To enhance the reasoning capabilities of Large Language Models (LLMs) without high costs of training, nor extensive test-time sampling, we introduce Verification-First (VF), a strategy that prompts models to verify a provided candidate answer, even a trivial or random one, before generating a solution. This approach triggers a "reverse reasoning" process that is cognitively easier and complementary to standard forward Chain-of-Thought (CoT), effectively invoking the model's critical thinking to reduce logical errors. We further generalize the VF strategy to Iter-VF, a sequential test-time scaling (TTS) method that iteratively cycles the verification-generation process using the model's previous answer. Extensive experiments across various benchmarks (from mathematical reasoning to coding and agentic tasks) and various LLMs (from open-source 1B to cutting-edge commercial ones) confirm that VF with random answer consistently outperforms standard CoT with minimal computational overhead, and Iter-VF outperforms existing TTS strategies.
Deep Dive into Asking LLMs to Verify First is Almost Free Lunch.
To enhance the reasoning capabilities of Large Language Models (LLMs) without high costs of training, nor extensive test-time sampling, we introduce Verification-First (VF), a strategy that prompts models to verify a provided candidate answer, even a trivial or random one, before generating a solution. This approach triggers a “reverse reasoning” process that is cognitively easier and complementary to standard forward Chain-of-Thought (CoT), effectively invoking the model’s critical thinking to reduce logical errors. We further generalize the VF strategy to Iter-VF, a sequential test-time scaling (TTS) method that iteratively cycles the verification-generation process using the model’s previous answer. Extensive experiments across various benchmarks (from mathematical reasoning to coding and agentic tasks) and various LLMs (from open-source 1B to cutting-edge commercial ones) confirm that VF with random answer consistently outperforms standard CoT with minimal computational overhead, a
To make LLMs adept at complex reasoning tasks, it is common to convert a complex problem into multi-step, modular and primary reasoning steps within their capacity. A fundamental technique is to ask the LLM to "think step by step", forming chain-of-thought (CoT) (Wei et al., 2022). Though generating such a reasoning path leading to the final solution would be much more simpler than directly output the final solution, their reliability is still often undermined by their tendency to generate plausible but incorrect solutions. This fallibility stems from their autoregressive, maximum-likelihood nature to generate coherent natural language, which can prioritize fluency over factual or logical rigor.
To enhance LLM reasoning, existing methods incur significant costs across three dimensions:
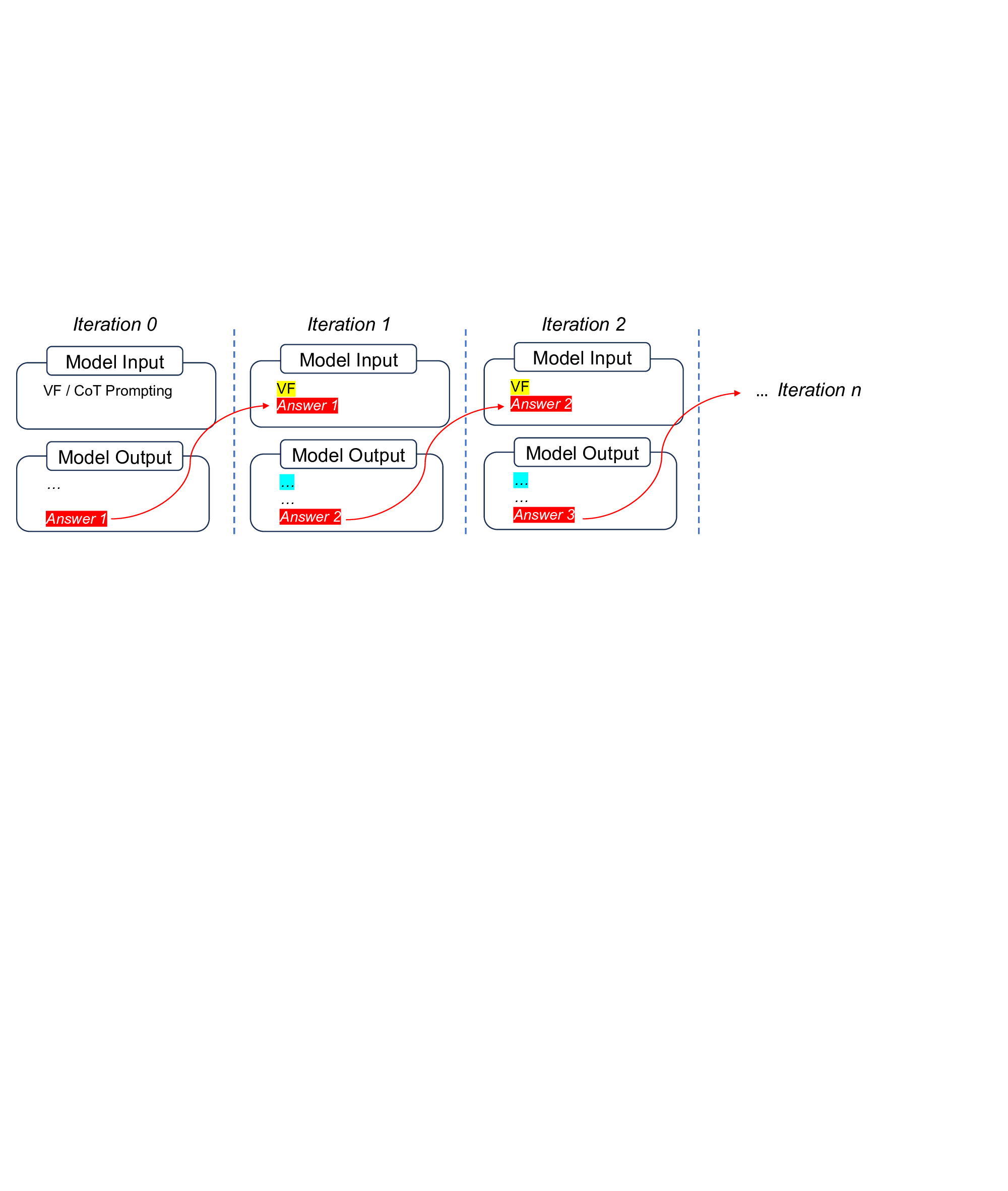
