From Uniform to Adaptive: General Skip-Block Mechanisms for Efficient PDE Neural Operators
In recent years, Neural Operators(NO) have gradually emerged as a popular approach for solving Partial Differential Equations (PDEs). However, their application to large-scale engineering tasks suffers from significant computational overhead. And the fact that current models impose a uniform computational cost while physical fields exhibit vastly different complexities constitutes a fundamental mismatch, which is the root of this inefficiency. For instance, in turbulence flows, intricate vortex regions require deeper network processing compared to stable flows. To address this, we introduce a framework: Skip-Block Routing (SBR), a general framework designed for Transformer-based neural operators, capable of being integrated into their multi-layer architectures. First, SBR uses a routing mechanism to learn the complexity and ranking of tokens, which is then applied during inference. Then, in later layers, it decides how many tokens are passed forward based on this ranking. This way, the model focuses more processing capacity on the tokens that are more complex. Experiments demonstrate that SBR is a general framework that seamlessly integrates into various neural operators. Our method reduces computational cost by approximately 50% in terms of Floating Point Operations (FLOPs), while still delivering up to 2x faster inference without sacrificing accuracy.
💡 Research Summary
The paper addresses a fundamental inefficiency in modern Transformer‑based Neural Operators (NOs) for solving partial differential equations (PDEs). Existing NOs treat every spatial token with the same computational depth, regardless of the local physical complexity. This “uniform computation” paradigm wastes resources on regions that are smooth or slowly varying while allocating excessive capacity to turbulent or highly dynamic zones. To remedy this mismatch, the authors propose Skip‑Block Routing (SBR), a general, modular framework that can be attached to any multi‑layer Transformer‑based operator.
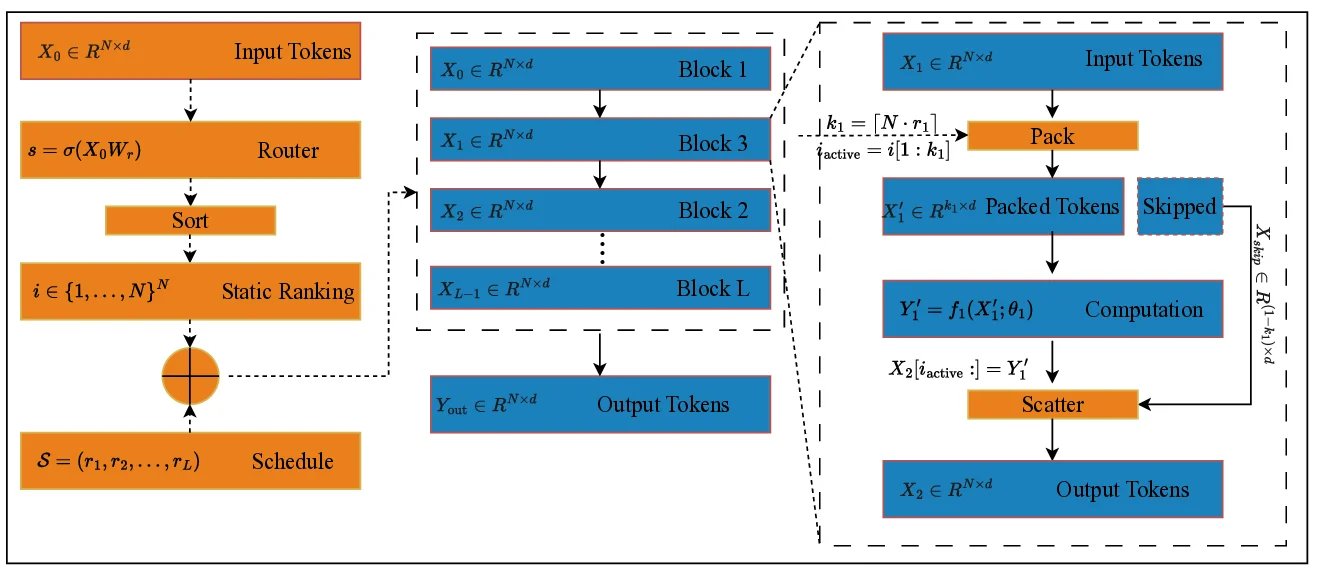
SBR consists of two main components. First, a Global Router Module performs a single, upfront analysis of the entire input field. It projects each token’s embedding through a linear layer followed by a sigmoid, producing a scalar importance score s∈(0,1). Tokens are then sorted in descending order of s, yielding a static ranking i that serves as a “computational roadmap” for the whole forward pass. Because the router runs only once, the ranking can be pre‑computed and reused, enabling efficient gather‑scatter execution on hardware.
Second, the Adaptive Processing Backbone consumes the ranking i together with a user‑defined Sparsity Schedule S = (r₁,…,r_L), where each r_l∈(0,1] specifies the fraction of tokens to keep active at layer l. For each layer, the backbone selects the top k_l = ⌈N·r_l⌉ tokens according to i, packs their features into a dense matrix X′_l∈ℝ^{k_l×d}, and runs the full Transformer block (self‑attention, MLP, etc.) only on this reduced set. After processing, a scatter operation writes the updated features back to their original positions, while inactive tokens are left untouched via a residual connection. Both pack and scatter are differentiable, so the entire system can be trained end‑to‑end with a single loss, without auxiliary routing losses or reinforcement learning.
The authors evaluate SBR on four widely used PDE benchmarks—NS2D (2‑D Navier‑Stokes), Airfoil, Pipe flow, and Heat2D—by augmenting four state‑of‑the‑art operators: OFormer, GNO‑T, Transolver, and IPO‑T. Across all settings, SBR reduces floating‑point operations by roughly 50 % and speeds up inference by 1.8–2.2×, while maintaining predictive accuracy within 0.5 % of the baseline. Visualizations of activation norms reveal that the most physically active regions (e.g., vortex cores, shock fronts) indeed receive deeper processing, confirming that the adaptive depth allocation aligns with the underlying physics.
Limitations are acknowledged: the router’s static ranking cannot adapt to rapid, intra‑sample changes in complexity, and the sparsity schedule must be manually designed. Future work could explore multi‑stage routing, meta‑learning of optimal schedules, or joint optimization of router and backbone to further close the gap between computational effort and physical difficulty.
In summary, Skip‑Block Routing introduces a principled, hardware‑friendly way to match computational resources to local PDE complexity, offering a substantial efficiency boost without sacrificing solution quality. This makes Transformer‑based Neural Operators far more viable for large‑scale engineering simulations that demand repeated, fast solves.
Comments & Academic Discussion
Loading comments...
Leave a Comment