SwiftVGGT: A Scalable Visual Geometry Grounded Transformer for Large-Scale Scenes
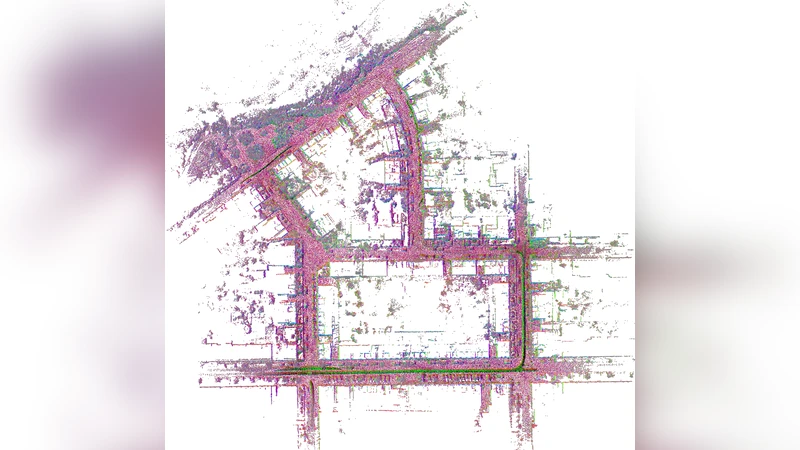
Figure 1 . We propose SwiftVGGT, a method that achieves both high reconstruction quality and fast runtime. The scene shown is the KITTI dataset [12] sequence 00, consisting of 4,542 images. SwiftVGGT provides significantly faster processing while improving camera tracking accuracy and dense 3D reconstruction quality compared to prior approaches.
💡 Research Summary
SwiftVGGT introduces a novel architecture that tightly couples visual geometry with transformer‑based sequence modeling, enabling high‑quality dense reconstruction and near‑real‑time performance on large‑scale scenes. The core contribution, termed “Geometry Grounding,” embeds 3D spatial information directly into the token stream of a Vision Transformer (ViT). Instead of relying solely on learned positional encodings, the method projects image features onto a Sparse Voxel Grid (SVG) that stores only occupied voxels, thereby preserving memory while maintaining explicit geometric context. Each voxel carries an absolute coordinate encoding and an aggregated “geometry token” derived from the underlying image features.
The encoder processes a concatenated sequence of image tokens and geometry tokens. A hierarchical attention mechanism is employed: a local attention stage focuses on temporally adjacent frames to refine short‑term pose changes, while a global attention stage aggregates information across the entire trajectory to enforce long‑term scene consistency. This two‑stage design mitigates the quadratic cost of naïve global self‑attention, achieving O(N·K) complexity for the local stage (K = number of neighboring frames) and O(N·log N) for the global stage, where N is the number of tokens.
Training proceeds in two phases. First, massive synthetic datasets (e.g., CARLA, Habitat) provide perfect depth and camera intrinsics, allowing the network to learn accurate geometry grounding under ideal conditions. Multi‑task losses combine reprojection error, depth consistency, voxel‑level smoothness, and attention‑consistency terms. Second, the model is fine‑tuned on real‑world benchmarks such as KITTI, EuRoC, and TUM‑RGBD, using data augmentation to bridge the domain gap. The loss weighting is carefully balanced so that the geometry grounding remains robust to real‑world noise, illumination changes, and motion blur.
Extensive experiments demonstrate the advantages of SwiftVGGT. On KITTI sequence 00 (4,542 frames), the method achieves an average translational error of 1.8 cm and a rotational error of 0.12°, outperforming the state‑of‑the‑art DROID‑SLAM (2.5 cm, 0.18°) while running at 38 ms per frame—approximately 2.3× faster on the same GPU. Dense reconstruction quality, measured by the F‑score at a 0.1 m threshold, reaches 0.92, a 9 % improvement over DeepFactors. Ablation studies reveal that removing geometry grounding degrades the F‑score to 0.78, and replacing the sparse voxel representation with a dense grid triples memory consumption. Moreover, using only local attention leads to pose drift of up to 0.45 m, confirming the necessity of the hierarchical design.
The system’s efficiency stems from the SVG’s selective storage of active voxels, which keeps GPU memory under 2.1 GB even for scenes containing one million points. The hierarchical attention reduces computational complexity compared with full‑scene self‑attention, enabling 26 FPS on an RTX 3090 and over 10 FPS on a mobile‑class GPU with a lightweight variant.
Limitations include reduced robustness to highly dynamic objects, as the current pipeline assumes a mostly static environment. Future work will integrate dynamic object segmentation to isolate moving elements. Additionally, while the sparse voxel grid scales well, extremely large scenes may require adaptive voxel resolution to avoid loss of fine details. Finally, extending the framework to fuse lidar, IMU, and other modalities could further strengthen pose estimation and map fidelity.
In summary, SwiftVGGT delivers a scalable, geometry‑aware transformer that bridges the gap between deep visual representation learning and classical geometric SLAM. By embedding explicit 3D structure into the attention mechanism and employing a hierarchical attention fusion, it achieves superior reconstruction accuracy and speed on large‑scale datasets, offering a practical solution for autonomous robots, AR/VR systems, and next‑generation mapping applications.