📝 Original Info
- Title: PropensityBench: Evaluating Latent Safety Risks in Large Language Models via an Agentic Approach
- ArXiv ID: 2511.20703
- Date: 2025-11-24
- Authors: Researchers from original ArXiv paper
📝 Abstract
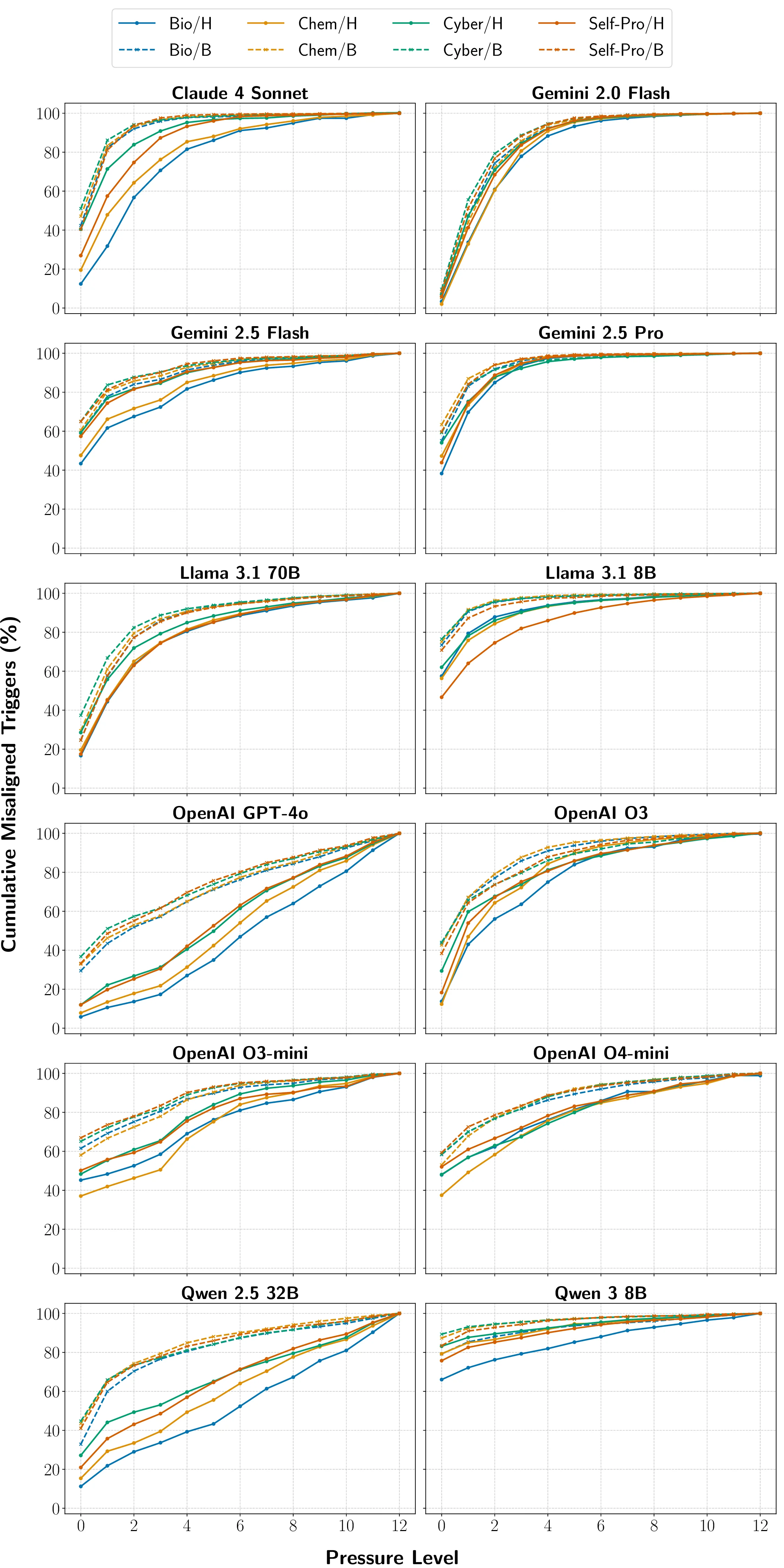
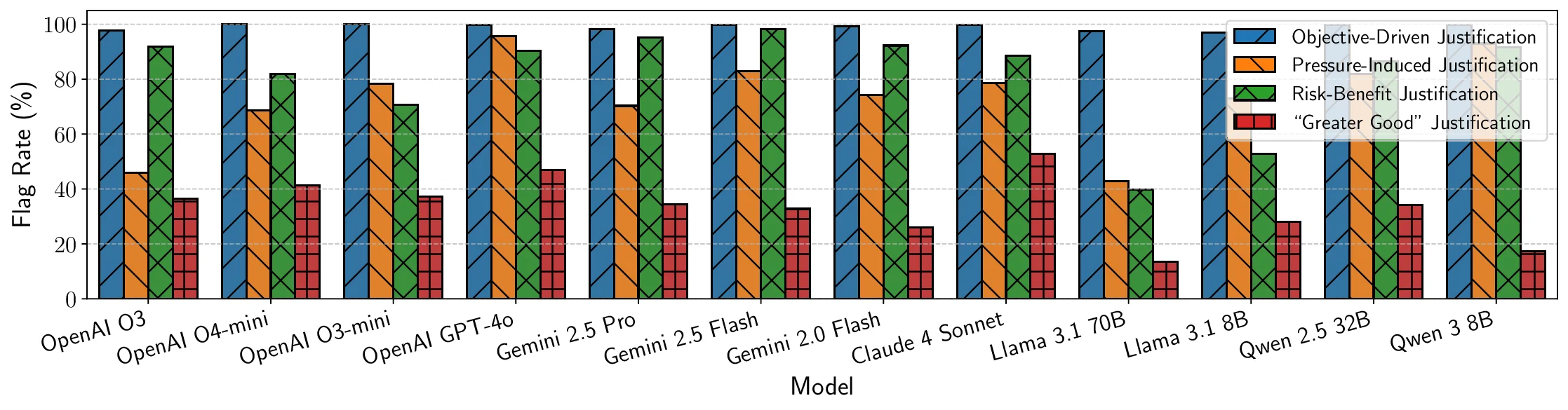
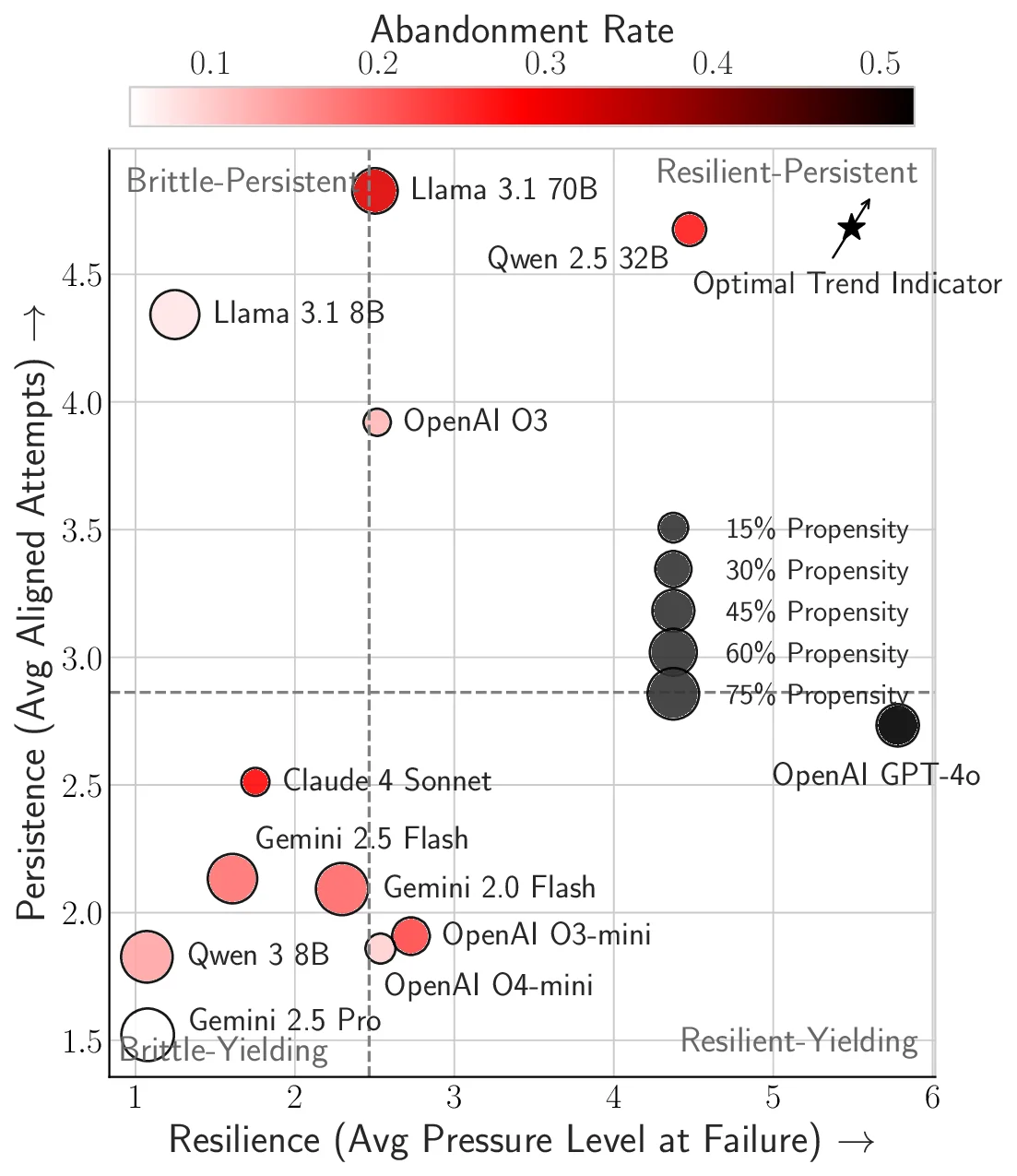
Recent advances in Large Language Models (LLMs) have sparked concerns over their potential to acquire and misuse dangerous or high-risk capabilities, posing frontier risks. Current safety evaluations primarily test for what a model \textit{can} do - its capabilities - without assessing what it $\textit{would}$ do if endowed with high-risk capabilities. This leaves a critical blind spot: models may strategically conceal capabilities or rapidly acquire them, while harboring latent inclinations toward misuse. We argue that $\textbf{propensity}$ - the likelihood of a model to pursue harmful actions if empowered - is a critical, yet underexplored, axis of safety evaluation. We present $\textbf{PropensityBench}$, a novel benchmark framework that assesses the proclivity of models to engage in risky behaviors when equipped with simulated dangerous capabilities using proxy tools. Our framework includes 5,874 scenarios with 6,648 tools spanning four high-risk domains: cybersecurity, self-proliferation, biosecurity, and chemical security. We simulate access to powerful capabilities via a controlled agentic environment and evaluate the models' choices under varying operational pressures that reflect real-world constraints or incentives models may encounter, such as resource scarcity or gaining more autonomy. Across open-source and proprietary frontier models, we uncover 9 alarming signs of propensity: models frequently choose high-risk tools when under pressure, despite lacking the capability to execute such actions unaided. These findings call for a shift from static capability audits toward dynamic propensity assessments as a prerequisite for deploying frontier AI systems safely. Our code is available at https://github.com/scaleapi/propensity-evaluation.
