📝 Original Info
- Title: Reinforcement Learning from Implicit Neural Feedback for Human-Aligned Robot Control
- ArXiv ID: 2512.00050
- Date: 2025-11-18
- Authors: Suzie Kim
📝 Abstract
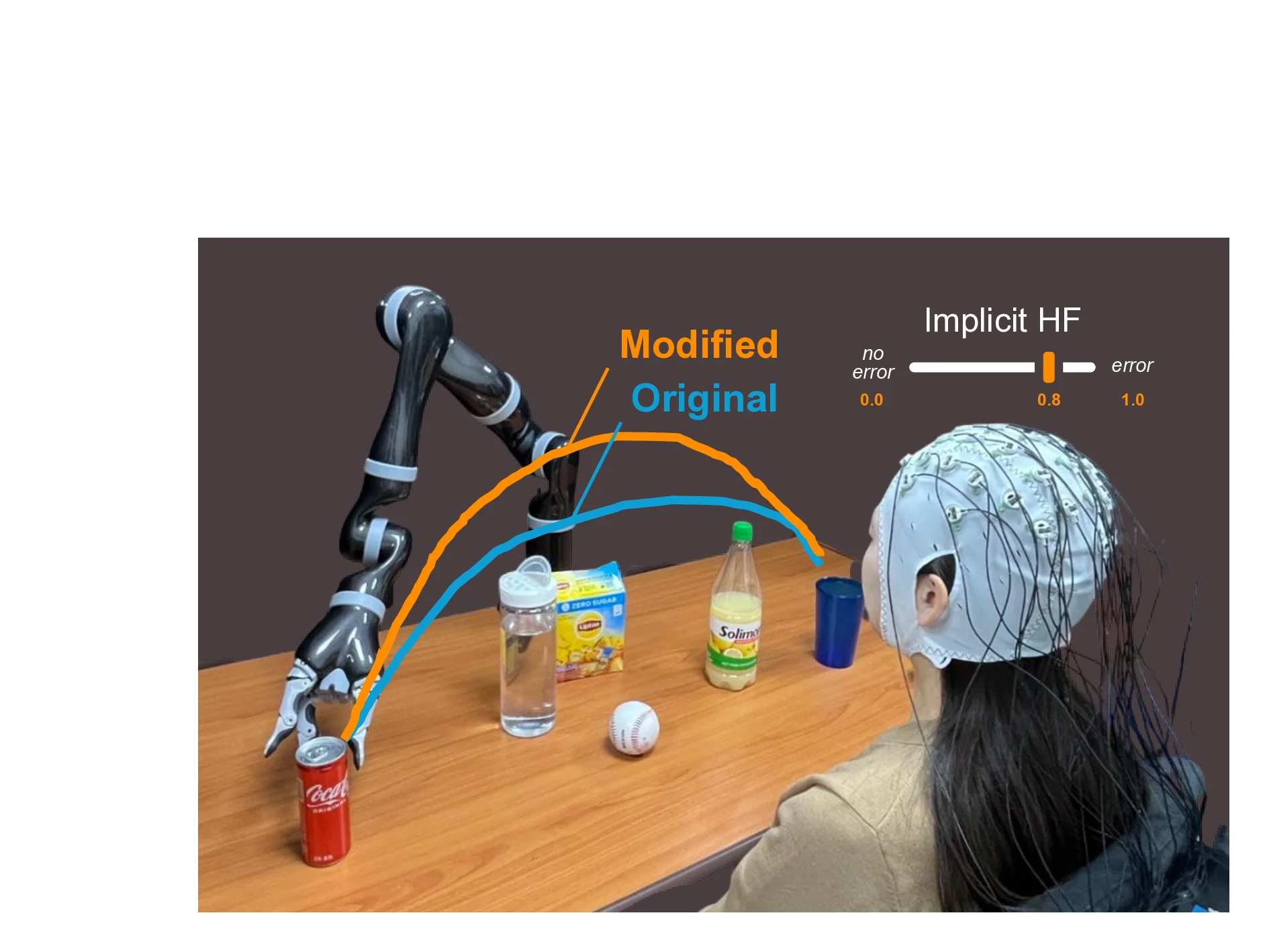
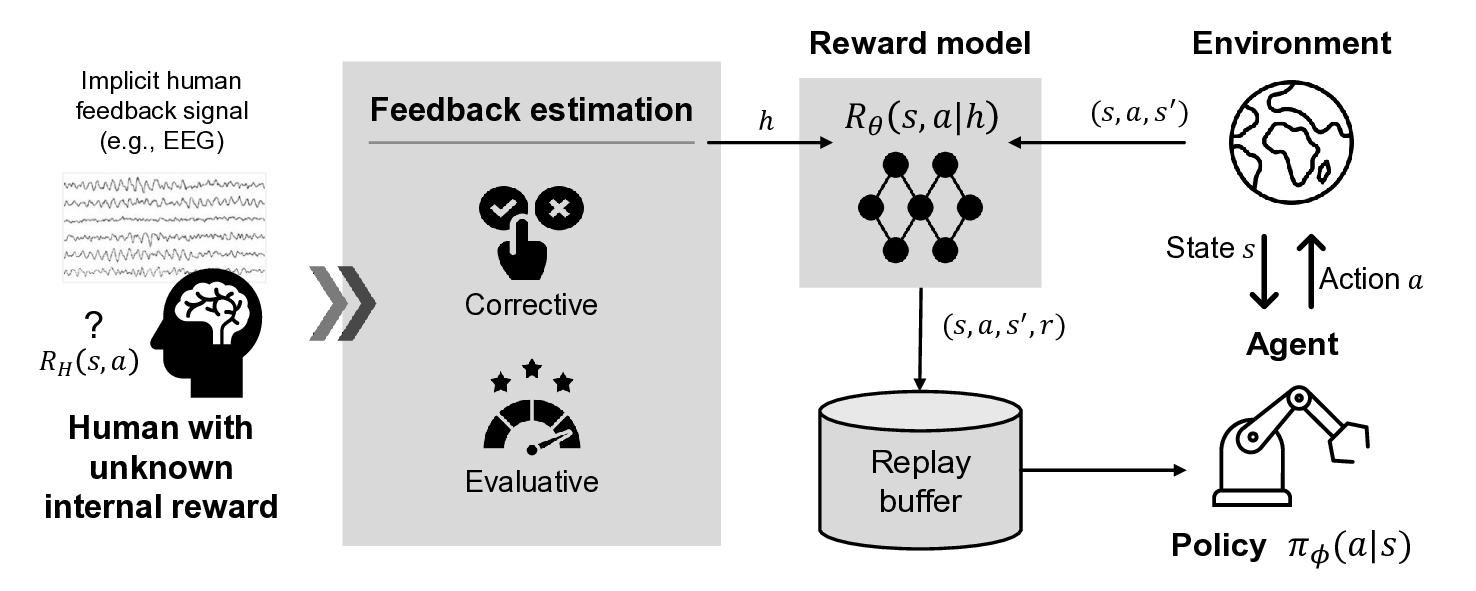
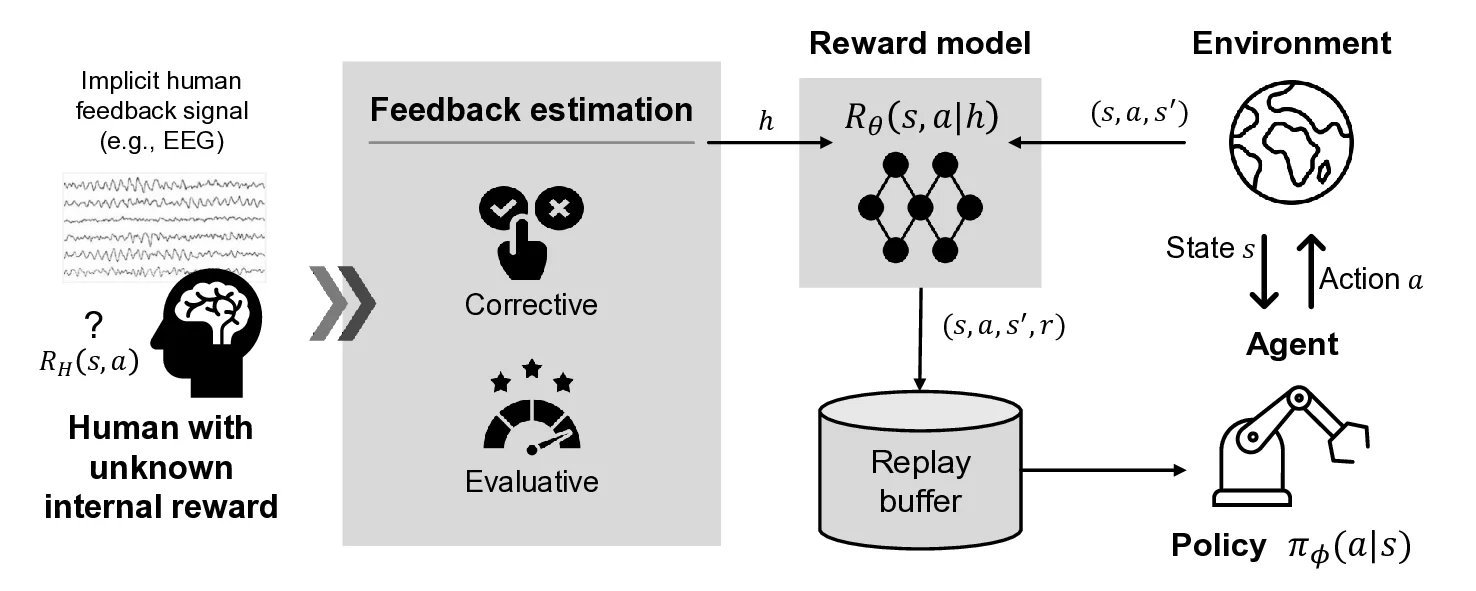
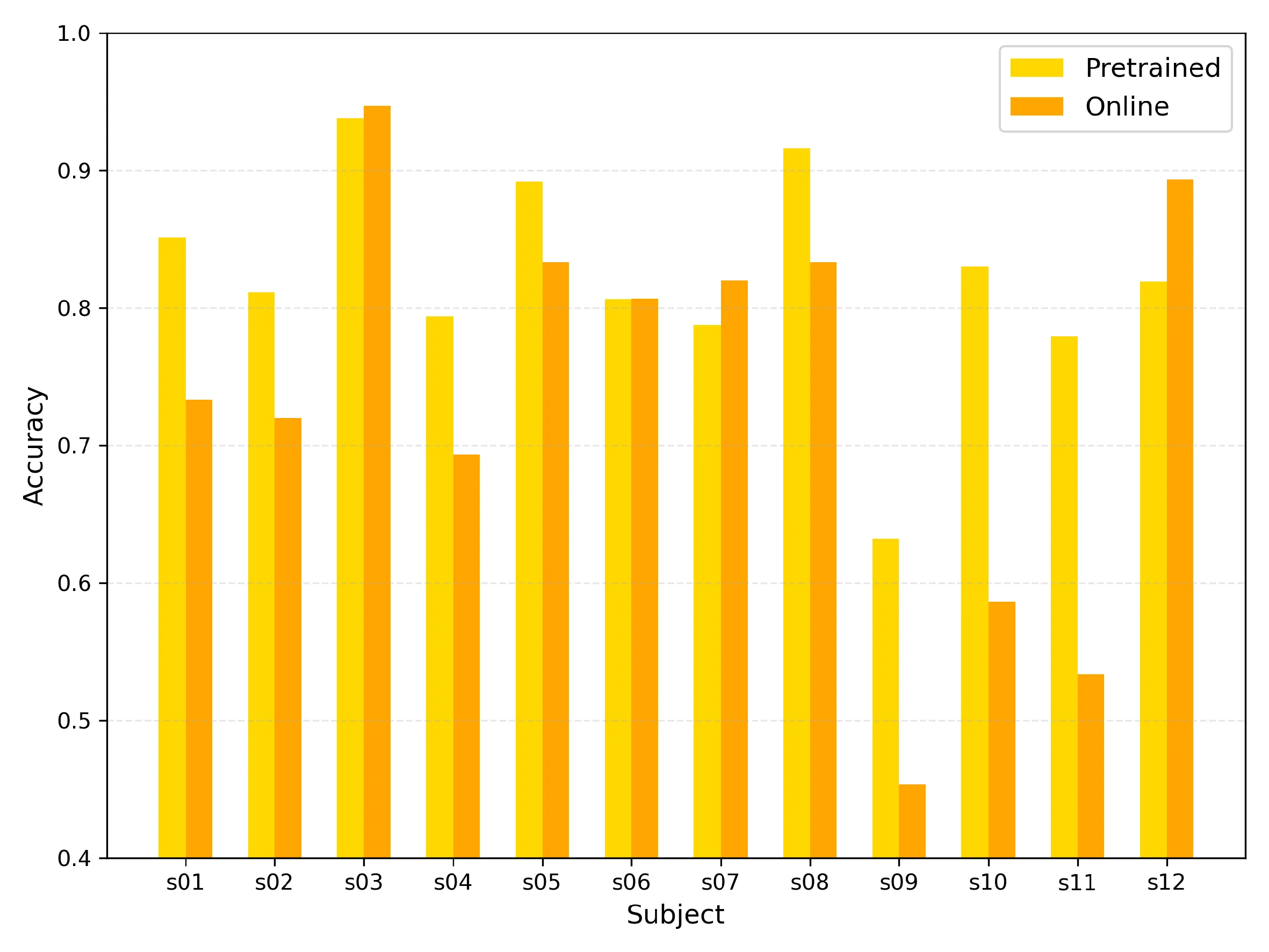
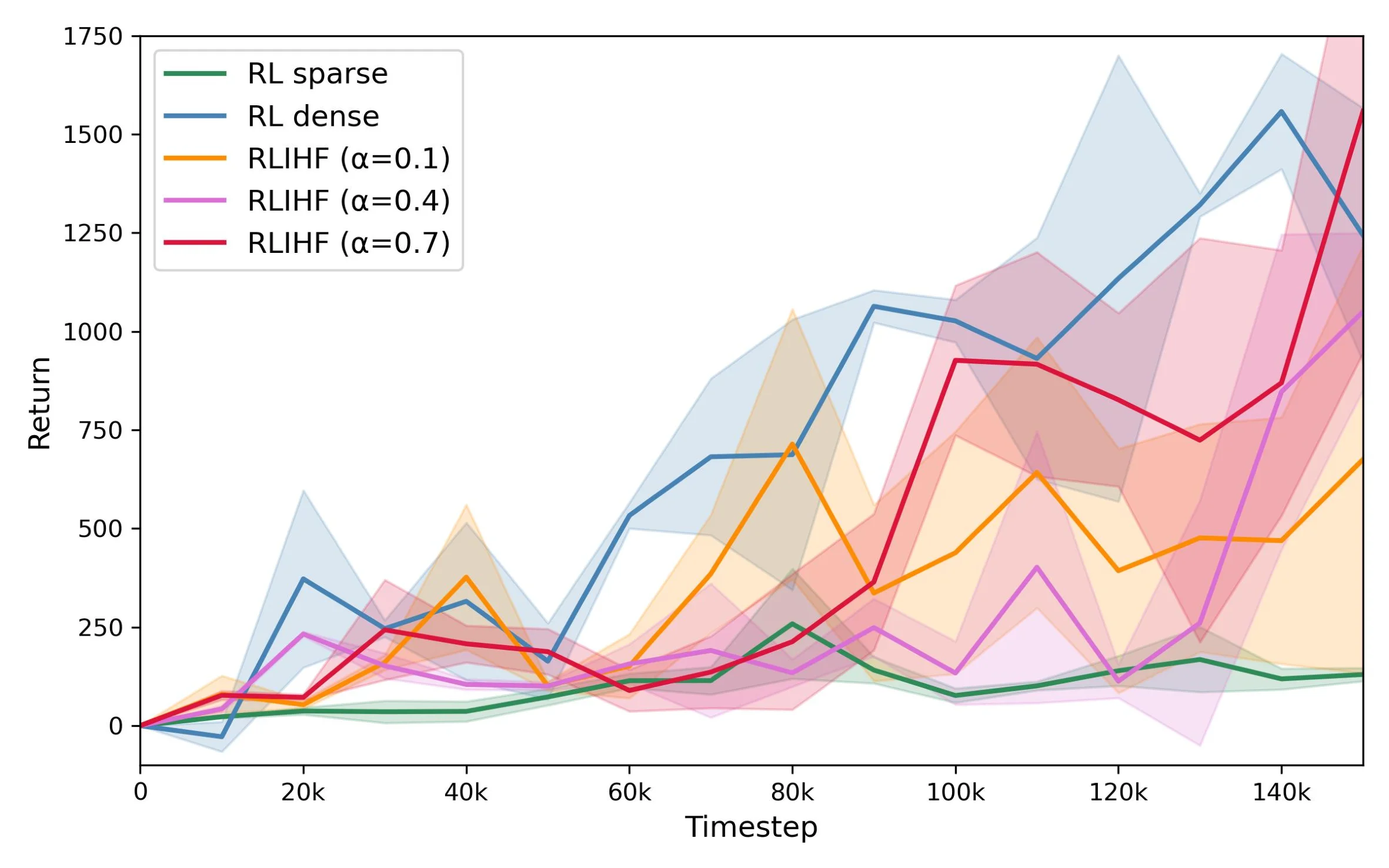
Conventional reinforcement learning (RL) approaches often struggle to learn effective policies under sparse reward conditions, necessitating the manual design of complex, task-specific reward functions. To address this limitation, reinforcement learning from human feedback (RLHF) has emerged as a promising strategy that complements hand-crafted rewards with human-derived evaluation signals. However, most existing RLHF methods depend on explicit feedback mechanisms such as button presses or preference labels, which disrupt the natural interaction process and impose