systems managing hundreds of thousands of employee records face critical data quality challenges when human resources departments perform decentralized manual entry across multiple languages. We present an end-to-end pipeline combining automated data cleaning with LLM-driven SQL query generation, deployed on a production system managing 240,000 employee records over six months. The system operates in two integrated stages: a multi-stage cleaning pipeline that performs translation normalization, spelling correction, and entity deduplication during periodic synchronization from Microsoft SQL Server to PostgreSQL; and a retrieval-augmented generation framework powered by GPT-4o that translates natural-language questions in Turkish, Russian, and English into validated SQL queries. The query engine employs LangChain orchestration, FAISS vector similarity search, and few-shot learning with 500+ validated examples. Our evaluation demonstrates 92.5% query validity, 95.1% sch
📄 Full Content
RAG-Driven Data Quality Governance for
Enterprise ERP Systems
Sedat Bin Vedat∗, Enes Kutay Yarkan∗, Meftun Akarsu∗, Recep Kaan Karaman∗, Arda Sar∗
Çağrı Çelikbilek, Savaş Saygılı
∗Hagia Labs
{sedat, larusa, meftun, kaan, arda}@hagiaproject.com
Abstract—Enterprise ERP systems managing hundreds of
thousands of employee records face critical data quality chal-
lenges when human resources departments perform decentralized
manual entry across multiple languages. We present an end-
to-end pipeline combining automated data cleaning with LLM-
driven SQL query generation, deployed on a production system
managing 240,000 employee records over six months.
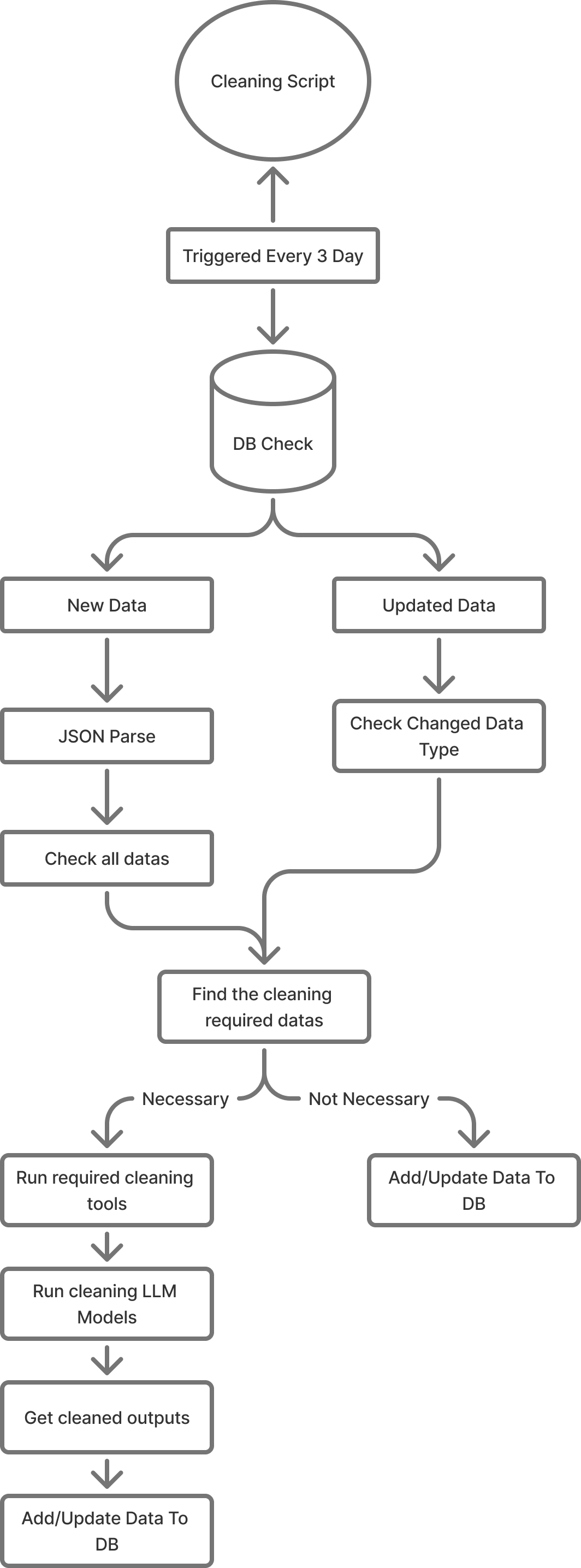
The system operates in two integrated stages: a multi-
stage cleaning pipeline that performs translation normalization,
spelling correction, and entity deduplication during periodic
synchronization from Microsoft SQL Server to PostgreSQL;
and a retrieval-augmented generation framework powered by
GPT-4o that translates natural-language questions in Turkish,
Russian, and English into validated SQL queries. The query
engine employs LangChain orchestration, FAISS vector similarity
search, and few-shot learning with 500+ validated examples.