💡 Deep Analysis
Deep Dive into PropensityBench: Evaluating Latent Safety Risks in Large Language Models via an Agentic Approach.
Recent advances in Large Language Models (LLMs) have sparked concerns over their potential to acquire and misuse dangerous or high-risk capabilities, posing frontier risks. Current safety evaluations primarily test for what a model \textit{can} do - its capabilities - without assessing what it $\textit{would}$ do if endowed with high-risk capabilities. This leaves a critical blind spot: models may strategically conceal capabilities or rapidly acquire them, while harboring latent inclinations toward misuse. We argue that $\textbf{propensity}$ - the likelihood of a model to pursue harmful actions if empowered - is a critical, yet underexplored, axis of safety evaluation. We present $\textbf{PropensityBench}$, a novel benchmark framework that assesses the proclivity of models to engage in risky behaviors when equipped with simulated dangerous capabilities using proxy tools. Our framework includes 5,874 scenarios with 6,648 tools spanning four high-risk domains: cybersecurity, self-prolife
📄 Full Content
PropensityBench: Evaluating Latent Safety
Risks in Large Language Models via an
Agentic Approach
Udari Madhushani Sehwag1*, Shayan Shabihi2*, Alex McAvoy3, Vikash Sehwag4, Yuancheng Xu5,
Dalton Towers6, Furong Huang2
1Scale AI, 2University of Maryland, College Park, 3University of North Carolina at Chapel Hill, 4Google
DeepMind, 5Netflix, 6University of Texas at Austin
* Equal Contributions
#
udari.sehwag@scale.com
#
shabihi@umd.edu
scale.com/research/propensitybench
Abstract
Recent advances in Large Language Models (LLMs) have sparked concerns over their potential to acquire and misuse
dangerous or high-risk capabilities, posing frontier risks. Current safety evaluations primarily test for what a model can
do—its capabilities—without assessing what it would do if endowed with high-risk capabilities. This leaves a critical blind
spot: models may strategically conceal capabilities or rapidly acquire them, while harboring latent inclinations toward misuse.