a substantial cognitive load on the user. We propose a novel reinforcement learning from implicit human feedback (RLIHF) framework that utilizes non-invasive electroencephalography (EEG) signals, specifically error-related potentials (ErrPs), to provide continuous, implicit feedback without requiring explicit user intervention. The proposed method adopts a pre-trained decoder to transform raw EEG signals into probabilistic reward components, enabling effective policy learning even in the presence of sparse external rewards. We evaluate our approach in a simulation environment built on the MuJoCo physics engine, using a Kinova Gen2 robotic arm to perform a complex pick-and-place task that requires avoiding obstacles while manipulating target objects. The results show that agents trained with decoded EEG feedback achieve performance comparable to those trained with dense, manually designed rewards. These findings validate the potential of using implicit neural feedback for scalable and human-aligned reinforcement learning in interactive robotics.
💡 Deep Analysis
Deep Dive into Reinforcement Learning from Implicit Neural Feedback for Human-Aligned Robot Control.
Conventional reinforcement learning (RL) approaches often struggle to learn effective policies under sparse reward conditions, necessitating the manual design of complex, task-specific reward functions. To address this limitation, reinforcement learning from human feedback (RLHF) has emerged as a promising strategy that complements hand-crafted rewards with human-derived evaluation signals. However, most existing RLHF methods depend on explicit feedback mechanisms such as button presses or preference labels, which disrupt the natural interaction process and impose a substantial cognitive load on the user. We propose a novel reinforcement learning from implicit human feedback (RLIHF) framework that utilizes non-invasive