An $O(n^3)$ time algorithm for the maximum-weight limited-capacity many-to-many matching
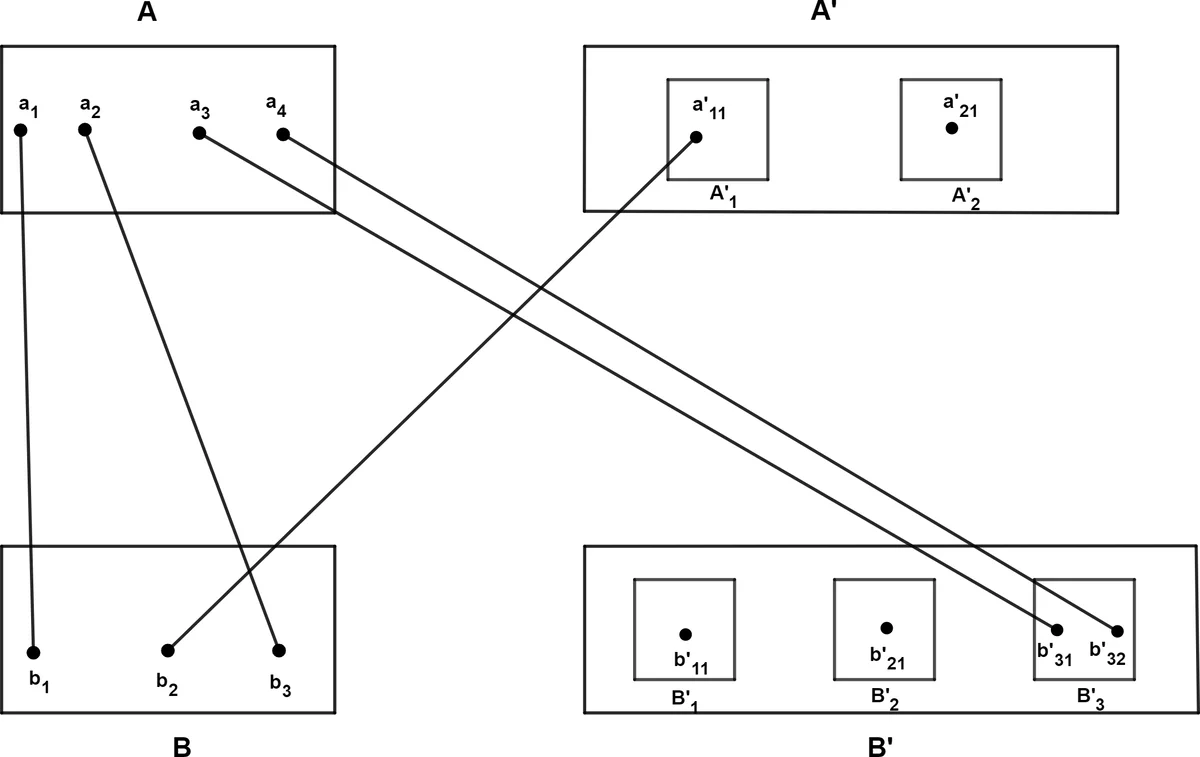
Given an undirected bipartite graph $G=(A \cup B, E)$, a many-to-many matching (MM) in $G$ matches each vertex $v$ in $A$ (resp. $B$) to at least one vertex in $B$ (resp. $A$). In this paper, we consider the limited-capacity many-to-many matching (LCMM) in $G$, where each vertex $v\in A\cup B$ is matched to at least one and at most $Cap(v)$ vertices; the function $Cap : A\cup B \rightarrow \mathbb{Z}> 0$ denotes the capacity of $v$ (an upper bound on its degree in the LCMM). We give an $O(n^3)$ time algorithm for finding a maximum (respectively minimum) weight LCMM in $G$ with non-positive real (respectively non-negative real) edge weights, where $\lvert A \rvert+\lvert B \rvert=n$.
💡 Research Summary
The paper addresses the problem of finding a maximum‑weight limited‑capacity many‑to‑many matching (LCMM) in an undirected bipartite graph G = (A ∪ B, E). In an LCMM each vertex v must be incident to at least one edge and at most Cap(v) edges, where Cap(v) is a positive integer capacity function. The authors focus on the case where edge weights are non‑positive real numbers (for a maximum‑weight problem) or, equivalently, non‑negative real numbers (for a minimum‑weight problem). Their main contribution is an O(n³) time algorithm, where n = |A| + |B|, that computes an optimal LCMM under these weight restrictions.