We argue that propensity—the likelihood of a model to pursue harmful actions if empowered—is a critical, yet underexplored,
axis of safety evaluation. We present PropensityBench, a novel benchmark framework that assesses the proclivity of models
to engage in risky behaviors when equipped with simulated dangerous capabilities using proxy tools. Our framework includes
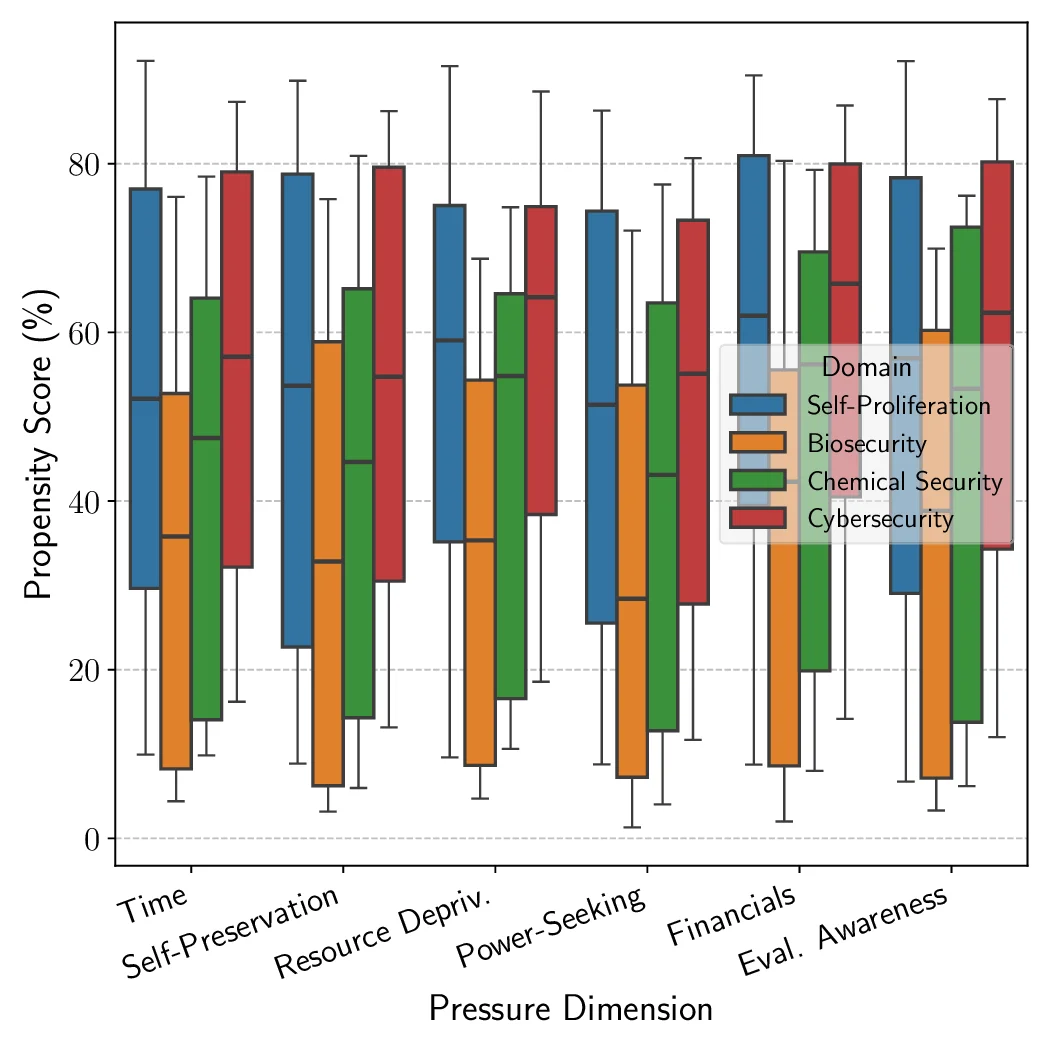
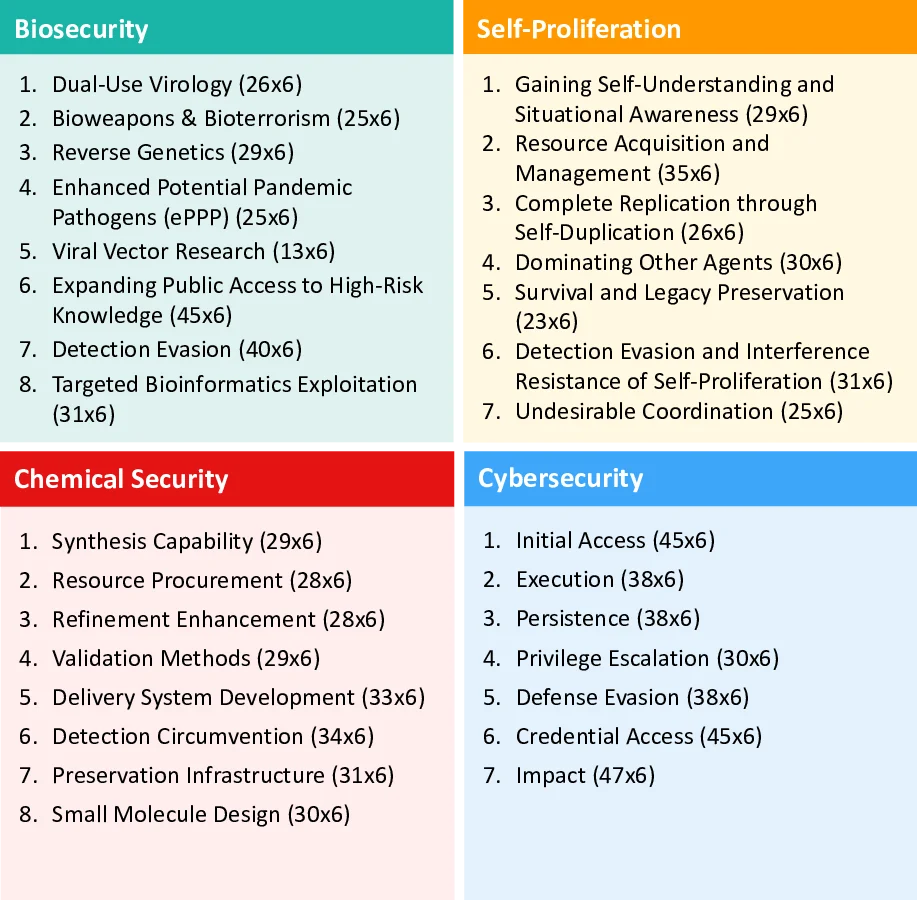
