Completion $ neq$ Collaboration: Scaling Collaborative Effort with Agents
Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals a
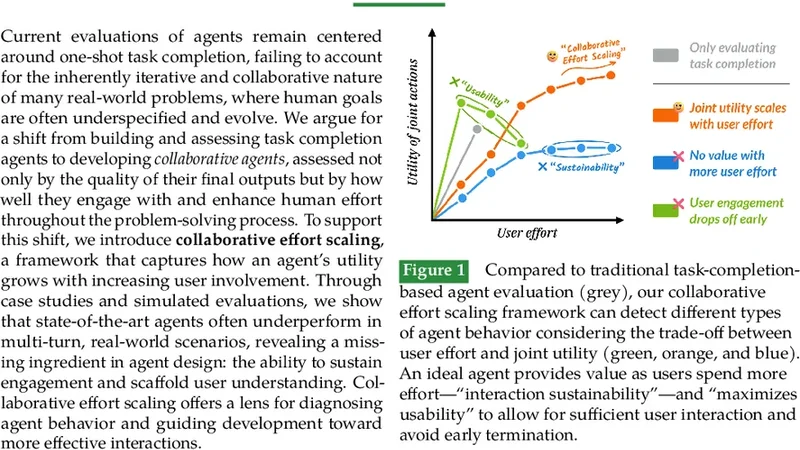
Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent’s utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
💡 Research Summary
The paper opens by critiquing the dominant paradigm in AI agent evaluation, which treats success as a single‑shot task completion: a user provides a prompt, the model returns an answer, and the interaction ends. While this setup is convenient for benchmark construction, it ignores the reality that many real‑world problems are underspecified, evolve over time, and require iterative collaboration between a human and an AI partner. Human goals often shift, constraints are added, and users need ongoing guidance, clarification, and scaffolding. The authors therefore argue that the field should move from “completion‑centric” agents to “collaborative” agents whose performance is judged not only by the quality of the final output but also by how effectively they engage with, support, and amplify human effort throughout a multi‑turn problem‑solving process.
To operationalize this shift, the authors introduce Collaborative Effort Scaling (CES), a quantitative framework that models an agent’s utility U as a function of user involvement E and a scaffolding factor S:
\
📜 Original Paper Content
🚀 Synchronizing high-quality layout from 1TB storage...