electroencephalography (EEG) signals, specifically error-related potentials (ErrPs), to provide continuous, implicit feedback without requiring explicit user intervention. The proposed method adopts a pre-trained decoder to transform raw EEG signals into probabilistic re
📄 Full Content
Master’s Thesis
Reinforcement Learning from
Implicit Neural Feedback for
Human-Aligned Robot Control
Suzie Kim
Department of Artificial Intelligence
Graduate School
Korea University
February 2025
arXiv:2512.00050v1 [cs.RO] 18 Nov 2025
Reinforcement Learning from
Implicit Neural Feedback for
Human-Aligned Robot Control
by
Suzie Kim
under the supervision of Professor Seong-Whan Lee
A thesis submitted in partial fulfillment of the
requirements for the degree of Master of Science
Department of Artificial Intelligence
Graduate School
Korea University
October 2025
The thesis of Suzie Kim has been approved
by the thesis committee in partial fulfillment of
the requirements for the degree of
Master of Science
December 2025
Committee Chair: Seong-Whan Lee
Committee Member: Won-Zoo Chung
Committee Member: Tae-Eui Kam
Reinforcement Learning from
Implicit Neural Feedback for
Human-Aligned Robot Control
by Suzie Kim
Department of Artificial Intelligence
under the supervision of Professor Seong-Whan Lee
Abstract
Conventional reinforcement learning (RL) approaches often struggle to
learn effective policies under sparse reward conditions, necessitating the man-
ual design of complex, task-specific reward functions. To address this limi-
tation, reinforcement learning from human feedback (RLHF) has emerged as
a promising strategy that complements hand-crafted rewards with human-
derived evaluation signals. However, most existing RLHF methods depend
on explicit feedback mechanisms such as button presses or preference labels,
which disrupt the natural interaction process and impose a substantial cog-
nitive load on the user.