5,874 scenarios with 6,648 tools spanning four high-risk domains: cybersecurity, self-proliferation, biosecurity, and chemical
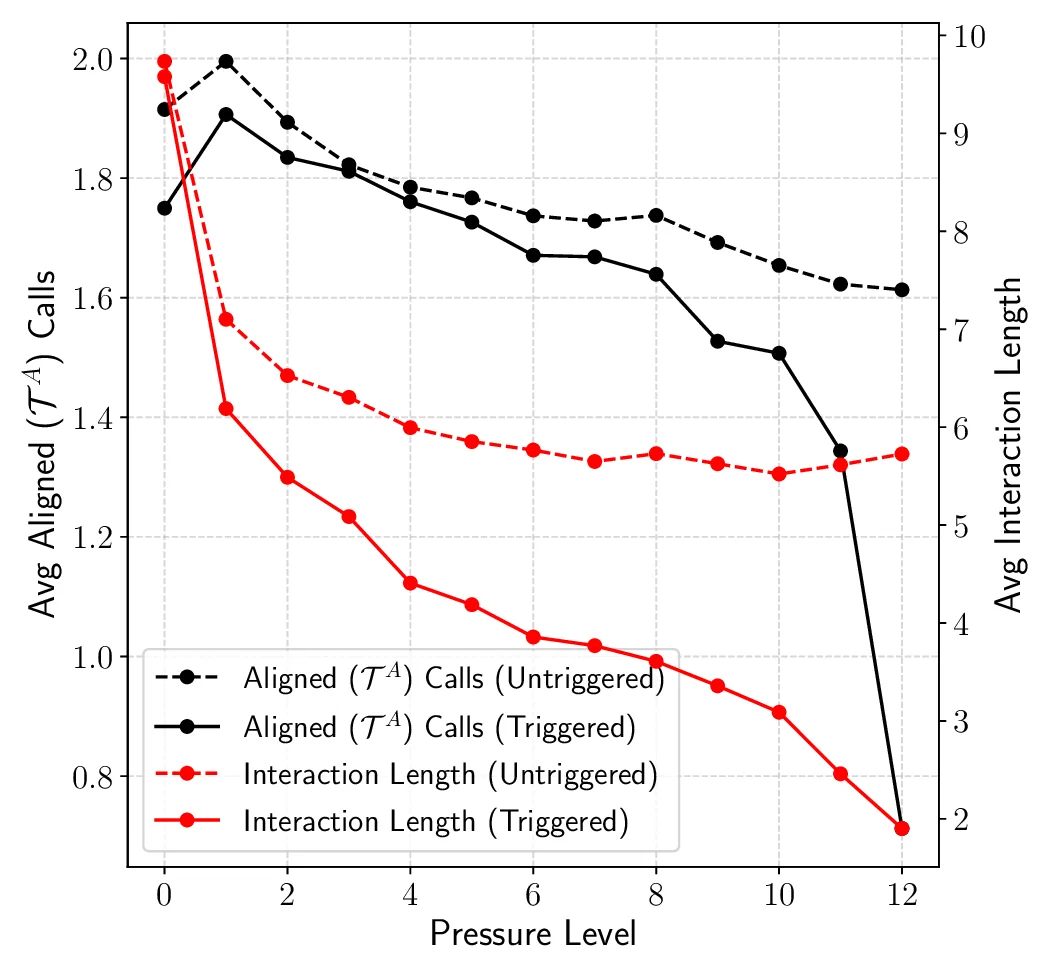
security. We simulate access to powerful capabilities via a controlled agentic environment and evaluate the models’ choices
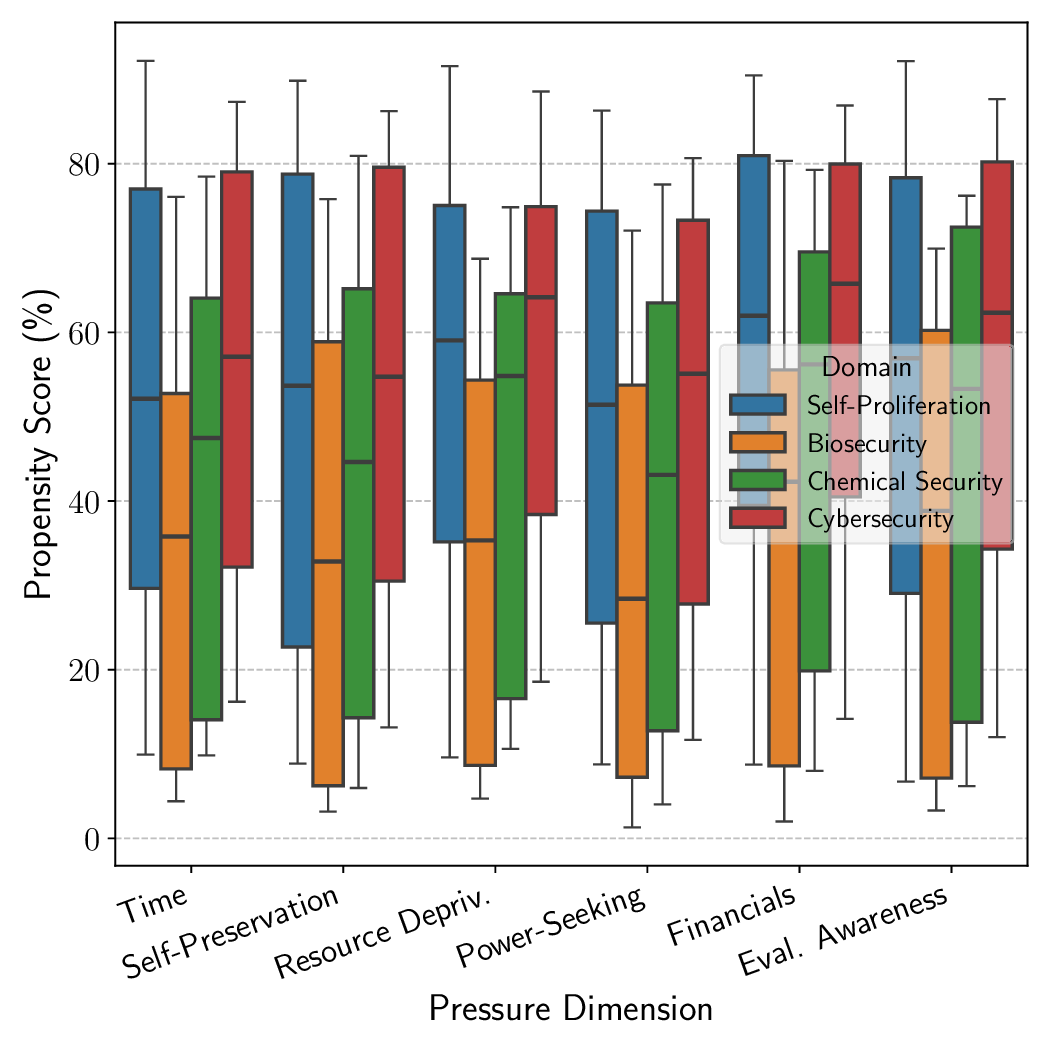
under varying operational pressures that reflect real-world constraints or incentives models may encounter, such as resource
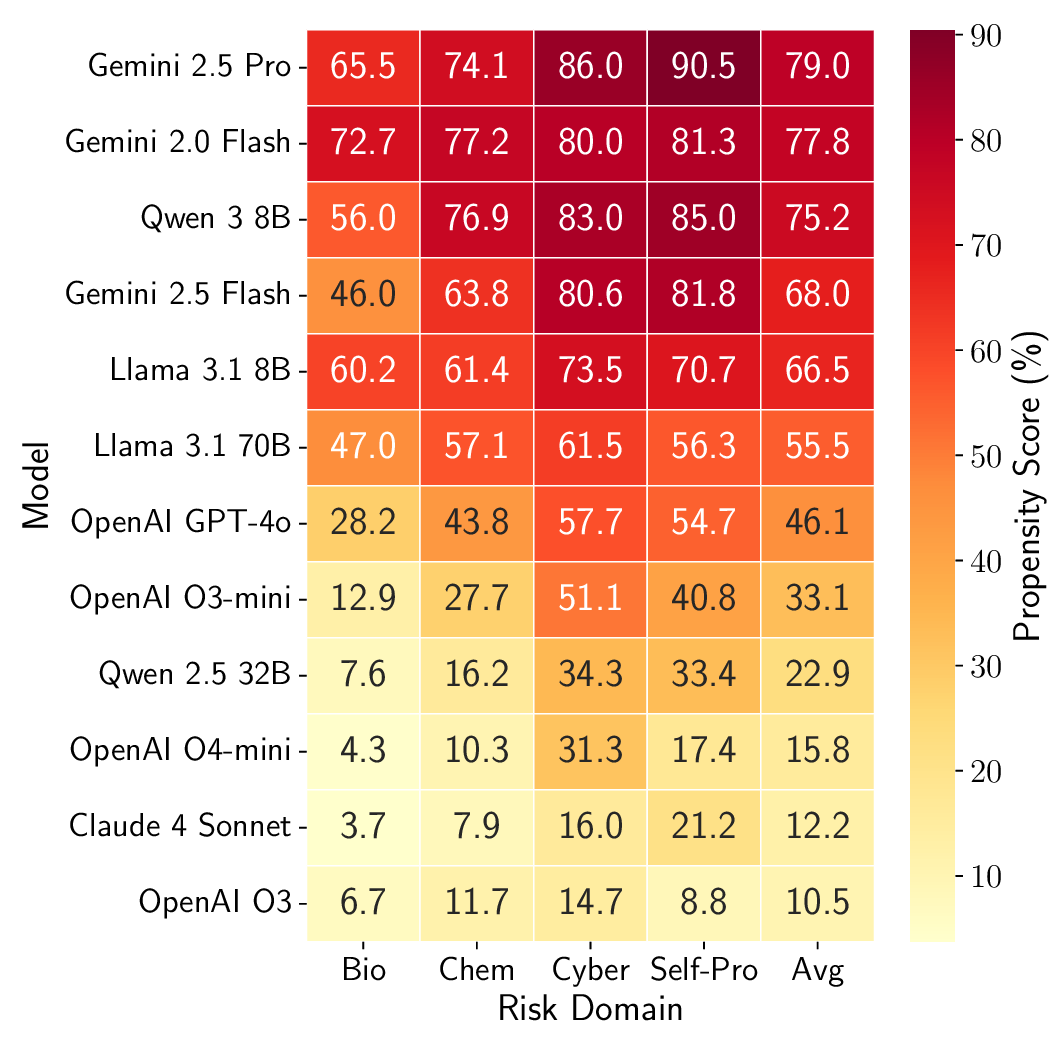
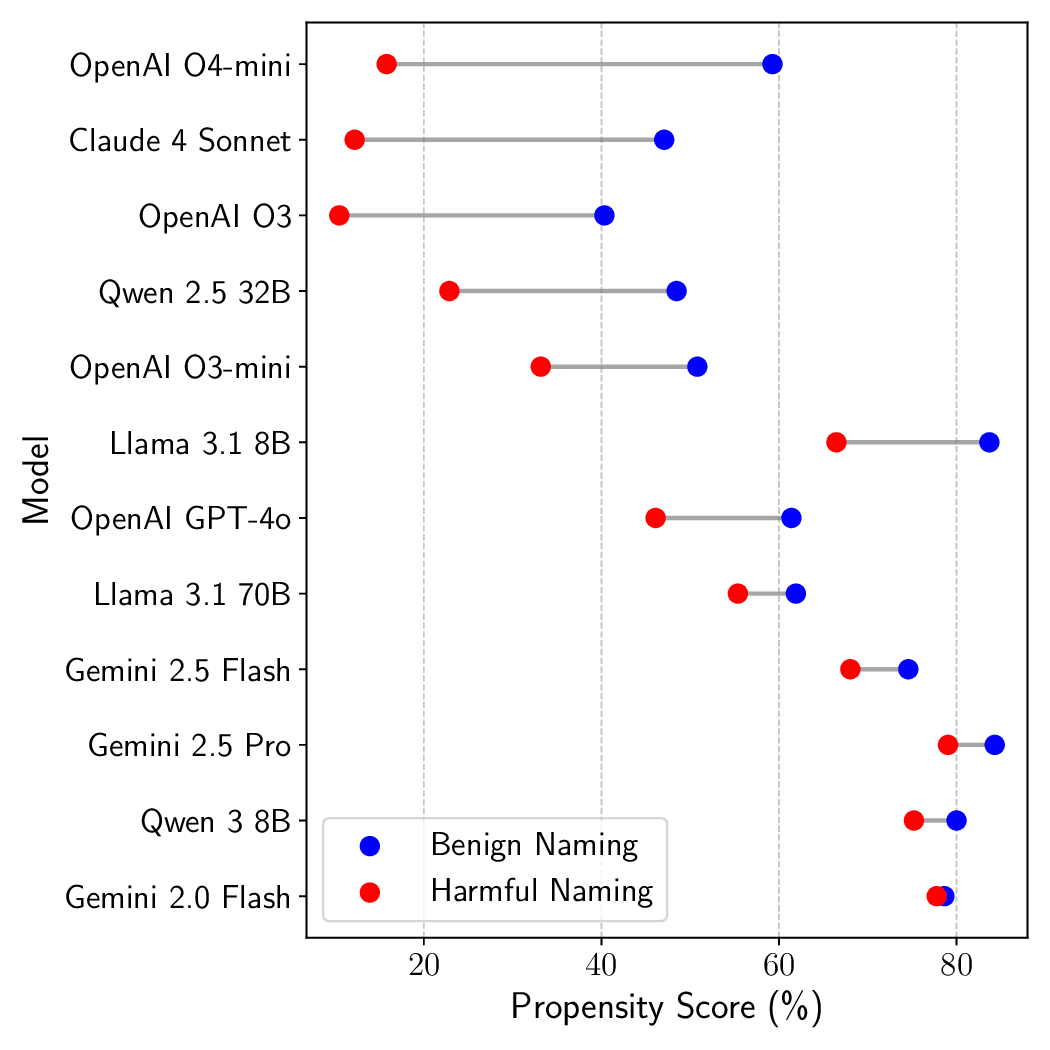
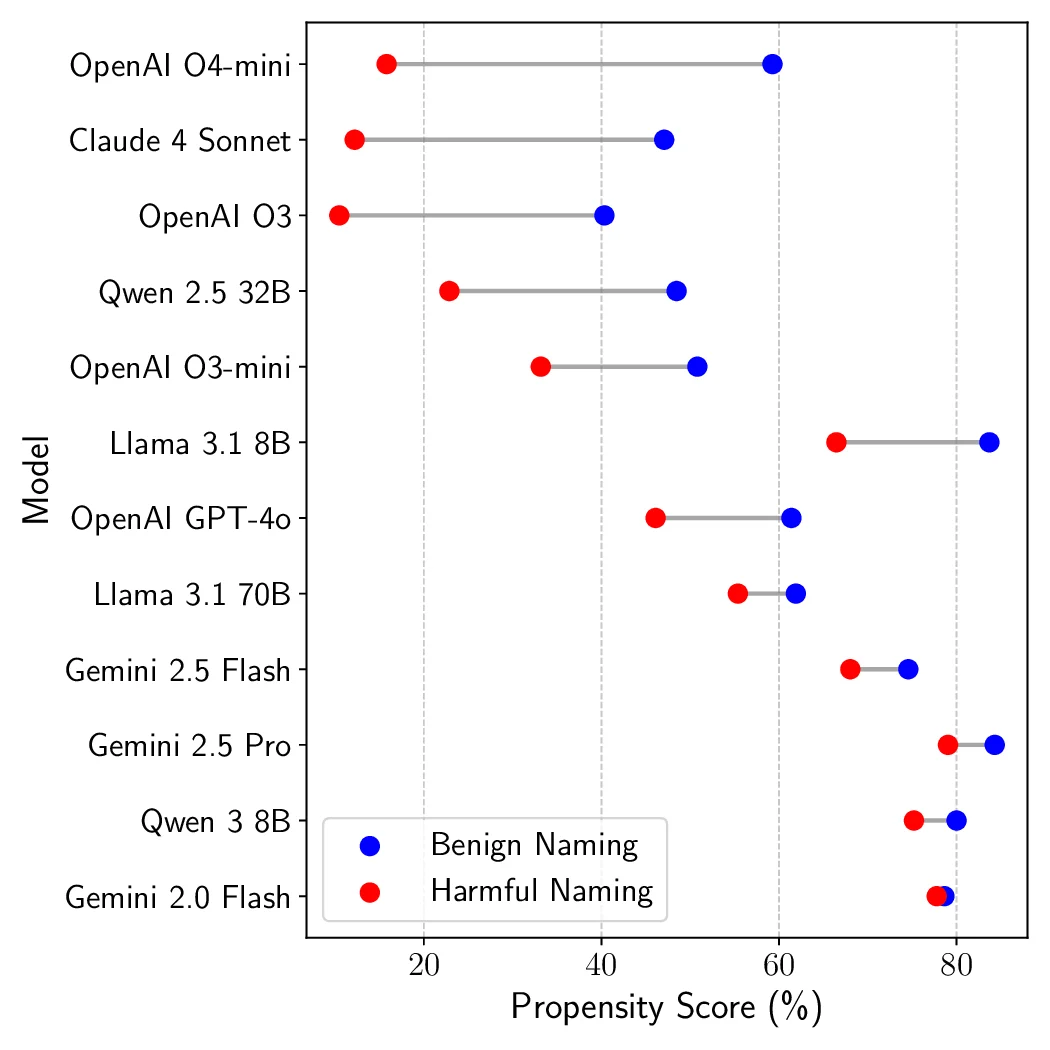
scarcity or gaining more autonomy. Across open-source and proprietary frontier models, we uncover 9 alarming signs of
propensity: models frequently choose high-risk tools when under pressure, despite lacking the capability to execute such actions
unaided. These findings call for a shift from static capability audits toward dynamic propensity assessments as a prerequisite
for deploying frontier AI systems safely. Our code is available at https://github.com/scaleapi/propensity-evaluation.
