Speeding Up MACE: Low-Precision Tricks for Equivarient Force Fields
📝 Original Info
- Title: Speeding Up MACE: Low-Precision Tricks for Equivarient Force Fields
- ArXiv ID: 2510.23621
- Date: 2025-10-23
- Authors: Alexandre Benoit
📝 Abstract
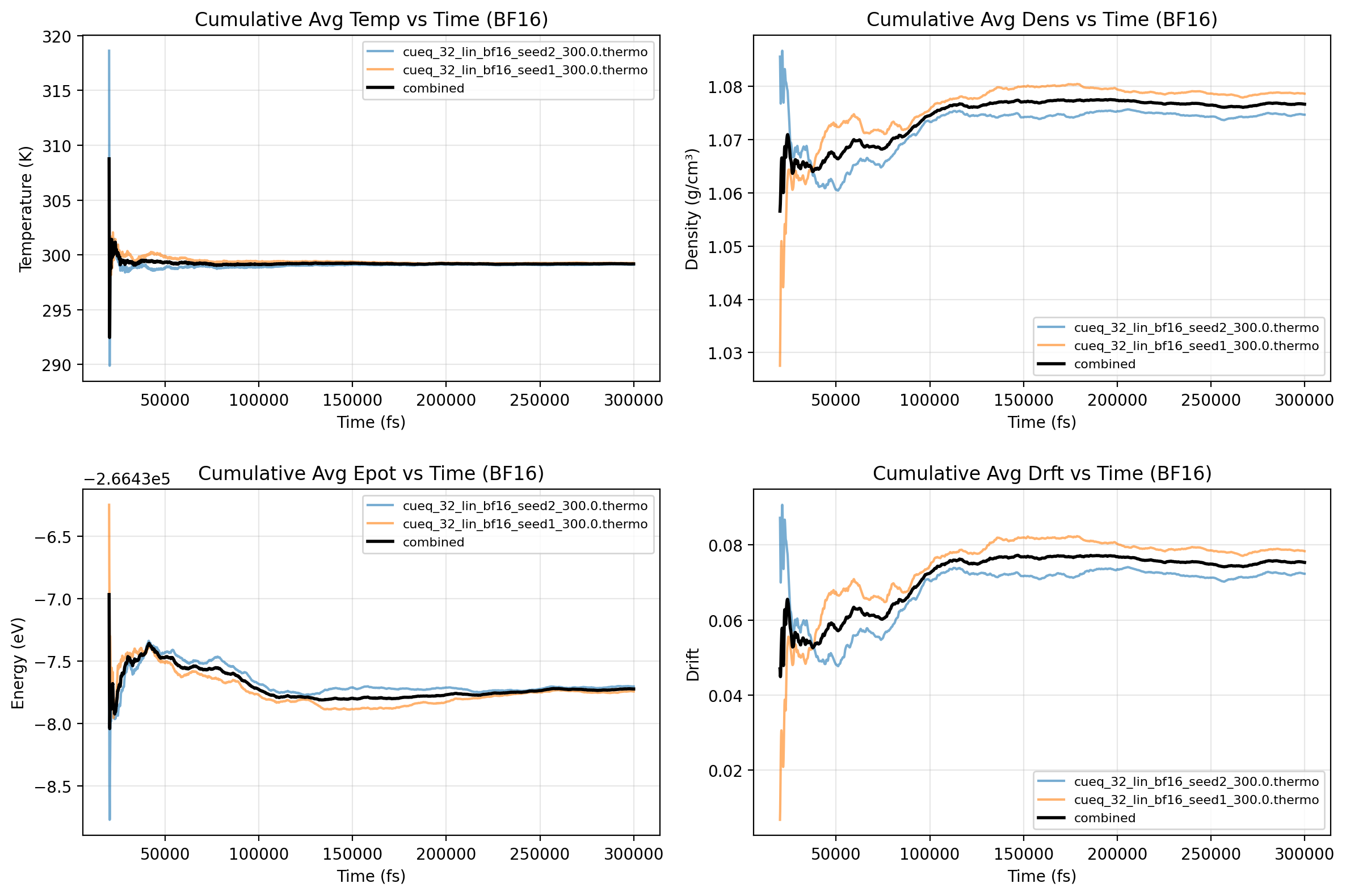
