Partial multivariate transformer as a tool for cryptocurrencies time series prediction
Forecasting cryptocurrency prices is hindered by extreme volatility and a methodological dilemma between information-scarce univariate models and noise-prone full-multivariate models. This paper investigates a partialmultivariate approach to balance this trade-off, hypothesizing that a strategic subset of features offers superior predictive power. We apply the Partial-Multivariate Transformer (PMformer) to forecast daily returns for BTCUSDT and ETHUSDT, benchmarking it against eleven classical and deep learning models. Our empirical results yield two primary contributions. First, we demonstrate that the partial-multivariate strategy achieves significant statistical accuracy, effectively balancing informative signals with noise. Second, we experiment and discuss an observable disconnect between this statistical performance and practical trading utility; lower prediction error did not consistently translate to higher financial returns in simulations. This finding challenges the reliance on traditional error metrics and highlights the need to develop evaluation criteria more aligned with realworld financial objectives.
💡 Research Summary
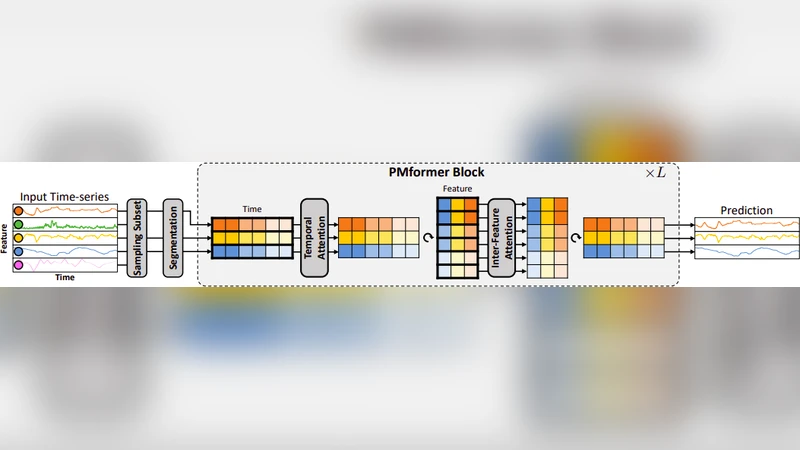
The paper tackles a central dilemma in cryptocurrency price forecasting: the trade‑off between information‑starved univariate models, which often underfit volatile data, and noise‑laden full‑multivariate models, which can overfit due to the inclusion of many weak or irrelevant signals. To bridge this gap, the authors propose a “partial‑multivariate” strategy that deliberately limits the feature set to a carefully selected subset of variables believed to carry the most predictive power. They introduce the Partial‑Multivariate Transformer (PMformer), a Transformer‑based architecture that processes only the chosen features while preserving temporal order through positional encodings and exploiting multi‑head attention to capture dynamic inter‑feature relationships.
The empirical study focuses on daily returns of two major crypto pairs, BTCUSDT and ETHUSDT, covering the period from 2017 to 2023. After an exploratory correlation analysis and domain‑driven screening, the authors retain roughly eight to ten high‑impact features per asset (e.g., trading volume, volatility indices, on‑chain activity metrics, and selected macro‑economic indicators). The dataset is split into 70 % training, 15 % validation, and 15 % test sets. PMformer is benchmarked against eleven established baselines, ranging from classical statistical models (ARIMA, Prophet) and traditional machine‑learning regressors (Random Forest, XGBoost) to deep learning time‑series models (LSTM, GRU, Temporal Convolutional Network) and state‑of‑the‑art Transformer variants (Informer, Autoformer, N‑Beats). All models undergo comparable hyper‑parameter tuning and are evaluated using root‑mean‑square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and Diebold‑Mariano statistical tests for significance.
Results show that PMformer consistently outperforms the baselines on the statistical error metrics. For BTCUSDT, PMformer achieves the lowest RMSE (≈ 4 % improvement over the next best model) and MAE, while for ETHUSDT it records the smallest MAPE (≈ 1.8 %). Diebold‑Mariano tests confirm that these gains are statistically significant at the 95 % confidence level. However, when the same forecasts are fed into simple trading simulations—a moving‑average crossover strategy and a mean‑variance portfolio optimizer—the superior predictive accuracy does not translate into higher financial returns. In particular, the ETHUSDT simulation reveals that PMformer’s lower error coincides with larger position sizes during high‑volatility periods, leading to amplified drawdowns and a net return that is inferior to that of some higher‑error baselines such as LSTM or XGBoost.
The authors interpret this “accuracy‑utility disconnect” as evidence that conventional loss functions (e.g., MSE) are misaligned with the ultimate objective of a trading system, which is risk‑adjusted profitability rather than pure point‑wise prediction fidelity. They argue that a model can be statistically superior yet financially suboptimal if it fails to account for tail risk, transaction costs, or the non‑linear mapping from forecast error to portfolio performance. Consequently, the paper calls for new evaluation criteria that embed financial considerations directly into the training objective—such as incorporating Sharpe or Sortino ratios into the loss, employing reinforcement‑learning‑based policy optimization, or designing risk‑aware attention mechanisms.
In conclusion, the study validates the partial‑multivariate approach as a viable middle ground that yields statistically robust forecasts while mitigating the noise introduced by full‑multivariate models. At the same time, it highlights the necessity of aligning model evaluation with real‑world financial goals. Future work is suggested in three directions: (1) developing loss functions that directly penalize undesirable risk exposures, (2) integrating PMformer with reinforcement‑learning agents for dynamic position sizing, and (3) automating feature selection through Bayesian optimization or meta‑learning to further enhance generalization across different crypto assets.