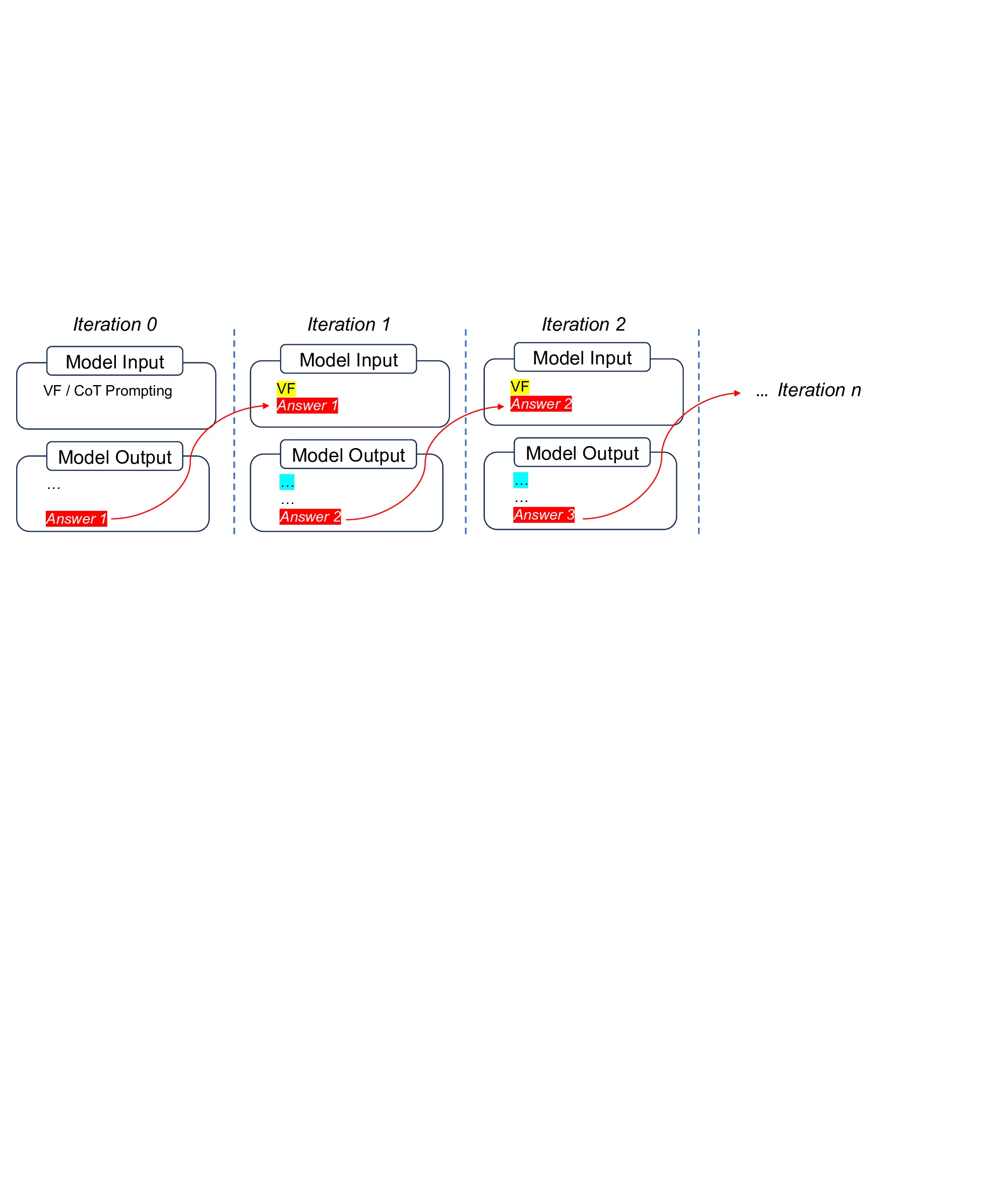
Figure 1: A reverse reasoning path (verification process) could be easier to find and contain complementary information to forward-reasoning path (standard CoT).
prior knowledge, test-time computation, and training. Strategies typically involve crafting problemspecific prompts (Wei et al., 2022;Chia et al., 2023;Alazraki et al., 2025), increasing inference budgets through expensive parallel sampling (Wang et al., 2022) or sequential reflection (Madaan et al., 2023;Shinn et al., 2023), fine-tuning models (Cobbe et al., 2021;Kumar et al., 2025), or involving multiple above perspectives (Yao et al., 2023;Lightman et al., 2023;Besta et al., 2024;Snell et al., 2024;Muennighoff et al., 2025;Setlur et al., 2025). This suggests a prevailing understanding: better reasoning can only be attained at a significant cost.
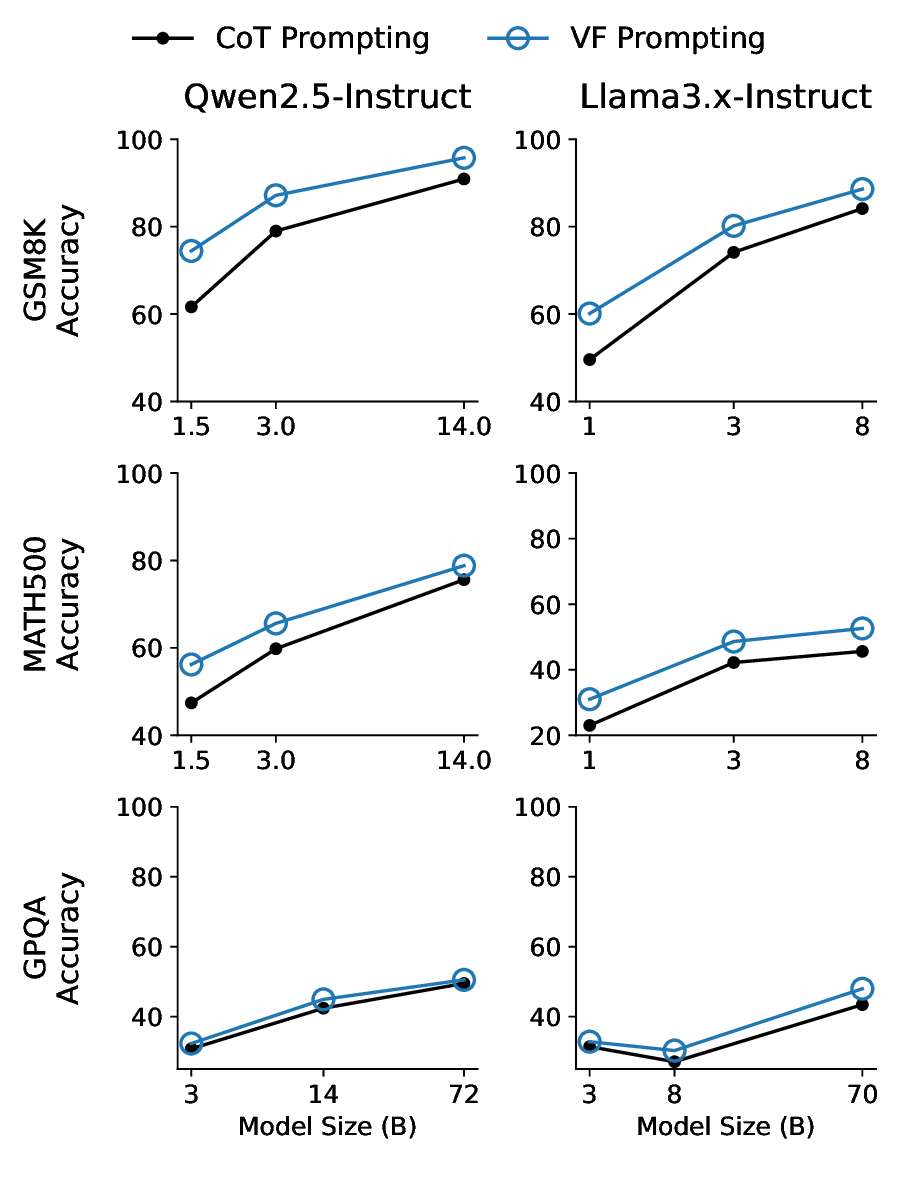
In this paper, we propose a method that is extreme cheap to improve LLM reasoning. The core is Verification-First strategy, providing an answer (regard its correctness or not) along with the problem and ask LLM to first verify/evaluate the provided answer then give correct answer, in contrast to ordinary reasoning that reaches the final answer starting from the problem only. The key insights are (i) logically, verifying an answer is easier than generating a correct answer (Baker et al., 1975), while implies a informative reverse reasoning path