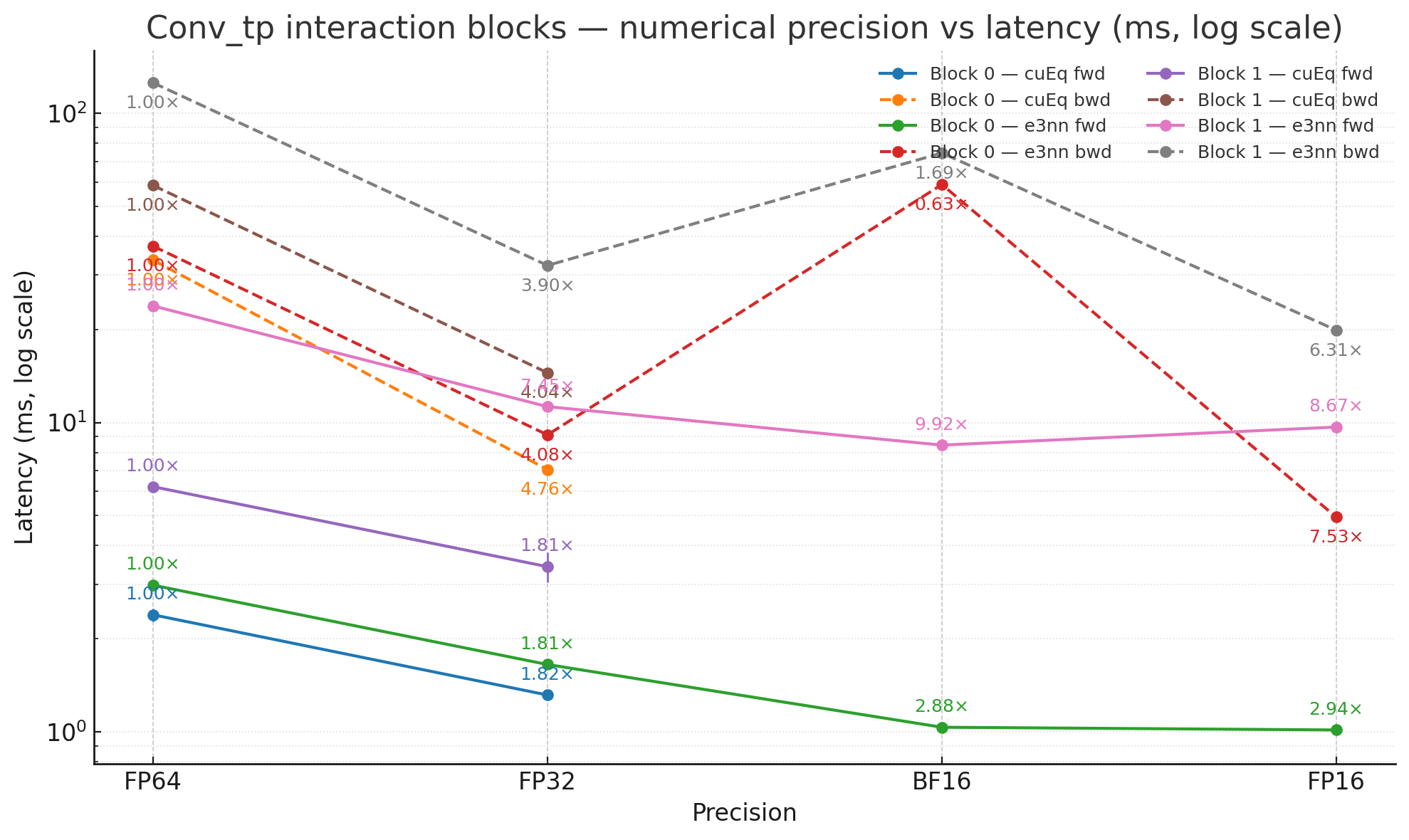
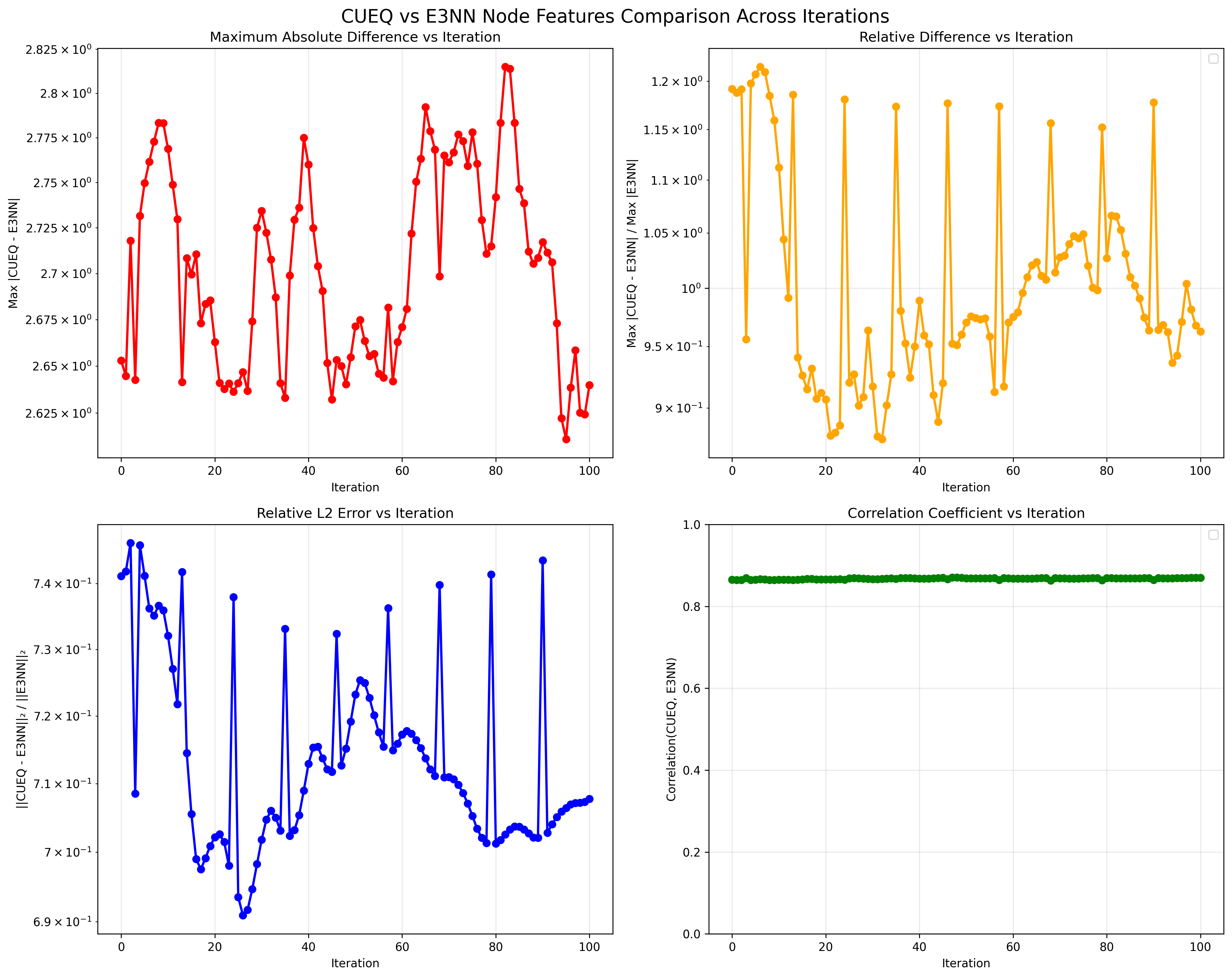