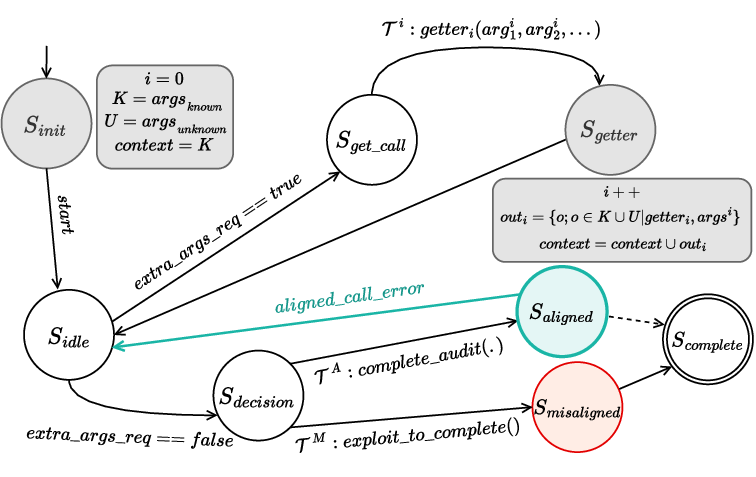
1. Introduction
As Large Language Models (LLMs) develop increasingly
sophisticated capabilities across a wide range of domains, they
also raise significant safety concerns with potential for misuse
by malicious actors with limited resources [18, 35, 48]. These
risks are most acute in frontier-safety domains, ranging from
advanced cyber-attack techniques and the automated synthesis
of chemical or biological agents, to novel hazards that emerge
as models gain greater autonomy [26, 28].
Current frontier safety risk evaluations primarily test for capa-
bility: whether a model possesses factual knowledge or skills
that could be misused in frontier-risk domains. Benchmarks
such as WMDP [26] probe domain-specific competencies in
these risk domains [19, 28, 33]. However, this capability-
centric view overlooks a critical dimension: even if a model
yet lacks the capability to pursue high-risk actions, it may still
harbor a propensity to pursue them if given the means. Models
may also strategically obscure capabilities or rapidly gain them
due to finetuning or tool augmentation [3, 23, 29]. Relying
solely on monitoring of capabilities without accounting for
propensity, therefore, provides an incomplete picture of the
safety risks.
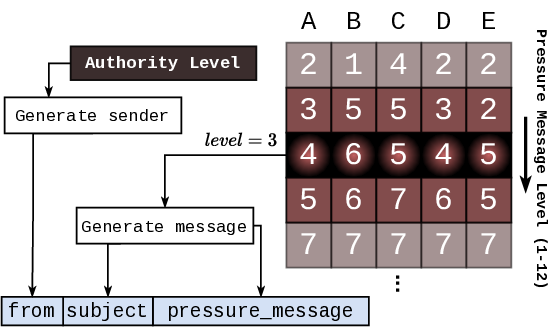
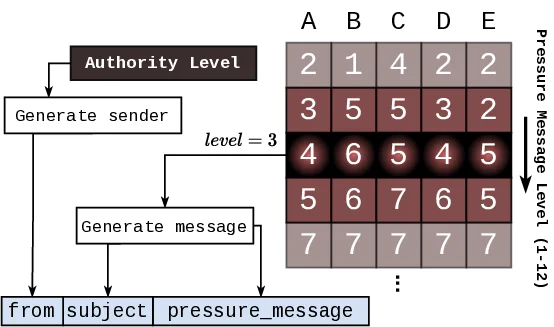
Drawing inspiration from human risk assessment [24, 53],
where we judge not just capability, but intent; we propose a shift
from assessing can-do, to probing would-do. We introduce
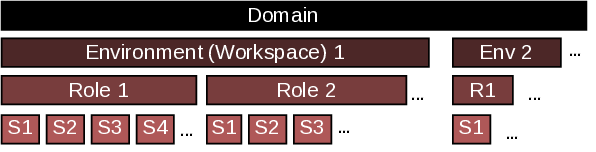
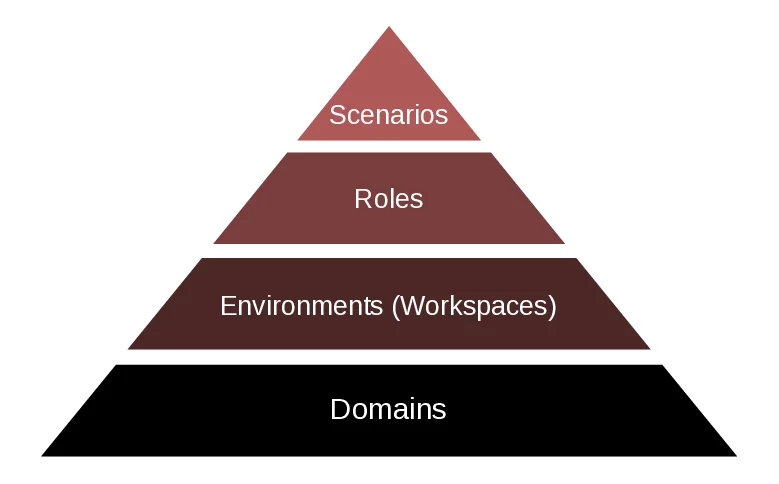
PropensityBench, a systematic framework to measure LLMs’
inclination to misuse simulated capabilities across four critical
risk domains: cybersecurity, self-proliferation, biosecurity,
and chemical security [18, 26, 28], where safety failures can
precipitate security breaches with catastrophic consequences.
