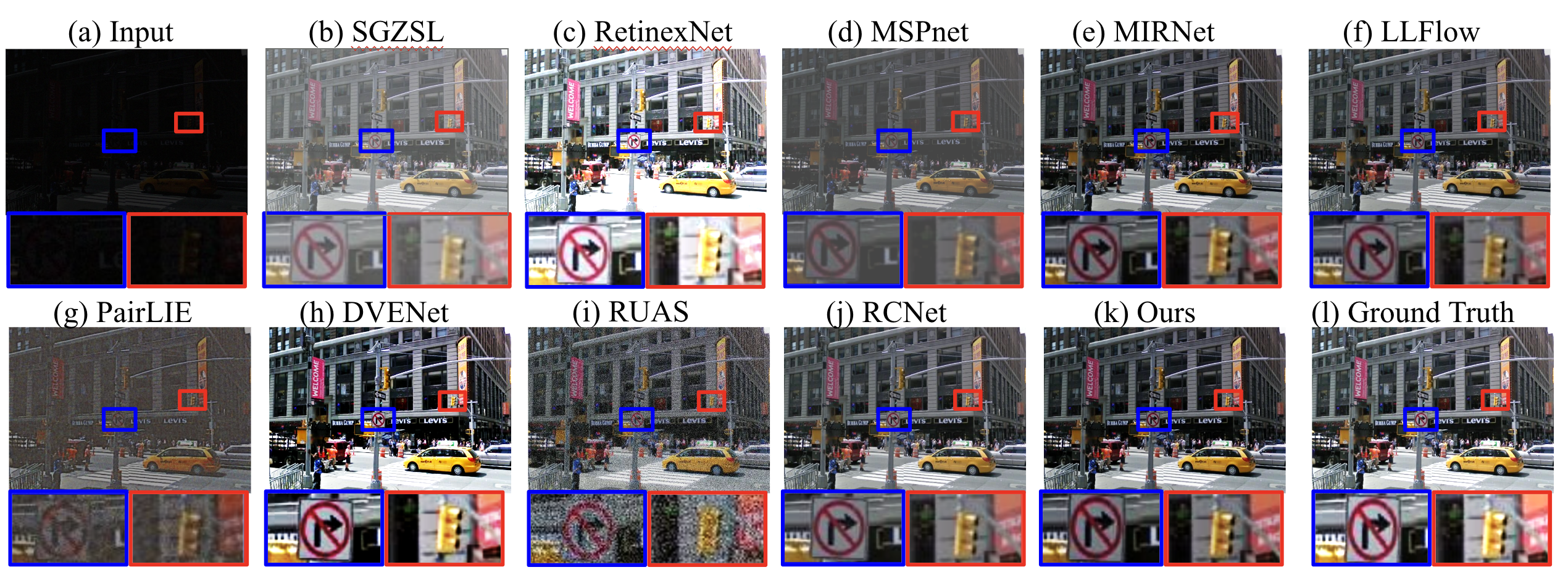
Enhancing low-light traffic imagery is a critical requirement for achieving reliable perception in autonomous driving, intelligent transportation, and urban surveillance systems. Traffic scenes captured under nighttime or dimly lit conditions often suffer from complex visual degradations arising from insufficient illumination, sensor noise amplification, motion-induced blur, non-uniform lighting, and strong glare generated by vehicle headlights or street lamps. These challenges significantly hinder downstream tasks such as object detection, tracking, and scene understanding, demonstrating the need for a robust enhancement framework capable of restoring visibility in diverse real-world conditions without relying on paired training data. To address these issues, we propose a unified unsupervised deep learning framework specifically designed for low-light traffic image enhancement. The proposed model adopts a multi-stage architecture that decomposes the input into illumination and reflectance components and progressively refines each through three functionally specialized modules. First, an Illumination Adaptation module adjusts global and local brightness by leveraging contextual priors, ensuring natural exposure correction and contrast i enhancement. Second, a Reflectance Restoration module equipped with joint spatial-channel attention suppresses noise while selectively recovering structural details crucial for traffic perception tasks. Third, an Over-Exposure Compensation module focuses on reconstructing saturated or washed-out regions caused by intense artificial light sources, effectively balancing luminance across the scene. The overall framework operates under a fully unsupervised setting, guided by selfsupervised reconstruction losses, reflectance smoothness priors, perceptual consistency constraints, and domain-aware regularization. These strategies enable the network to learn meaningful enhancement without ground-truth supervision while preserving textures, suppressing noise, and maintaining color fidelity. Extensive experiments on both general-purpose low-light datasets and traffic-oriented benchmark datasets demonstrate that the proposed method outperforms state-of-the-art techniques across PSNR, SSIM, LPIPS, and and no-reference metrics, including NIQE, and MetaIQA metrics. Qualitative evaluations further show that our approach produces clearer, more artifact-free reconstructions, improving the reliability of subsequent machine vision modules in real-world driving and surveillance environments. Our findings indicate that the proposed unsupervised multi-stage framework offers a scalable and effective solution for enhancing low-light traffic scenes, contributing to safer and more reliable urban vision systems.