that is complementary to standard CoT to be helpful (Polya, 1957); (ii) psychologically, asking one to critic an answer from others could naturally invoke one’s critical thinking by overcoming egocentrism (Piaget, 1976;Brookfield, 1987).
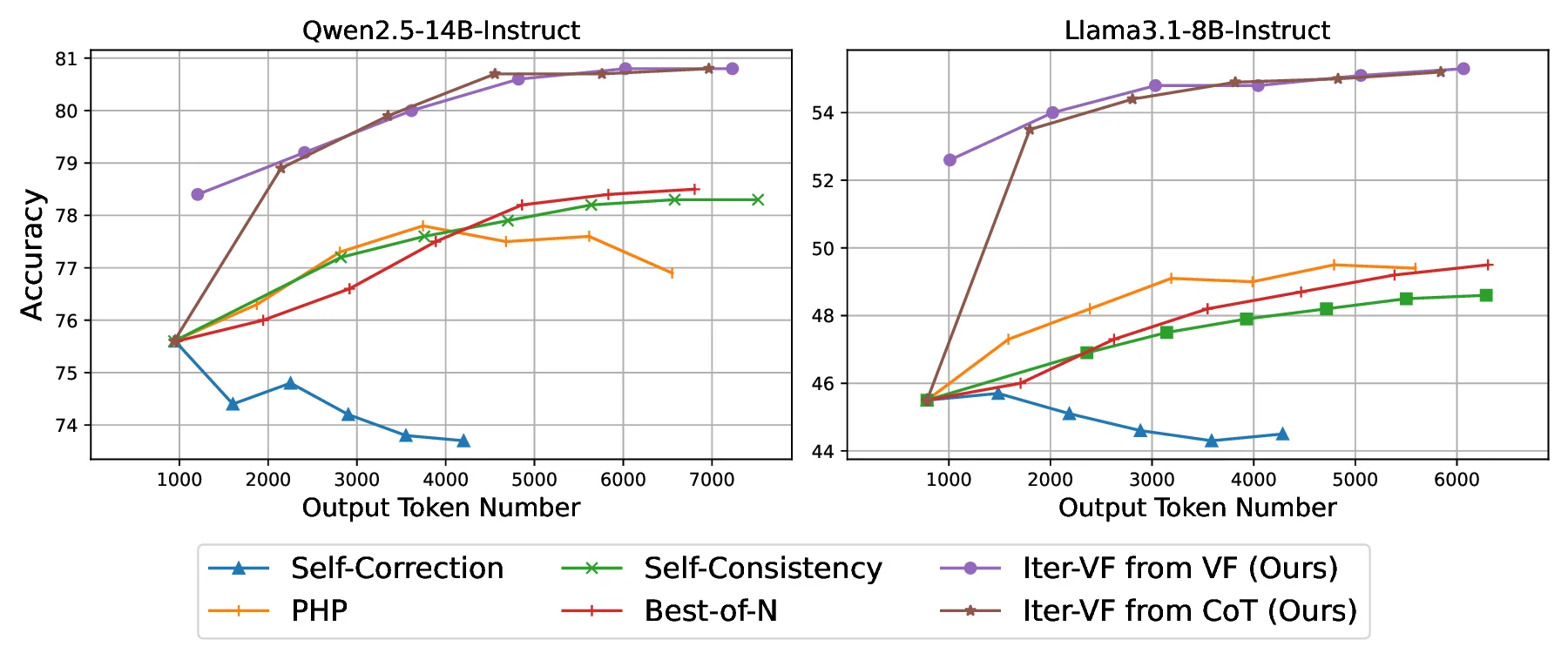
To implement with minimal additional prior knowledge, VF only needs to provide a random/trivial answer in the prompt. The verification process turns out to have much fewer output tokens than an ordinary CoT path, some times even no explicit verification-only process, thus require very small additional test-time computation. To generalize across tasks and control test-time cost, we propose Iter-VF as a TTS strategy, and human providing initial answer is no longer necessary. Iter-VF iterates the VF process with model-generated answer in previous output. Such Iter-VF method turns out to be more effective and efficient than other TTS methods applicable with minimal prior knowledge and no training.
Our contribution can be summarized as follows:
• We propose VF strategy, an extreme cheap way to improve LLM reasoning by providing an answer along with the problem to ask LLM to first verify then generate.
• We implement VF strategy with simple algorithms for scenarios from one-step prompting to TTS.
• Extensive experiments show that the proposed algorithms outperforms standard CoT and existing TTS methods across various tasks and models, including agentic tasks and thought-hidden commercial LLMs.
2 Related Works
To address the fallibility of LLMs generating coherent natural language, which can prioritize fluency over factual or logical rigor, methods tries to improve LLM reasoning ability beyond CoT. Existing methods typically impose additional costs from three distinct perspectives: prior knowledge, test-time computation, and training. Some approaches depend heavily on taskspecific customization. These methods require humans to provide extensive prior knowledge to craft prompts with more few-shot examples or delicate, task-specific instructions (Wei et al., 2022;Chia et al., 2023;Alazraki et al., 2025). This limits generalization as the prompt must be tailored to the specific problem. Another prominent line of work increases inference costs to make reasoning more deliberate. This is often achieved through parallel strategies, such as generating multiple candidates and voting (Wang et al., 2022) or selecting the best via a reward model (Lightman et al., 2023). Alternatively, sequential strategies iteratively reflect on and refine previous steps (Madaan et al., 2023;Shinn et al., 2023). More complex strategies combine these by decomposing steps into trees or graphs (Yao et al., 2023;Besta et al., 2024). While effective, recent studies on TTS suggest that significant performance gains in this paradigm generally require a proportional increase in toke
…(Full text truncated)…
This content is AI-processed based on ArXiv data.