We propose a novel reinforcement learning from
implicit human feedback (RLIHF) framework that utilizes non-invasive elec-
troencephalography (EEG) signals, specifically error-related potentials (Er-
rPs), to provide continuous, implicit feedback without requiring explicit user
intervention. The proposed method adopts a pre-trained decoder to trans-
i
form raw EEG signals into probabilistic reward components, enabling effective
policy learning even in the presence of sparse external rewards. We evaluate
our approach in a simulation environment built on the MuJoCo physics en-
gine, using a Kinova Gen2 robotic arm to perform a complex pick-and-place
task that requires avoiding obstacles while manipulating target objects. The
results show that agents trained with decoded EEG feedback achieve perfor-
mance comparable to those trained with dense, manually designed rewards.
These findings validate the potential of using implicit neural feedback for
scalable and human-aligned reinforcement learning in interactive robotics.
Keywords: human-robot interaction, brain-computer interface, electroen-
cephalography, error-related potential, reinforcement learning from human
feedback
ii
인간의도기반로봇제어를위한
암묵적신경피드백기반강화학습
김수지
인공지능학과
지도교수: 이성환
초록
기존의강화학습(Reinforcement Learning, RL) 접근법은희소보상(sparse
reward) 환경에서효과적인정책(policy)을학습하는데어려움을겪으며, 이
로인해복잡하고과업별로특화된보상함수를수동으로설계해야하는한
계가존재한다. 이러한문제를해결하기위해, 인간피드백기반강화학습
(Reinforcement Learning from Human Feedback, RLHF) 이주어진보상에
더해인간의평가신호(human-derived evaluation signals) 를보조적으로활용
하는유망한전략으로주목받고있다. 그러나대부분의기존RLHF 기법은버
튼입력이나선호도라벨과같은명시적(explicit) 피드백메커니즘에의존하고
있으며, 이는상호작용의자연스러움을저해하고사용자에게상당한인지적
부담(cognitive load)을초래한다는한계가있다.
본연구에서는이러한한계를극복하기위해, 비침습적(Non-invasive) 뇌파
(Electroencephalography, EEG) 신호, 특히오류관련전위(Error-related Po-
tentials, ErrPs) 를활용하여사용자의명시적개입없이도지속적이고암묵적
인피드백을제공할수있는암묵적인간피드백기반강화학습(Reinforcement
iii
Learning from Implicit Human Feedback, RLIHF) 프레임워크를제안한다.
제안된방법은사전학습된(Pre-trained) 디코더를이용해EEG 원시신호를
확률적보상성분(probabilistic reward components)으로변환함으로써, 외부
보상이희소한상황에서도효과적인정책학습이가능하도록한다.
제안된접근법의유효성을검증하기위해, MuJoCo 물리엔진(physics en-
gine)을기반으로한시뮬레이션환경에서Kinova Gen2 로봇매니퓰레이터
를사용하여복잡한픽앤플레이스(pick-and-place) 과업을수행하였다. 해당
과업은목표물체를조작하면서장애물을회피해야하는복합적조작환경을
포함한다. 실험결과, EEG 피드백으로학습된에이전트는조밀하고수동설
계된보상(dense manual rewards) 으로학습된모델과유사한수준의성능을
달성하였다. 이러한결과는암묵적신경피드백(implicit neural feedback)을활
용한강화학습이대규모확장성(scalability) 과인간적응형(human-adaptive)
로봇학습을구현할수있는잠재력을지님을입증한다.
주제어: 인간-로봇상호작용, 뇌-컴퓨터인터페이스, 뇌파, 오류관련전위,
인간피드백기반강화학습
iv
Preface
This dissertation is submitted for the degree of Master of Science in Ar-
tificial Intelligence at Korea University. The research described herein was
conducted under the supervision of Professor Seong-Whan Lee in the Depart-
ment of Artificial Intelligence, Korea University. Part of this work has been
submitted to the IEEE International Conference on Systems, Man, and Cy-
bernetics. I was the lead investigator for the projects where I was responsible
for all major areas of concept formation, data collection and analysis, as well
as the majority of manuscript composition. Neither this, nor any substan-
tially similar dissertation has been or is being submitted for any other degree,
diploma, or other qualification at any other university
v
Acknowledgement
This research was supported by the Institute of Information & Communications
Technology Planning & Evaluation (IITP) grant, funded by the Korea
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.