This paper compares Kolmogorov-Arnold Networks (KAN) and Long Short-Term Memory networks (LSTM) for forecasting non-deterministic stock price data, evaluating predictive accuracy versus interpretability trade-offs using Root Mean Square Error (RMSE). LSTM demonstrates substantial superiority across all tested prediction horizons, confirming their established effectiveness for sequential data modeling. Standard KAN, while offering theoretical interpretability through the Kolmogorov-Arnold representation theorem, exhibits significantly higher error rates and limited practical applicability for time series forecasting. The results confirm LSTM dominance in accuracy-critical time series applications while identifying computational efficiency as KANs' primary advantage in resource-constrained scenarios where accuracy requirements are less stringent. The findings support LSTM adoption for practical financial forecasting while suggesting that continued research into specialised KAN architectures may yield future improvements.
Deep Dive into 주가 예측에서 KAN과 LSTM 성능 비교 정확도와 해석 가능성의 균형.
This paper compares Kolmogorov-Arnold Networks (KAN) and Long Short-Term Memory networks (LSTM) for forecasting non-deterministic stock price data, evaluating predictive accuracy versus interpretability trade-offs using Root Mean Square Error (RMSE). LSTM demonstrates substantial superiority across all tested prediction horizons, confirming their established effectiveness for sequential data modeling. Standard KAN, while offering theoretical interpretability through the Kolmogorov-Arnold representation theorem, exhibits significantly higher error rates and limited practical applicability for time series forecasting. The results confirm LSTM dominance in accuracy-critical time series applications while identifying computational efficiency as KANs’ primary advantage in resource-constrained scenarios where accuracy requirements are less stringent. The findings support LSTM adoption for practical financial forecasting while suggesting that continued research into specialised KAN architectu
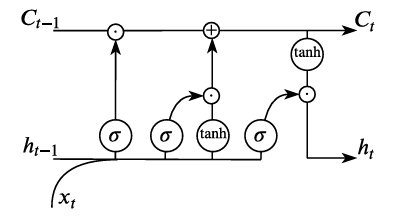
Uncertainty is inherent in financial markets, where it is not possible to uncover deterministic processes that determine asset price movements. Traditional statistical methods, such as ARIMA models (Auto-Regressive Integrated Moving Average), models that predict future values through linear combinations of past observations and forecast errors, and VAR (Vector Auto-Regression models that capture linear interdependencies among multiple time series) have proven inadequate for capturing complex non-linear relationships in financial time series data [17,33]. Advanced Deep Neural Networks (DNNs), particularly Long Short-Term Memory (LSTM) models, have established themselves as the dominant approach to analysing massive datasets and extracting hidden patterns in sequential data [29,15,14].
LSTM have consistently demonstrated superior performance in diverse time series forecasting applications, though their black-box nature limits their interpretability in certain deployment scenarios [10]. Recent developments in Kolmogorov-Arnold Networks (KAN) have attempted to address interpretability concerns by leveraging the Kolmogorov-Arnold representation theorem [23,20], yet standard KAN implementations have shown limited effectiveness for sequential data modelling tasks. However, emerging specialised variants such as Time-Frequency KAN (TFKAN) propose potential improvements for specific long-term forecasting contexts [22], suggesting that targeted applications may exist despite general limitations. In its simplest view, KANs do not require any activation function, but rely on the approximation of these functions in the form of piecewise polynomial functions (often, simply linear splines). This approach is logical, since in the case of ReLU or Leaky ReLU activation functions, the approximations constructed by neural networks are linear splines.
The present study conducts a comprehensive evaluation that compares KAN and LSTM performance with financial data, using historical stock prices due to their stochastic nature [18]. The key aims include the following.
