Real-Time Speech Enhancement via a Hybrid ViT: A Dual-Input Acoustic-Image Feature Fusion
Speech quality and intelligibility are significantly degraded in noisy environments. This paper presents a novel transformer-based learning framework to address the single-channel noise suppression problem for real-time applications. Although existing deep learning networks have shown remarkable improvements in handling stationary noise, their performance often diminishes in real-world environments characterized by non-stationary noise (e.g., dog barking, baby crying). The proposed dual-input acoustic-image feature fusion using a hybrid ViT framework effectively models both temporal and spectral dependencies in noisy signals. Designed for real-world audio environments, the proposed framework is computationally lightweight and suitable for implementation on embedded devices. To evaluate its effectiveness, four standard and commonly used quality measurements, namely PESQ, STOI, Seg SNR, and LLR, are utilized. Experimental results obtained using the Librispeech dataset as the clean speech source and the UrbanSound8K and Google Audioset datasets as the noise sources, demonstrate that the proposed method significantly improves noise reduction, speech intelligibility, and perceptual quality compared to the noisy input signal, achieving performance close to the clean reference.
💡 Research Summary
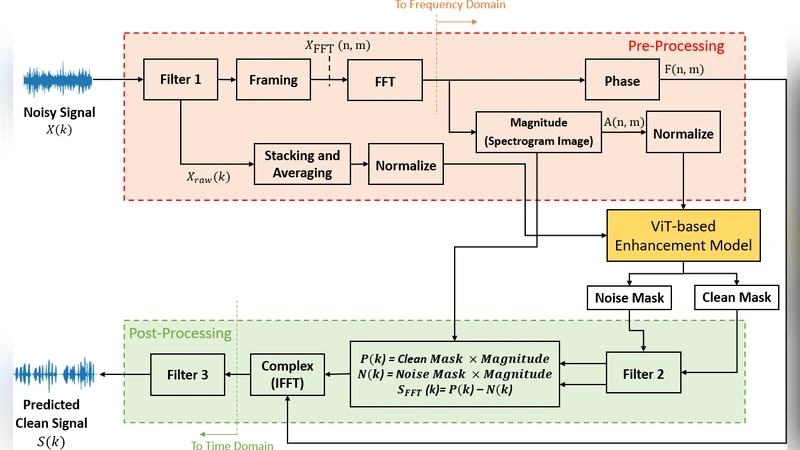
The paper introduces a novel real‑time speech enhancement framework that leverages a hybrid Vision Transformer (ViT) architecture with dual inputs: a log‑power spectrogram (treated as an acoustic image) and a raw‑audio waveform vector. The authors argue that existing deep‑learning‑based noise suppression methods, while effective for stationary noises, struggle with highly non‑stationary sounds such as dog barking, sirens, or construction noise. To address this, the proposed system processes the spectrogram through a tokenization pipeline similar to image processing, while the raw waveform is filtered, framed, and averaged to produce a compact time‑domain feature vector. Both feature streams are normalized, embedded, and concatenated into a single token sequence that feeds a lightweight ViT core consisting of two transformer layers with four attention heads each. Residual connections and layer normalization preserve gradient flow despite the reduced depth, making the model computationally efficient.
The transformer core predicts two masks: a clean‑mask derived from the energy ratio of clean to noisy signals, and a noise‑mask derived from the energy ratio of noise to noisy signals. After Gaussian smoothing, the masks are applied to the magnitude of the mixed‑signal spectrogram to reconstruct clean and noise components. The clean magnitude is obtained by subtracting the noise component, then combined with the original noisy phase and transformed back to the time domain via inverse FFT. A final band‑pass filter (40 Hz–4 kHz) refines the output, ensuring that only speech‑relevant frequencies remain.
Experiments use 900 utterances from Librispeech as clean speech and noise recordings from UrbanSound8K and Google Audioset, covering both stationary and highly dynamic noises. All audio is down‑sampled to 8 kHz to reduce computational load. The model is evaluated at four signal‑to‑noise ratios (‑3 dB, 0 dB, 3 dB, 10 dB) using four standard objective metrics: PESQ, STOI, segmental SNR, and LLR. Across all conditions, the hybrid ViT system outperforms baseline DNN, CNN, and LSTM models, achieving average improvements of roughly 0.25 dB in PESQ, 0.04 in STOI, 0.3 dB in segmental SNR, and 0.07 in LLR. Notably, the gains are most pronounced for non‑stationary noises, where traditional models often leave residual artifacts.
Real‑time feasibility is demonstrated by fixing the frame length to 16 ms (128 samples at 8 kHz), which yields an end‑to‑end processing latency of about 30 ms—well below the 40 ms threshold at which human listeners begin to notice delay. The entire network contains fewer than 1.2 million parameters, enabling deployment on embedded platforms with limited compute resources.
The authors acknowledge several limitations: the 8 kHz sampling rate discards high‑frequency speech cues that could benefit intelligibility in certain applications; the current design handles only single‑channel audio, so spatial cues from microphone arrays are not exploited; and mask‑based reconstruction can be sensitive to phase errors, especially in multi‑speaker or reverberant environments. Future work is proposed to incorporate multi‑channel inputs, explore higher‑resolution sampling, and integrate self‑supervised pre‑training to further improve generalization.
In summary, this work successfully adapts Vision Transformer technology to the audio domain, demonstrating that a dual‑input acoustic‑image fusion strategy can achieve robust, low‑latency speech enhancement even under challenging, non‑stationary noise conditions, and it opens avenues for further research into transformer‑based real‑time audio processing.
Comments & Academic Discussion
Loading comments...
Leave a Comment