Deep Dive into 저조도 교통 영상 향상을 위한 무지도 학습 다단계 프레임워크.
Enhancing low-light traffic imagery is a critical requirement for achieving reliable perception in autonomous driving, intelligent transportation, and urban surveillance systems. Traffic scenes captured under nighttime or dimly lit conditions often suffer from complex visual degradations arising from insufficient illumination, sensor noise amplification, motion-induced blur, non-uniform lighting, and strong glare generated by vehicle headlights or street lamps. These challenges significantly hinder downstream tasks such as object detection, tracking, and scene understanding, demonstrating the need for a robust enhancement framework capable of restoring visibility in diverse real-world conditions without relying on paired training data. To address these issues, we propose a unified unsupervised deep learning framework specifically designed for low-light traffic image enhancement. The proposed model adopts a multi-stage architecture that decomposes the input into illumination and reflect
.
To overcome these challenges, this thesis presents a fully unsupervised low-light image enhancement framework specifically crafted for nighttime traffic imagery. The central idea is to model nighttime scenes as a composition of illumination and reflectance components and then refine each component through a multi-stage enhancement pipeline.
By avoiding reliance on paired ground-truth images, the proposed framework remains applicable to real-world deployment scenarios where only raw nighttime footage is available.
The proposed approach introduces three specialized modules, each addressing a distinct class of nighttime degradations: Training is conducted using a suite of no-reference objectives, including structurepreserving constraints, perceptual similarity losses, illumination consistency terms, and adversarial regularization. These losses collectively guide the model toward producing visually coherent outputs that maintain structural integrity and semantic relevance-without relying on ground-truth illumination or reflectance maps.
Following the Retinex model [17], an image I is expressed as an element-wise product of a reflectance component R and an illumination component L:
In our unsupervised setting, two low-light observations captured under different illu-mination conditions are provided:
where R ′ denotes the shared scene reflectance and L ′ 1 , L ′ 2 correspond to different illumination levels. This formulation encourages the network to produce illumination-invariant reflectance estimates.
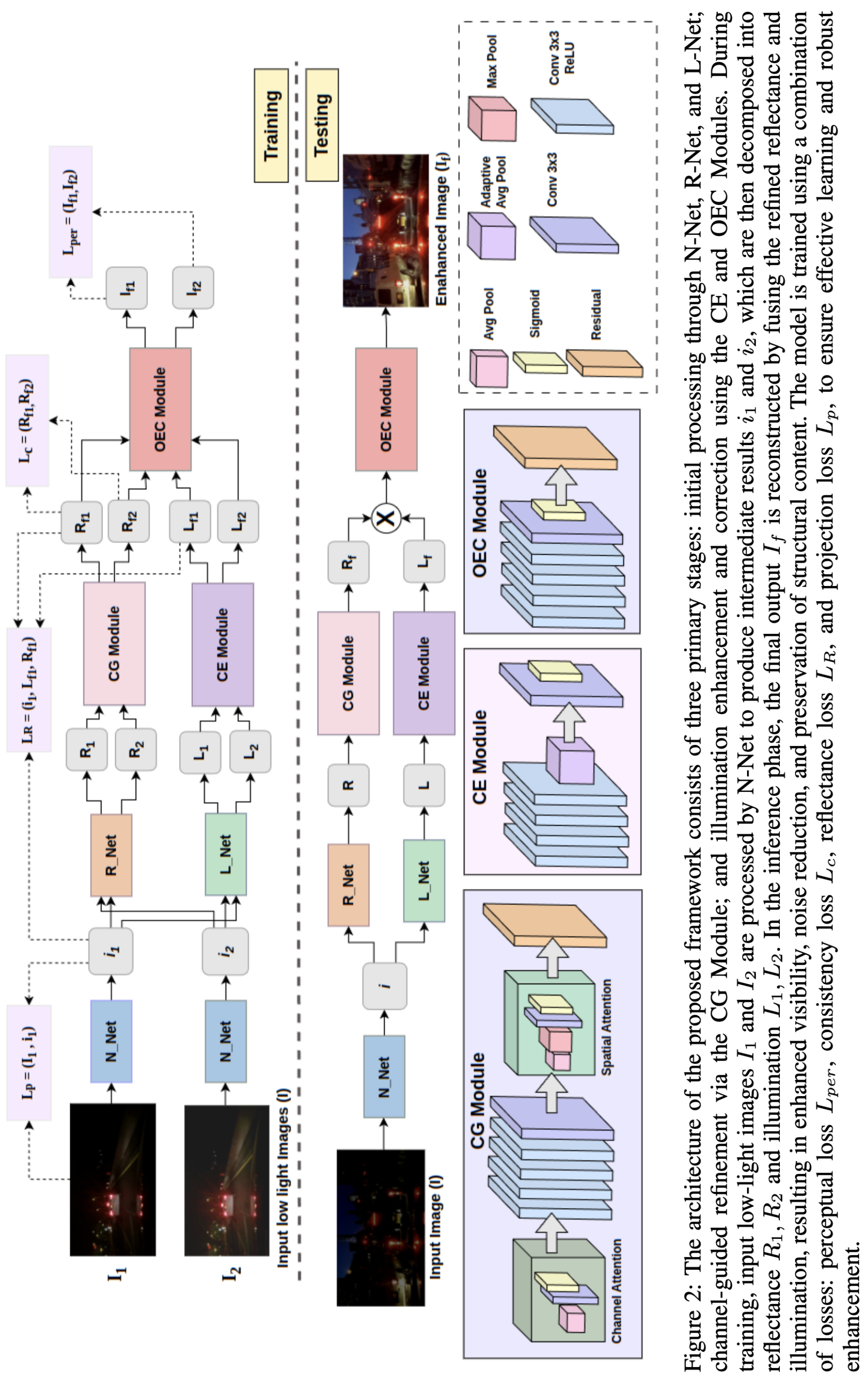
The processing begins with N-Net, which generates an initial normalized projection i 1 , i 2 that stabilizes intensity fluctuations and reduces sensor noise. R-Net and L-Net then decompose each normalized input into its respective reflectance and illumination components:
i -→ (R, L).
The reflectance R encodes essential scene structures such as lane boundaries, vehicles, building edges, and traffic signs. However, in low-light conditions it often contains amplified noise and suppressed textures. To address this, the Channel-Guidance (CG)
