The Era of Agentic Organization: Learning to Organize with Language Models
💡 Research Summary
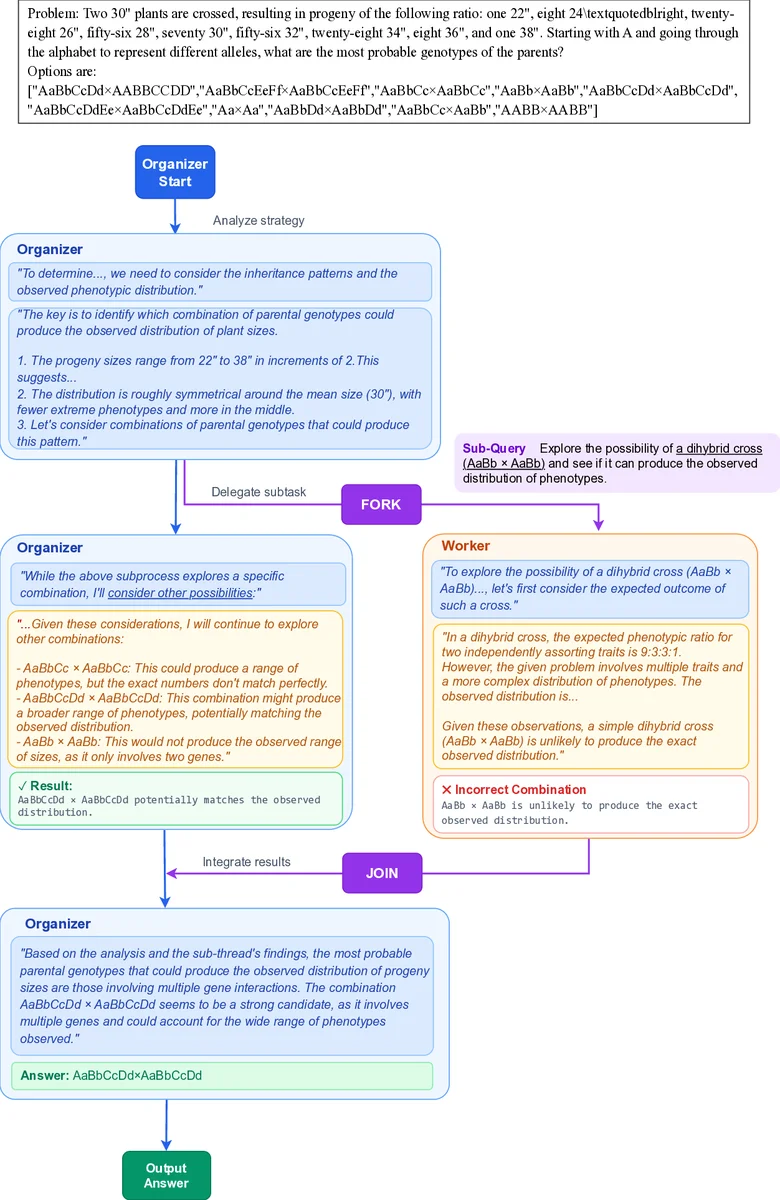
The paper introduces a new reasoning paradigm called Asynchronous Thinking (AsyncThink) that enables large language models (LLMs) to organize their internal reasoning processes into concurrently executable structures. The core of AsyncThink is an organizer‑worker protocol in which a single LLM plays two roles: an organizer that controls the overall flow by emitting textual action tags (FORK, JOIN, THINK, ANSWER) and workers that independently process sub‑queries assigned by the organizer. When the organizer emits a FORK tag, it defines a sub‑query and dispatches it to an available worker; the worker runs its own decoding thread and returns a result wrapped in a RETURN tag. The organizer can continue generating tokens, issuing additional FORK tags, or later emit a JOIN tag to incorporate a worker’s output into its own context. This design requires no changes to the underlying neural architecture; the entire coordination is expressed as plain text, making it compatible with existing LLM APIs.
Training proceeds in two stages. Stage 1 is a cold‑start format fine‑tuning phase where synthetic organizer‑worker traces are generated using GPT‑4o. The synthetic data teach the model the syntax of the action tags and basic topologies (interleaved Fork‑Join or batch Fork‑then‑Join). The model learns to emit valid tags but not yet to solve tasks correctly. Stage 2 applies reinforcement learning (RL) to refine both correctness and efficiency. The reward function combines three components: (1) an accuracy reward that is binary for single‑answer tasks or proportional for multi‑solution tasks; (2) a format‑error penalty that penalizes duplicated sub‑query IDs, pool overflow, invalid JOINs, or missing final answers; (3) a concurrency reward that measures the average number of active workers η over the critical‑path length T, encouraging the model to keep η close to the pool capacity c while preventing gaming via a threshold τ. The overall reward is R = (no‑format‑error ? R_A : 0) + λ·R_η.
Because an AsyncThink episode consists of multiple interleaved token streams (organizer and several workers), the authors extend Group‑Relative Policy Optimization (GRPO) to handle non‑sequential samples. They treat the organizer trace together with its associated worker traces as a single unit when computing advantages, masking out the returned text from loss computation while still counting JOIN tokens.
Experiments evaluate AsyncThink on three benchmark families: multi‑solution countdown problems, mathematical reasoning (e.g., GSM8K style), and Sudoku puzzles. Two metrics are reported: final‑answer accuracy and Critical‑Path Latency, the latter being the length of the longest sequential dependency in the asynchronous execution graph, serving as a theoretical lower bound on inference time. Compared with standard sequential reasoning, AsyncThink improves accuracy by 3–5 % across tasks. Compared with a parallel‑thinking baseline that runs independent traces and aggregates at the end, AsyncThink reduces critical‑path latency by an average of 28 %, demonstrating more efficient use of parallel resources. Notably, the model generalizes to unseen task types without additional training, performing zero‑shot asynchronous reasoning and maintaining both higher accuracy and lower latency than baselines.
The paper also draws an analogy between agentic‑organization concepts and classic computer‑system components: an “agent” corresponds to a single‑core CPU, an “agent pool” to a multicore processor, and an “organization policy” to a multiprocess program that schedules work. This framing grounds the AI‑centric ideas in well‑understood systems theory, suggesting that future AI research can leverage established scheduling and concurrency principles.
In summary, AsyncThink demonstrates that LLMs can be taught not only to think but also to self‑organize their thinking into dynamic, concurrent structures. By combining a text‑only coordination protocol with a two‑stage training pipeline (synthetic format fine‑tuning followed by RL with multi‑objective rewards), the authors achieve both higher reasoning performance and reduced inference latency, while also showing strong zero‑shot generalization. This work constitutes a concrete step toward the envisioned “agentic organization” era, where collections of AI agents collaborate as an organized system to solve problems beyond the capacity of any single model.
Comments & Academic Discussion
Loading comments...
Leave a Comment