Background and Motivation
Standard maximum‑weight perfect bipartite matching (MWPBM) can be solved in O(n³) time by the Hungarian algorithm. However, LCMM adds per‑vertex degree bounds, which prevents a direct application of the Hungarian method. Previous work on LCMM with integer weights achieved O(W′√β′ m) time, where W′ is the maximum absolute edge weight, β′ = Σ Cap(v), and m is the number of edges. This bound becomes impractical when weights are real‑valued or when the range of weights is large.
Key Idea: Vertex Replication
The authors transform the LCMM instance into a standard perfect‑matching instance on an expanded bipartite graph G′ = (X ∪ Y, E′). For each vertex a_i ∈ A with capacity α_i they create α_i − 1 copies a′_i1,…,a′_i(α_i−1); similarly for each b_j ∈ B with capacity β_j they create β_j − 1 copies b′_j1,…,b′_j(β_j−1). Edges between original vertices retain their original weights, and every copy inherits the same weight to the opposite side (i.e., W(a_i, b′_jk) = W(a_i, b_j) and W(a′_ik, b_j) = W(a_i, b_j)). Additionally, all copies in A′ are connected to all copies in B′ with zero‑weight edges, forming a complete bipartite subgraph of weight 0. In G′ each vertex must be matched exactly once, so a perfect matching in G′ corresponds precisely to an LCMM in the original graph that respects all capacity bounds.
Modified Hungarian Algorithm
The classic Hungarian algorithm is adapted into a subroutine called ModifiedHungarianAlg. The algorithm proceeds in two phases:
-
Phase I – Matching A: The subroutine is invoked with the target set A ⊆ X. Starting from an empty matching, it repeatedly selects a free vertex a_i ∈ A, builds an alternating tree, and augments the matching until every vertex of A is matched. Because all copies of a given b_j (i.e., the set B′_j) share identical labels and slack values, the implementation treats each B′_j as a single representative vertex, which reduces the per‑iteration work.
-
Phase II – Matching B: Using the matching obtained from Phase I as the initial matching, the subroutine is called again with target set B ⊆ Y. The same procedure matches all vertices of B while preserving feasibility of the labeling. Lemma 2 guarantees that augmentations never increase the total weight, so the weight after Phase II is at most the weight after Phase I.
During each augmentation the algorithm updates vertex labels according to Lemma 1 (the standard Hungarian label‑adjustment rule) and maintains slack values. The alternating tree contains at most O(n) vertices, and each label/slack update costs O(n). Consequently each augmentation runs in O(n²) time, and since at most O(n) augmentations are performed in each phase, the total running time is O(n³).
Correctness Proof
Three lemmas underpin correctness:
- Lemma 1 (standard): Updating labels by the minimum slack α preserves feasibility and adds at least one new equality edge to the equality graph.
- Lemma 2: In a graph with non‑positive edge weights, the weight of the matching never increases after an augmentation.
- Lemma 3: The weight of the LCMM L extracted from the final perfect matching M₂ in G′ satisfies W(L) = W(M₂). The proof shows a one‑to‑one correspondence between edges of M₂ and edges of L, taking into account the zero‑weight edges between copies.
Thus the algorithm returns a maximum‑weight LCMM for non‑positive weights; for non‑negative weights the same algorithm applied to the negated edge weights yields a minimum‑weight LCMM.
Complexity and Practical Considerations
The algorithm’s asymptotic bound matches the classic Hungarian algorithm, but it handles the additional capacity constraints without any extra logarithmic factors or dependence on the magnitude of edge weights. The replication step increases the number of vertices by at most Σ(α_i − 1) + Σ(β_j − 1) ≤ n, so the expanded graph still has O(n) vertices. Moreover, the grouping of identical copies dramatically reduces constant factors in practice. Memory usage is O(n²) in the worst case (to store the full weight matrix of the expanded graph), but sparse representations can be employed when the original graph is sparse.
Applications and Impact
The method is directly applicable to scenarios where each entity can be paired with a bounded number of partners, such as:
- Wireless sensor networks where each base station has limited radio channels and each sensor limited battery life.
- Computational biology where genes or proteins have a limited number of functional interactions.
- Pattern recognition tasks involving many‑to‑many correspondences with capacity limits.
By providing a simple, deterministic O(n³) algorithm that works for real‑valued weights, the paper bridges a gap between theoretical matching algorithms and practical applications that require capacity constraints.
Conclusion
The authors present a clean reduction of the limited‑capacity many‑to‑many matching problem to a perfect matching problem on an expanded bipartite graph, and they show that the classic Hungarian algorithm, with minor modifications, solves the reduced problem in O(n³) time. The work offers both theoretical insight—demonstrating that capacity constraints do not increase the asymptotic complexity for the considered weight regimes—and practical utility, delivering an algorithm that is easy to implement and adaptable to a wide range of real‑world problems.
Comments & Academic Discussion
Loading comments...
Leave a Comment