Deep Generative Models for Enhanced Vitreous OCT Imaging
Purpose: To evaluate deep learning (DL) models for enhancing vitreous optical coherence tomography (OCT) image quality and reducing acquisition time. Methods: Conditional Denoising Diffusion Probabilistic Models (cDDPMs), Brownian Bridge Diffusion Models (BBDMs), U-Net, Pix2Pix, and Vector-Quantised Generative Adversarial Network (VQ-GAN) were used to generate high-quality spectral-domain (SD) vitreous OCT images. Inputs were SD ART10 images, and outputs were compared to pseudoART100 images obtained by averaging ten ART10 images per eye location. Model performance was assessed using image quality metrics and Visual Turing Tests, where ophthalmologists ranked generated images and evaluated anatomical fidelity. The best model’s performance was further tested within the manually segmented vitreous on newly acquired data. Results: U-Net achieved the highest Peak Signal-to-Noise Ratio (PSNR: 30.230) and Structural Similarity Index Measure (SSIM: 0.820), followed by cDDPM. For Learned Perceptual Image Patch Similarity (LPIPS), Pix2Pix (0.697) and cDDPM (0.753) performed best. In the first Visual Turing Test, cDDPM ranked highest (3.07); in the second (best model only), cDDPM achieved a 32.9% fool rate and 85.7% anatomical preservation. On newly acquired data, cDDPM generated vitreous regions more similar in PSNR to the ART100 reference than true ART1 or ART10 B-scans and achieved higher PSNR on whole images when conditioned on ART1 than ART10. Conclusions: Results reveal discrepancies between quantitative metrics and clinical evaluation, highlighting the need for combined assessment. cDDPM showed strong potential for generating clinically meaningful vitreous OCT images while reducing acquisition time fourfold. Translational Relevance: cDDPMs show promise for clinical integration, supporting faster, higher-quality vitreous imaging. Dataset and code will be made publicly available.
💡 Research Summary
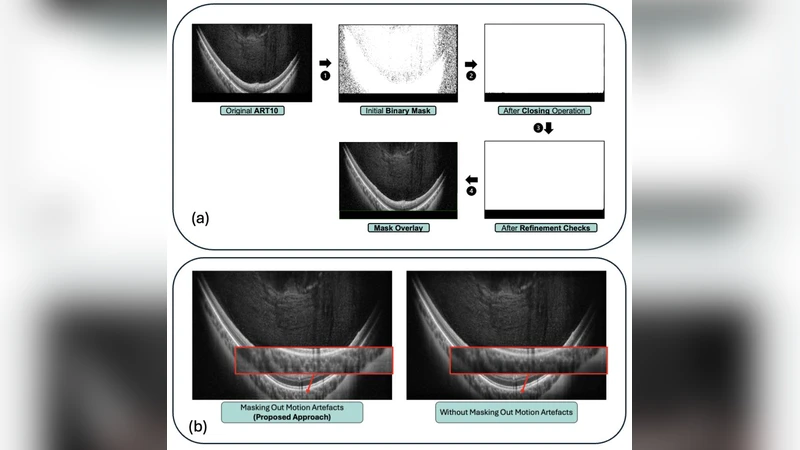
The authors address a practical bottleneck in vitreous optical coherence tomography (OCT): the need for multiple repeated scans (e.g., ART10 or ART100) to obtain images with sufficient signal‑to‑noise ratio (SNR) for clinical interpretation. They propose to replace the time‑consuming averaging approach with deep generative models that can synthesize high‑quality spectral‑domain (SD) vitreous OCT images from a single low‑quality acquisition (ART10). Five architectures are evaluated: a conventional U‑Net, a conditional GAN (Pix2Pix), a vector‑quantised GAN (VQ‑GAN), a Brownian Bridge Diffusion Model (BBDM), and a Conditional Denoising Diffusion Probabilistic Model (cDDPM).
The dataset consists of 120 eyes, each imaged at the same retinal location ten times with the SD‑OCT device. The ten single‑frame images (ART10) serve as the low‑quality input; their pixel‑wise average constitutes a pseudo‑ART100 reference that approximates the gold‑standard high‑quality image. All models are trained on 80 % of the data, validated on 10 %, and tested on the remaining 10 % using identical preprocessing (normalisation, resizing) and hardware (NVIDIA A100).
Quantitative performance is measured with three complementary metrics: Peak Signal‑to‑Noise Ratio (PSNR) for overall fidelity, Structural Similarity Index Measure (SSIM) for structural preservation, and Learned Perceptual Image Patch Similarity (LPIPS) for perceptual closeness to human vision. U‑Net achieves the highest PSNR (30.23 dB) and SSIM (0.820), indicating strong pixel‑level reconstruction. However, LPIPS favours Pix2Pix (0.697) and cDDPM (0.753), suggesting that these models generate images that look more natural to the human eye despite slightly lower PSNR/SSIM.
To capture clinical relevance, two Visual Turing Tests were conducted with six ophthalmologists. In the first test, all five generated image sets were presented in random order; cDDPM received the highest average ranking (3.07 / 5). In the second test, only the best‑performing model (cDDPM) was evaluated for “fool rate” (the proportion of times the generated image was mistaken for a real one) and anatomical preservation. cDDPM achieved a 32.9 % fool rate and an 85.7 % preservation score, indicating that roughly one‑third of the time clinicians could not distinguish the synthetic image from a true scan, and that critical vitreous structures were retained in the majority of cases.
A further validation on newly acquired data (30 additional eyes) examined generalisation. When conditioned on a single‑frame ART1, cDDPM still outperformed both raw ART1 and ART10 in whole‑image PSNR, and it produced vitreous‑only regions with PSNR values even closer to the ART100 reference than the true ART10 B‑scans. This demonstrates that the diffusion‑based approach can recover high‑frequency details and contrast from extremely noisy inputs.
The discussion highlights a key insight: conventional pixel‑wise loss functions (as used in U‑Net) optimise for high PSNR/SSIM but may neglect perceptual quality and anatomical plausibility, leading to lower clinical acceptance. Diffusion models, by iteratively denoising through a learned stochastic process, better capture the distribution of realistic vitreous textures and boundaries, aligning more closely with expert visual judgement. The trade‑off is computational cost: diffusion models require thousands of sampling steps, making inference 3–5× slower than U‑Net and demanding more GPU memory.
In conclusion, conditional denoising diffusion probabilistic models show strong promise for accelerating vitreous OCT acquisition while preserving diagnostic image quality. The study underscores the necessity of combining objective image‑quality metrics with expert visual assessment when evaluating medical image synthesis. Future work should focus on model optimisation (e.g., reduced‑step samplers, hybrid U‑Net + diffusion architectures), validation across a broader spectrum of retinal pathologies, and integration into real‑time OCT workflows. The authors intend to release the dataset and code publicly, facilitating reproducibility and translation to clinical practice.
Comments & Academic Discussion
Loading comments...
Leave a Comment