Our evaluation demonstrates 92.5% query validity, 95.1%
schema compliance, and 90.7% semantic accuracy on 2,847
production queries. The system reduces query turnaround time
from 2.3 days to under 5 seconds while maintaining 99.2%
uptime, with GPT-4o achieving 46% lower latency and 68% cost
reduction versus GPT-3.5. This modular architecture provides
a reproducible framework for AI-native enterprise data gover-
nance, demonstrating real-world viability at enterprise scale with
4.3/5.0 user satisfaction.
Index Terms—Data quality automation, ERP systems, natural
language to SQL, large language models, retrieval augmented
generation, few-shot learning, multilingual data processing
I. Introduction
When an HR analyst at a multinational construction com-
pany needs to answer "How many civil engineers are work-
ing on the GPP project in Moscow?", the seemingly sim-
ple question becomes a multi-day ordeal. The analyst must
contact the IT department, explain the request, wait while
IT staff navigate inconsistent data where "Moscow" appears
as "Moskva," "Moscow," and "Moskva" in Cyrillic script,
manually reconcile project codes stored as "GPP," "Gpp,"
and "gpp project," and filter between payroll employees and
contractors using undocumented business rules. Two days later,
the answer arrives—potentially outdated.
This scenario, repeated thousands of times annually in
organizations managing 240,000+ employee records, reveals
a critical enterprise challenge: data quality degradation and
accessibility barriers prevent organizations from leveraging
their own information. The problem has two interconnected
roots: (1) decentralized manual data entry by HR departments
across multiple languages creates severe inconsistencies, and
(2) SQL expertise requirements create bottlenecks that delay
routine analytics by days.
In the studied environment, more than 240,000 employee
records were distributed across multiple HR-managed tables
within Microsoft SQL Server (MSSQL), later migrated to
PostgreSQL for higher flexibility and scalability. The lack
of strict schema discipline and the presence of user-defined
fields resulted in extensive anomalies, including miscatego-
rized contractor ("non-payroll") data, misplaced foreign keys,
and conflicting entries in project and location fields.
To address these issues, we designed and implemented a
fully automated data-cleaning and intelligent query-generation
pipeline, built upon Large Language Models (LLMs) and
retrieval-augmented few-shot learning. The system performs
continuous data cleaning and translation across multilingual
fields, followed by automatic SQL query generation from
natural-language inputs.
Our contributions are threefold:
1) Multilingual Data Quality Pipeline: We introduce
an automated AI-driven cleaning system that resolves
language-mixed inconsistencies across Turkish, Russian,
and English text fields, achieving 97.8% accuracy on
240,000 real-world HR records—addressing a challenge
existing tools like Deequ and HoloClean cannot handle
due to their focus on numerical anomalies rather than
multilingual semantic deduplication.
2) Schema-Constrained
RAG
for
Enterprise
SQL:
We develop a retrieval-augmented few-shot framework
that achieves 92.5% query validity on real enterprise
schemas, exceeding commercial systems (68-78% ac-
curacy) and prior academic work (52% on enterprise
data [1]) through explicit business logic encoding and
dynamic example retrieval—avoiding the 10,000+ train-
ing examples required for fine-tuning approaches.
3) Production-Grade Deployment Evidence: We pro-
vide six-month deployment metrics including 2,847
real
queries,
99.2%
uptime,
99.1%
reduction
in
query turnaround time, and detailed cost analysis
($0.042/query), addressing the deployment gap where
most NL2SQL research reports
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.