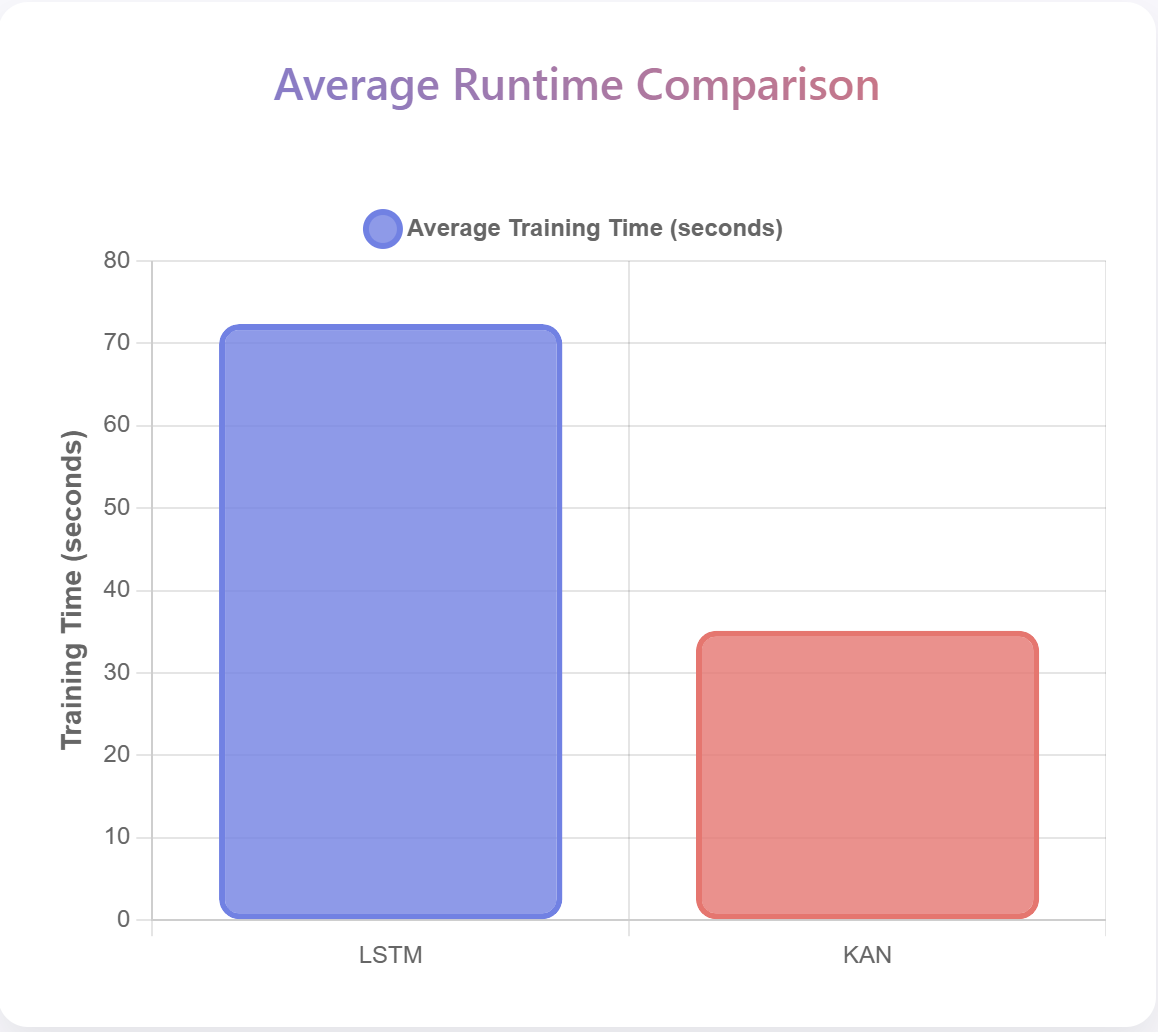
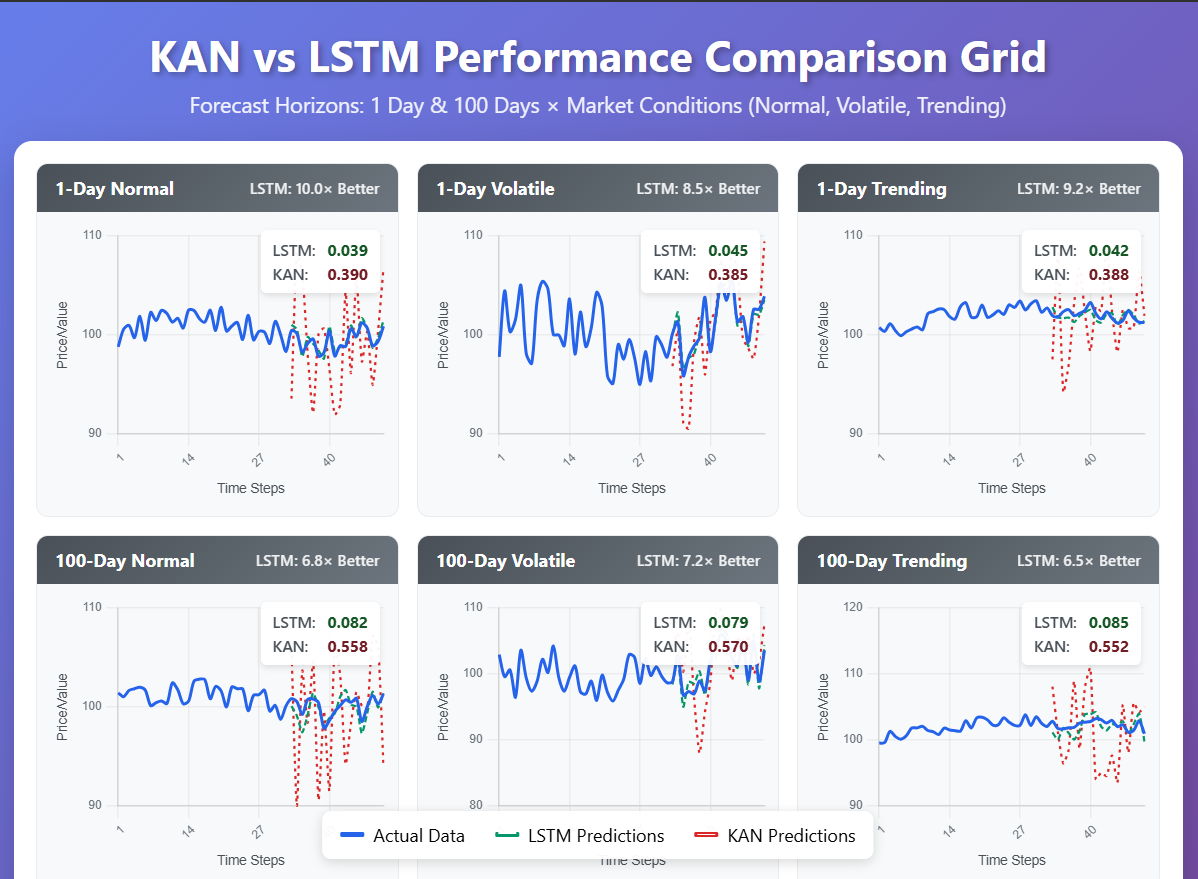
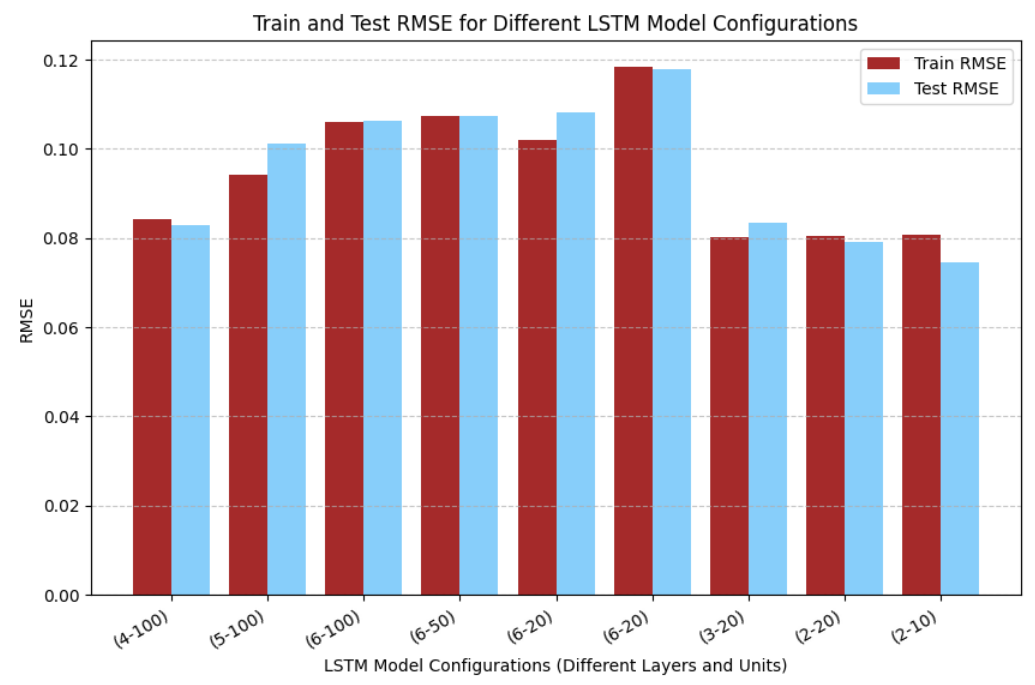
• Evaluation of empirical performance demonstrating LSTM’s superiority across multiple forecast horizons.
• Estimation of quantitative accuracy-interpretability trade-offs in financial time series forecasting.
• Discussion of computational efficiency differences between established and emerging architectures.
• Consideration of specialised KAN variants’ potential for extended prediction horizons.
Non-deterministic forecasting is critical across engineering fields where uncertainty is inherent, including energy demand estimation, environmental pollutant dispersion modelling, and drought forecasting [26,12,24]. While LSTM models have proven highly effective in these applications [5], the interpretability limitations create implementation challenges in high-stakes domains requiring transparent decision-making [25,30]. Despite theoretical promise, standard KAN implementations have not demonstrated