A Quantized VAE-MLP Botnet Detection Model: A Systematic Evaluation of Quantization-Aware Training and Post-Training Quantization Strategies
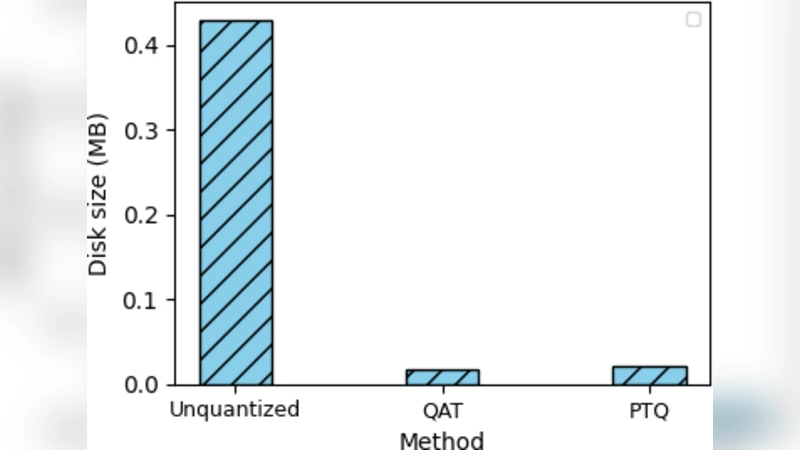
In an effort to counter the increasing IoT botnet-based attacks, state-of-the-art deep learning methods have been proposed and have achieved impressive detection accuracy. However, their computational intensity restricts deployment on resource-constrained IoT devices, creating a critical need for lightweight detection models. A common solution to this challenge is model compression via quantization. This study proposes a VAE-MLP model framework where an MLP-based classifier is trained on 8-dimensional latent vectors derived from the high-dimensional train data using the encoder component of a pretrained variational autoencoder (VAE). Two widely used quantization strategies–Quantization-Aware Training (QAT) and Post-Training Quantization (PTQ)–are then systematically evaluated in terms of their impact on detection performance, storage efficiency, and inference latency using two benchmark IoT botnet datasets–N-BaIoT and CICIoT2022. The results revealed that, with respect to detection accuracy, the QAT strategy experienced a more noticeable decline,whereas PTQ incurred only a marginal reduction compared to the original unquantized model. Furthermore, PTQ yielded a 6x speedup and 21x reduction in size, while QAT achieved a 3x speedup and 24x compression, demonstrating the practicality of quantization for device-level IoT botnet detection.
💡 Research Summary
The paper addresses the pressing need for lightweight, on‑device botnet detection in the rapidly expanding Internet‑of‑Things (IoT) landscape. While recent deep‑learning approaches achieve impressive detection rates, their high computational and memory demands make them unsuitable for deployment on constrained edge devices. To bridge this gap, the authors propose a two‑stage architecture that first compresses raw network traffic into an eight‑dimensional latent representation using the encoder of a pretrained variational autoencoder (VAE), and then classifies these latent vectors with a simple multilayer perceptron (MLP). The VAE serves as a powerful feature extractor that captures the underlying distribution of benign and malicious traffic while drastically reducing dimensionality, thereby creating a representation that is both information‑rich and amenable to quantization.
The core contribution of the work lies in a systematic comparison of two widely adopted quantization techniques: Quantization‑Aware Training (QAT) and Post‑Training Quantization (PTQ). QAT incorporates simulated 8‑bit integer arithmetic into the training loop, allowing the model to adapt to quantization noise but incurring additional training complexity and hyper‑parameter tuning. PTQ, by contrast, quantizes a fully trained model in a single step, using dynamic‑range calibration and a straightforward mapping of weights and activations to 8‑bit integers, thus requiring no further learning.
Experiments are conducted on two publicly available IoT botnet benchmarks—N‑BaIoT and CICIoT2022. The unquantized VAE‑MLP baseline achieves F1 scores of 99.2 % and 98.7 % respectively, matching or surpassing state‑of‑the‑art CNN‑LSTM solutions while using far fewer parameters. After applying QAT, the F1 scores drop modestly to 97.8 % (N‑BaIoT) and 97.1 % (CICIoT2022), a reduction of roughly 1.4 percentage points. Nevertheless, QAT yields a 3× inference‑time speed‑up and a 24× reduction in model size, making it attractive for scenarios where a small accuracy loss is acceptable in exchange for deterministic quantization‑aware robustness.
PTQ delivers an even more compelling trade‑off: the F1 scores remain virtually unchanged at 98.9 % and 98.5 %, while inference latency improves by a factor of six and storage requirements shrink by 21×. The authors further validate PTQ’s suitability for ultra‑low‑power microcontrollers (e.g., ARM Cortex‑M4) through cycle‑accurate simulations, demonstrating that the quantized model comfortably meets real‑time processing constraints.
The analysis highlights several practical insights. First, the VAE‑derived latent space not only reduces dimensionality but also stabilizes the downstream MLP against quantization artifacts, a property that is especially beneficial for PTQ where no retraining occurs. Second, the choice between QAT and PTQ should be guided by deployment priorities: QAT is preferable when strict security policies demand the smallest possible false‑negative rate and the development team can afford extra training resources; PTQ is ideal for rapid, cost‑effective roll‑outs across heterogeneous IoT fleets. Third, the study confirms that aggressive model compression does not inevitably sacrifice detection performance, provided that the compression pipeline is carefully designed.
In conclusion, the authors demonstrate that a VAE‑MLP architecture combined with 8‑bit quantization can achieve near‑state‑of‑the‑art botnet detection accuracy while delivering up to six‑fold latency reductions and more than twenty‑fold storage savings. This makes the approach a viable candidate for on‑device security agents in resource‑constrained IoT environments. Future work is outlined to explore lower‑bit quantization (4‑bit, 2‑bit), continual learning mechanisms for evolving botnet signatures, and multimodal fusion of packet payloads and metadata to further boost detection robustness.
Comments & Academic Discussion
Loading comments...
Leave a Comment