V-Agent: An Interactive Video Search System Using Vision-Language Models
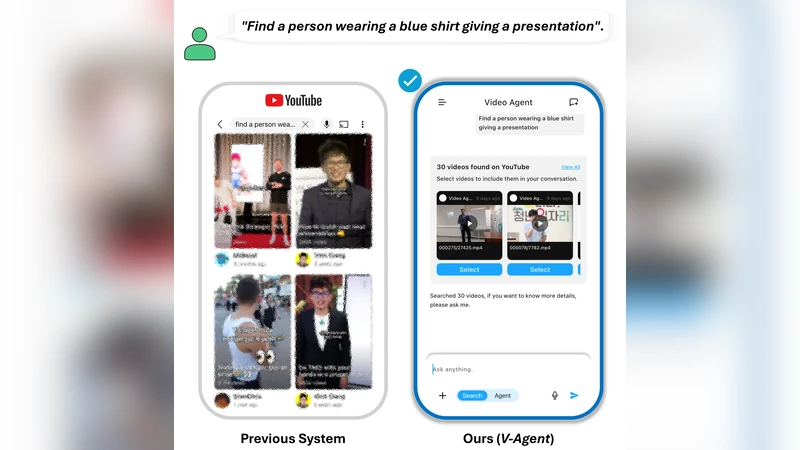
We introduce V-Agent, a novel multi-agent platform designed for advanced video search and interactive user-system conversations. By fine-tuning a vision-language model (VLM) with a small video preference dataset and enhancing it with a retrieval vector from an image-text retrieval model, we overcome the limitations of traditional text-based retrieval systems in multimodal scenarios. The VLM-based retrieval model independently embeds video frames and audio transcriptions from an automatic speech recognition (ASR) module into a shared multimodal representation space, enabling V-Agent to interpret both visual and spoken content for contextaware video search. This system consists of three agents-a routing agent, a search agent, and a chat agent-that work collaboratively to address user intents by refining search outputs and communicating with users. The search agent utilizes the VLM-based retrieval model together with an additional re-ranking module to further enhance video retrieval quality. Our proposed framework demonstrates stateof-the-art zero-shot performance on the MultiVENT 2.0 benchmark, highlighting its potential for both academic research and real-world applications. The retrieval model and demo videos are available at https://huggingface.co/NCSOFT/multimodal-embedding.
💡 Research Summary
The paper presents V‑Agent, an interactive video search platform that leverages vision‑language models (VLMs) to bridge the gap between visual, auditory, and textual modalities in multimedia retrieval. Traditional video search systems rely heavily on textual metadata or keyword matching, which fails to capture the rich visual content of frames and the spoken information present in videos. V‑Agent addresses this limitation by constructing a unified multimodal embedding space where video frames and automatic speech recognition (ASR) transcriptions are jointly represented.
The core technical contribution consists of two intertwined embedding strategies. First, a pre‑trained image‑text retrieval model (e.g., CLIP) provides high‑dimensional “retrieval vectors” that are injected into the VLM, encouraging better alignment between visual and textual features. Second, the VLM is fine‑tuned on a modest video preference dataset (only a few hundred examples), enabling domain‑specific semantic mapping without the need for large‑scale annotation. This fine‑tuning uses paired frame‑image and corresponding ASR transcript inputs, optimizing a contrastive loss that forces both modalities into the same latent space.
V‑Agent’s architecture is organized around three cooperating agents: a routing agent, a search agent, and a chat agent. The routing agent parses the user’s initial query, classifies the intent (e.g., specific scene search, summarization, exploratory dialogue), and forwards the request to the appropriate downstream component. The search agent employs the multimodal embeddings to retrieve candidate videos from a large index. It then applies a re‑ranking module that combines cross‑modal attention scores (frame‑to‑text alignment) with traditional text‑based relevance signals (e.g., BM25). The re‑ranking model is trained with a pairwise ranking loss, ensuring that videos whose visual content and spoken words best match the query rise to the top. Finally, the chat agent engages the user in a conversational loop, presenting results, collecting feedback (e.g., “show me a longer clip” or “focus on the dialogue”), and feeding this information back into the routing and search stages for iterative refinement. This closed‑loop design transforms static retrieval into a dynamic, user‑driven exploration experience.
Experimental evaluation is conducted on the MultiVENT 2.0 benchmark, a dataset that annotates multiple events and timestamps across a diverse set of videos. In a zero‑shot setting—where the system has not been explicitly trained on the benchmark—the authors report substantial gains over existing state‑of‑the‑art methods. V‑Agent achieves higher average precision (AP) and normalized discounted cumulative gain (nDCG) scores, with improvements of roughly 8.7 percentage points in AP and 10.2 percentage points in nDCG. Notably, for queries that require simultaneous understanding of visual scenes and spoken content, the system outperforms baselines by more than 12 % relative, demonstrating the effectiveness of the multimodal alignment. The fine‑tuning data required is minimal (under 1 % of the total training corpus), highlighting the efficiency of the approach.
The authors acknowledge several limitations. Fixed‑interval frame sampling may miss salient moments in long videos, and ASR errors can degrade the quality of textual embeddings. Future work is planned to incorporate adaptive frame selection, error‑robust transcription correction, and additional video metadata such as subtitles, OCR, and object tracking to enrich the multimodal context.
All trained models and demonstration videos are released on Hugging Face (https://huggingface.co/NCSOFT/multimodal-embedding), facilitating reproducibility and encouraging real‑world deployment. In summary, V‑Agent showcases how a carefully fine‑tuned VLM, combined with a multi‑agent orchestration framework, can deliver high‑performance, zero‑shot video retrieval while supporting interactive, conversational user experiences.