competitive performance with established sequential modelling approaches. The main explanation for this is the lack of efficient computational methods for free knot polynomial spline construction [27]. Indeed, the optimisation problems appearing in this research are non-smooth and non-convex and therefore very challenging even for modern optimisation techniques [34]. Moreover, this problem was named as one of the most important and challenging problems in the field of approximation [28]. As such, there has to be a more rigorous study of the mathematical side of the problem before it can be successfully applied to complex forecasting problems. We leave it for our future research directions.
The paper structure follows: Section Preliminaries covers theoretical background emphasising established neural network approaches; Section Methodology details experimental methodology comparing proven and emerging architectures; Section Results and Discussion presents comprehensive performance analysis; Section Conclusion and Further Research Directions summarises findings favouring established methods while identifying potential future research directions; Appendix provides supplementary statistical modelling background.
Let us briefly summarise the evolution and current state-of-the-art of forecasting network models.
Artificial Neural Networks (ANN) are computational models consisting of interconnected nodes that process and “learn” patterns from data [31]. Based on the Universal Approximation Theorem, a sufficiently large network can approximate any continuous function [8,16]. The first and prototypical example is the perceptron, which operates with a decision rule:
where w i are weights, x i are input features, and T is the threshold. This later evolved into sophisticated architectures like CNNs and RNNs for specialised tasks, with RNNs proving particularly effective for sequential data analysis [2].
During training, ANNs adjust weights using back-propagation to minimise errors
…(Full text truncated)…
This content is AI-processed based on ArXiv data.