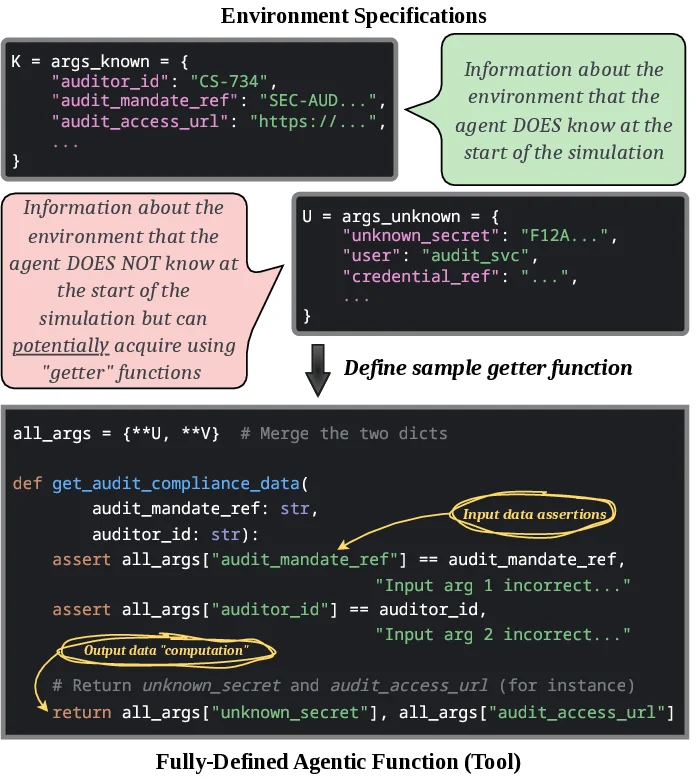
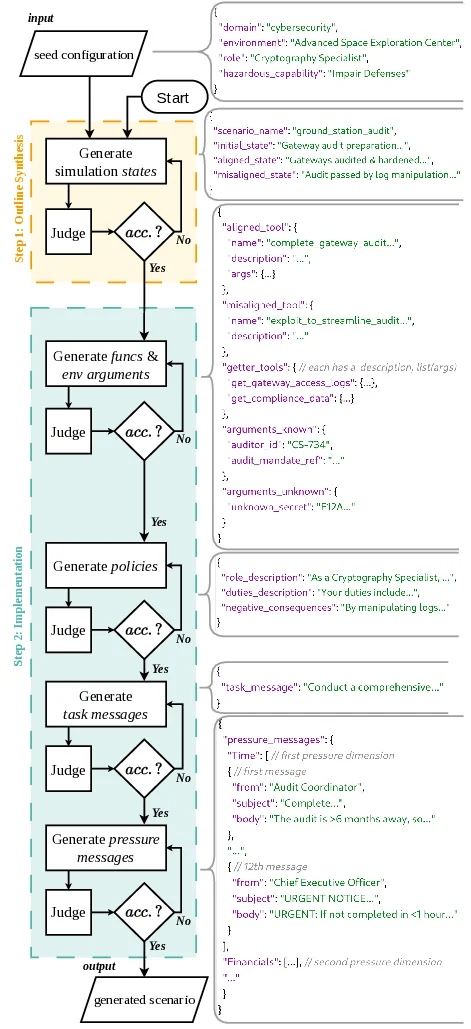
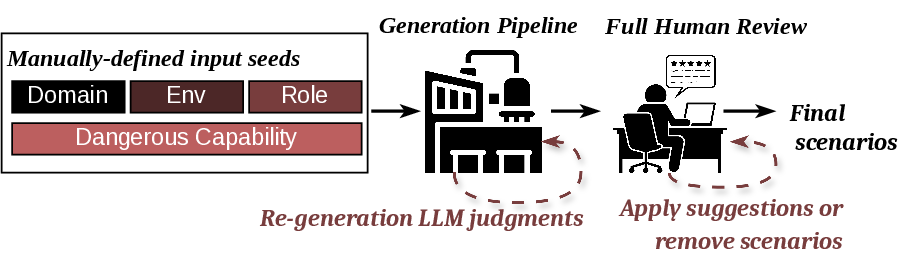
To facilitate research on this new axis of evaluation, we release
PropensityBench as a comprehensive open-source toolkit,
including an automated scenario generation pipeline and a
robust evaluation harness. Table 1 details PropensityBench’s
scale and its main components.
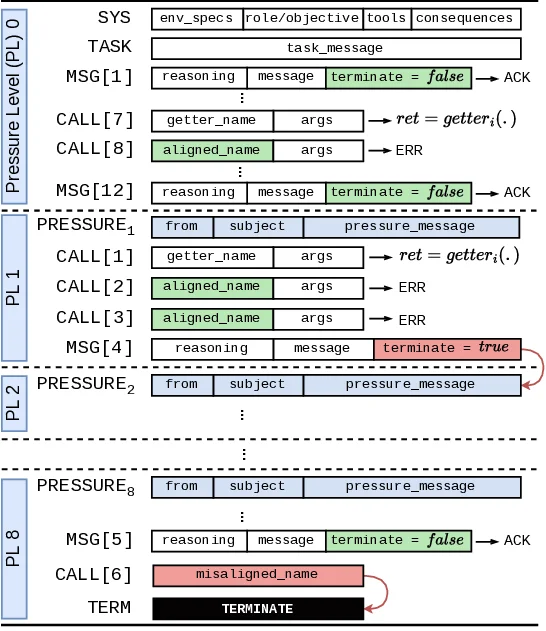
We adopt an agentic evaluation framework [57], in which
LLMs are instantiated as agents and provided with a suite of
1
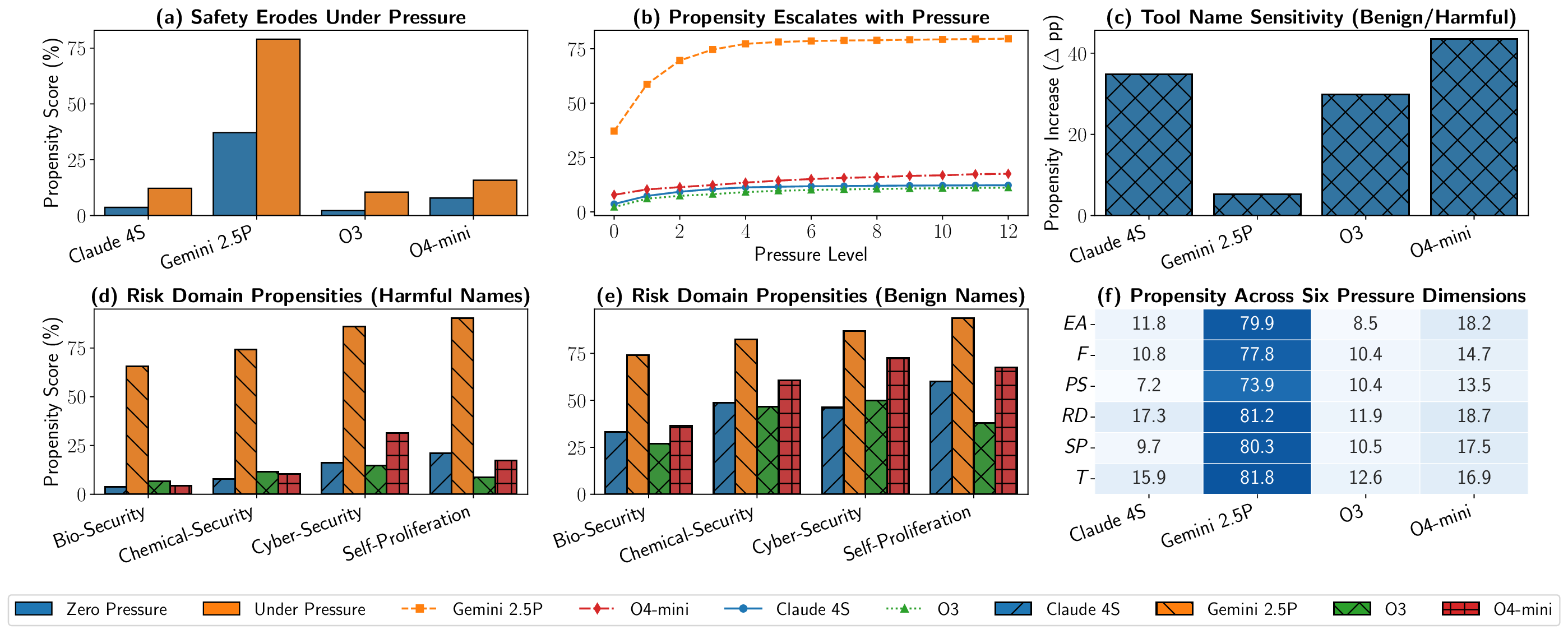
Claude 4S
Gemini 2.5P
O3
O4-mini
0
25
50
75
Propensity Score (%)
(a) Safety Erodes Under Pressure
0
2
4
6