Module applies a dual-attention refinement strategy.
First, a channel-attention branch extracts global activation statistics via global average pooling, enabling the network to identify informative feature channels. Second, a spatial-attention branch aggregates average and max-pooled spatial cues to localize regions containing high-frequency structure. These two attention pathways are fused to guide a residual refinement block that produces enhanced reflectance maps:
This refinement ensures sharper edges, improved structural coherence, and noise suppression-crucial for downstream exposure correction.
The These weights modulate the illumination map:
leading to balanced exposure, improved visibility in dark regions, and mitigation of unnatural brightness jumps.
Even after illumination adjustment, regions affected by headlight glare or reflective surfaces may remain saturated. The OEC Module specifically targets such high-intensity regions.
First, the enhanced image is reconstructed using the refined reflectance and illumination maps:
where λ is a fixed illumination control factor regulating enhancement strength.
Residual correction blocks equipped with exposure-sensitive gating units suppress saturation while preserving surrounding luminance. Dilated convolutions capture broader context to restore missing textures. A learned blending mask integrates corrected features smoothly into the image, preventing halo artifacts and over-flattened highlights.
The proposed framework is trained in a fully unsupervised manner, meaning that no paired low-/normal-light images are used during optimization. Instead, we rely on a composite loss that exploits the inherent structure of the Retinex model, the photometric consistency of reflectance across varying exposures, and perceptual constraints that encourage natural-looking reconstructions. Each loss term is designed to correct a specific failure mode commonly observed in low-light enhancement, such as texture oversmoothing, illumination inconsistency, color distortion, and saturation artifacts. Together, these losses enforce stable decomposition, faithful recomposition, and visually coherent enhancement.
The projection loss acts as the first constraint applied to the outputs of N-Net. Since N-Net is responsible for generating an initial normalized projection i from the raw input, the projection loss ensures that this operation does not deviate excessively from the input intensity distribution. Without this constraint, N-Net may over-correct or under-correct illumination during early training stages, leading to unstable gradients. The projection loss therefore serves two purposes: (1) it preserves initialization fidelity, and (2) it stabilizes training so that R-Net and L-Net receive inputs that remain within a physically meaningful range.
This term also implicitly regularizes N-Net against learning a trivial mapping or collap
…(Full text truncated)…
This content is AI-processed based on ArXiv data.