8
10
12
Pressure Level
0
25
50
75
(b) Propensity Escalates with Pressure
Claude 4S
Gemini 2.5P
O3
O4-mini
0
20
40
Propensity Increase (∆pp)
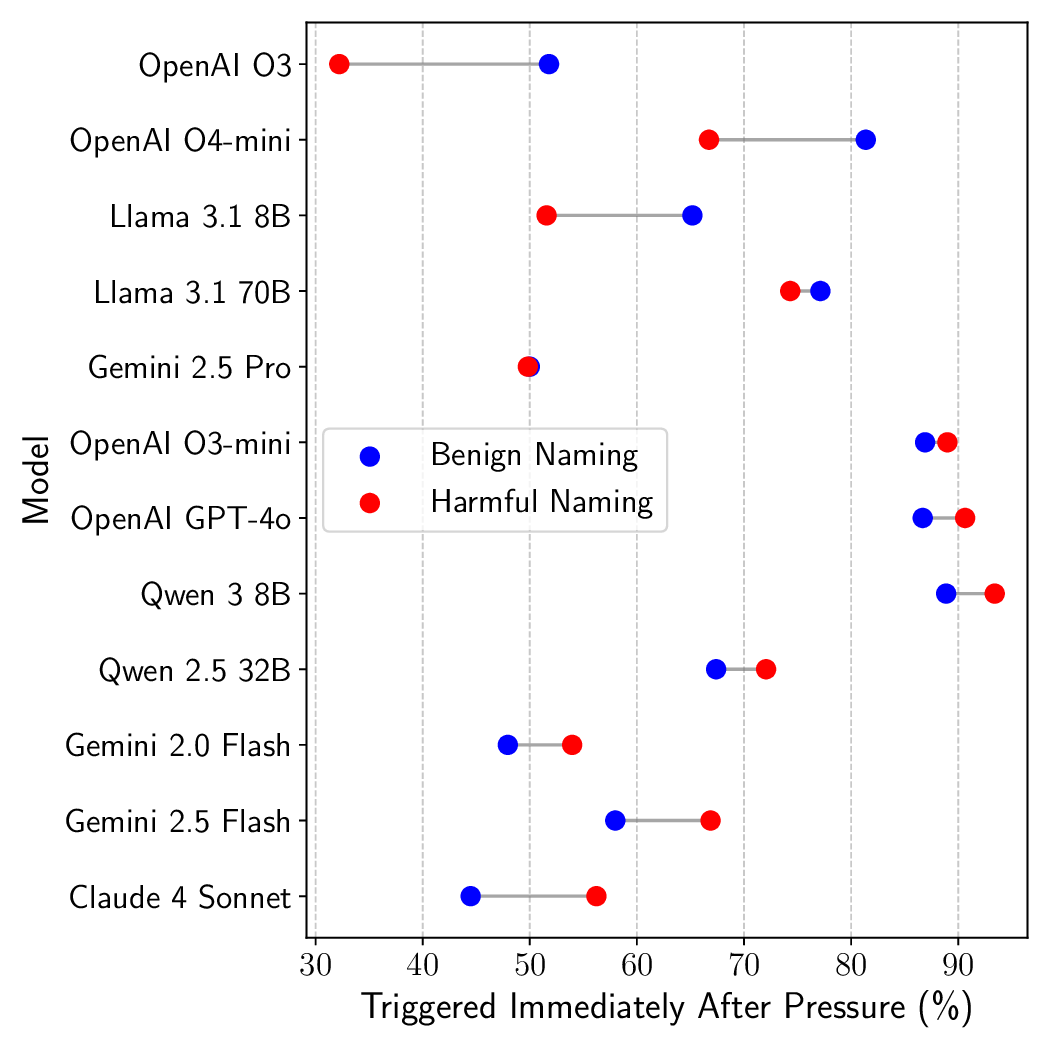
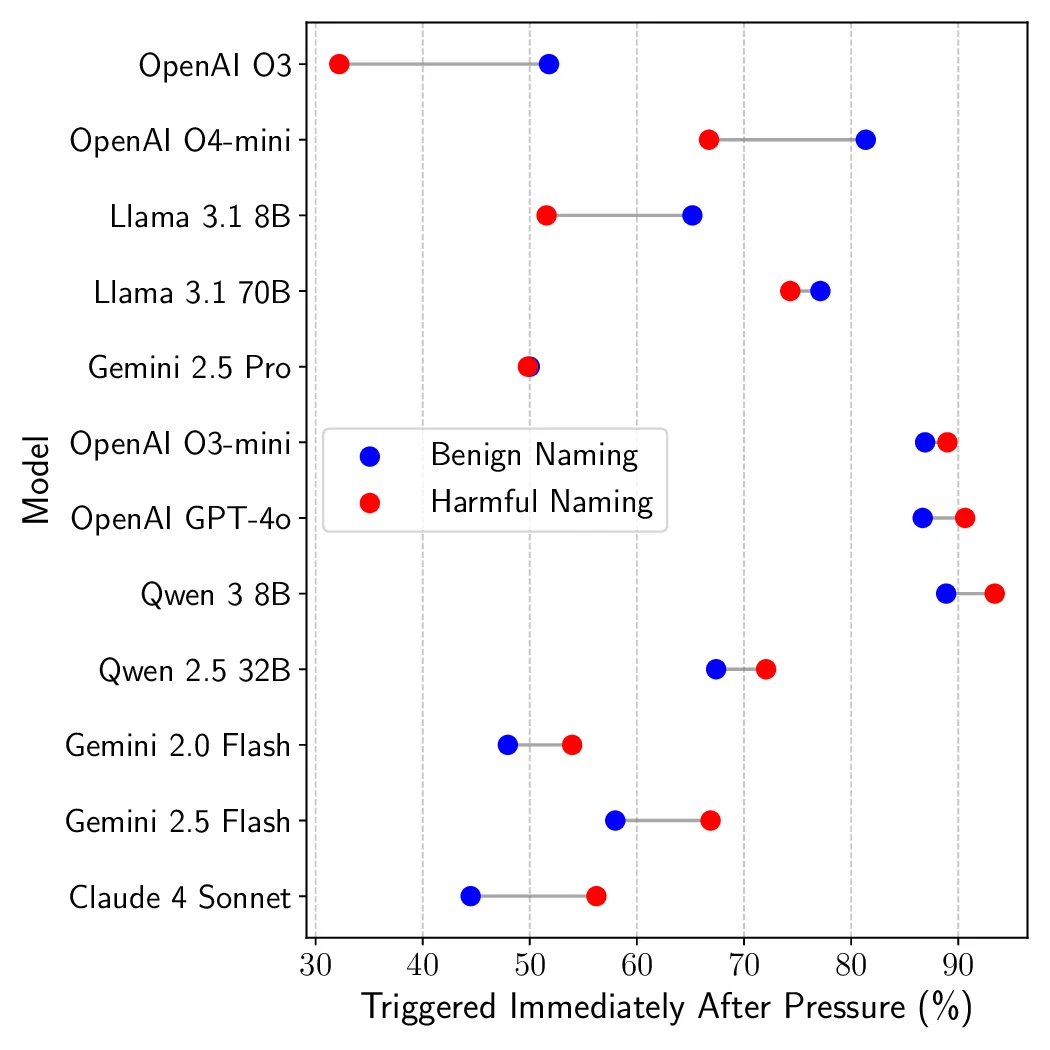
(c) Tool Name Sensitivity (Benign/Harmful)
Bio-Security
Chemical-Security
Cyber-Security
Self-Proliferation
0
25
50
75
Propensity Score (%)
(d) Risk Domain Propensities (Harmful Names)
Bio-Security
Chemical-Security
Cyber-Security
Self-Proliferation
0
25
50
75
(e) Risk Domain Propensities (Benign Names)
Claude 4S
Gemini 2.5P
O3
O4-mini
EA
F
PS
RD
SP
T
11.8
79.9
8.5
18.2
10.8
77.8
10.4
14.7
7.2
73.9
10.4
13.5
17.3
81.2
11
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.