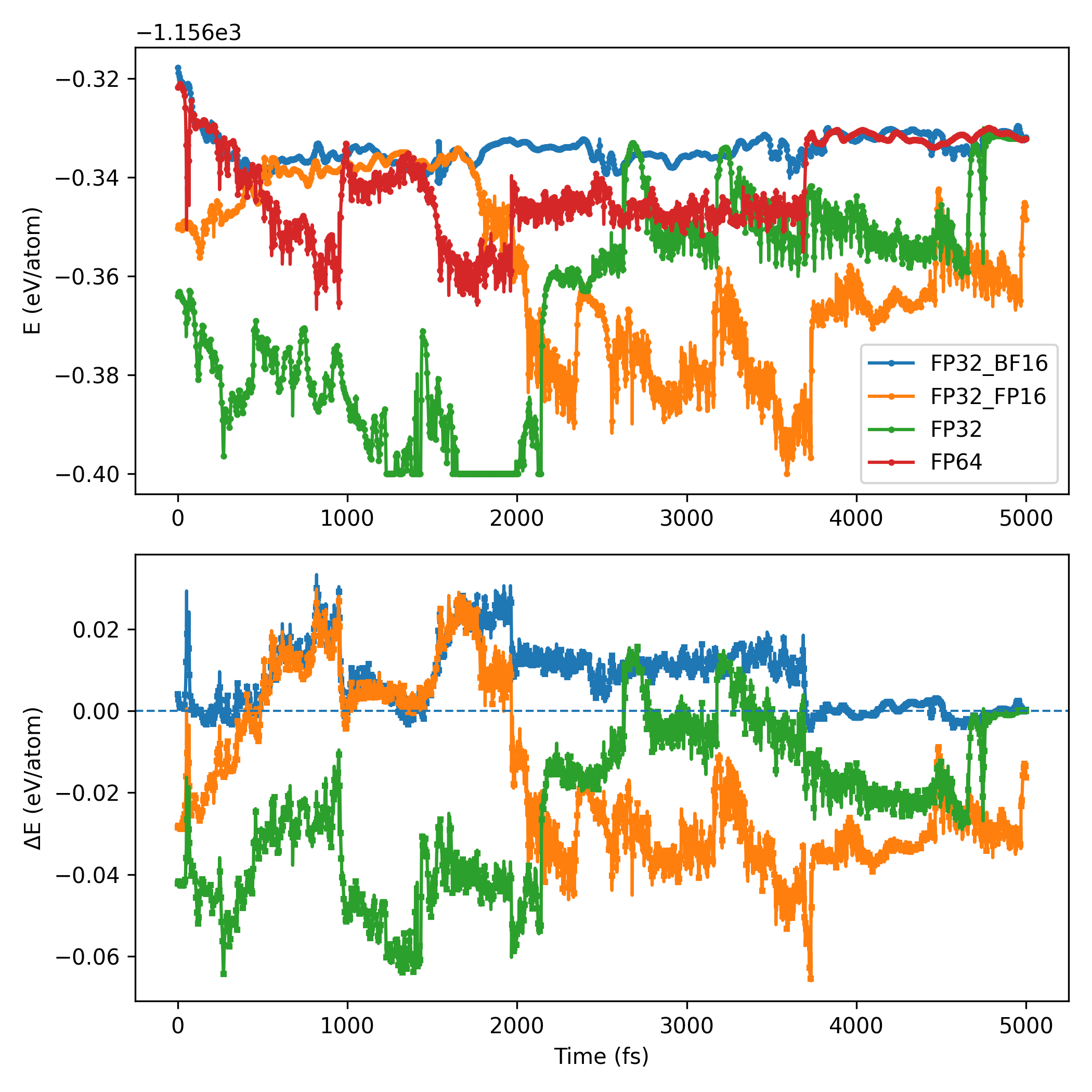
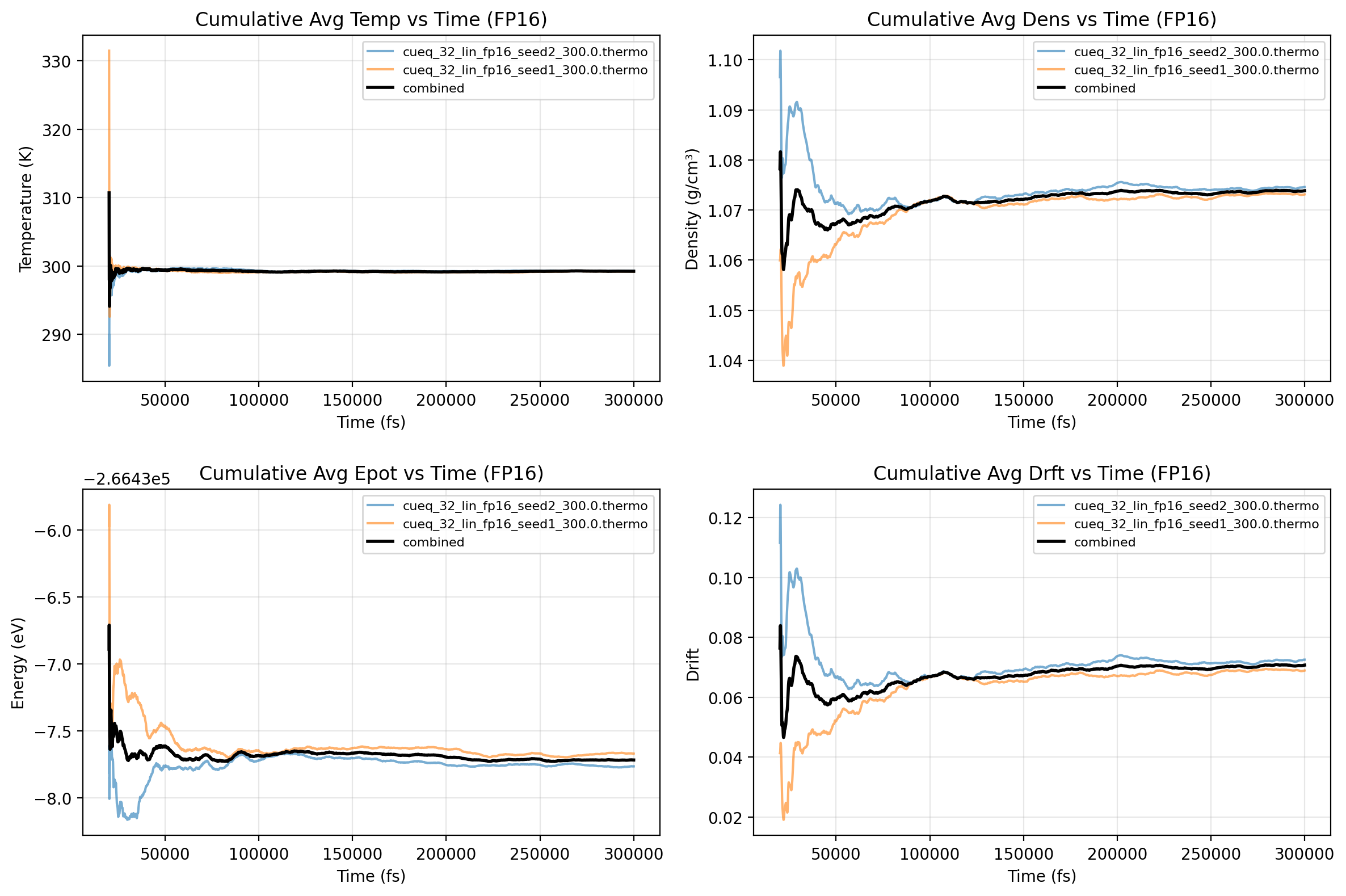
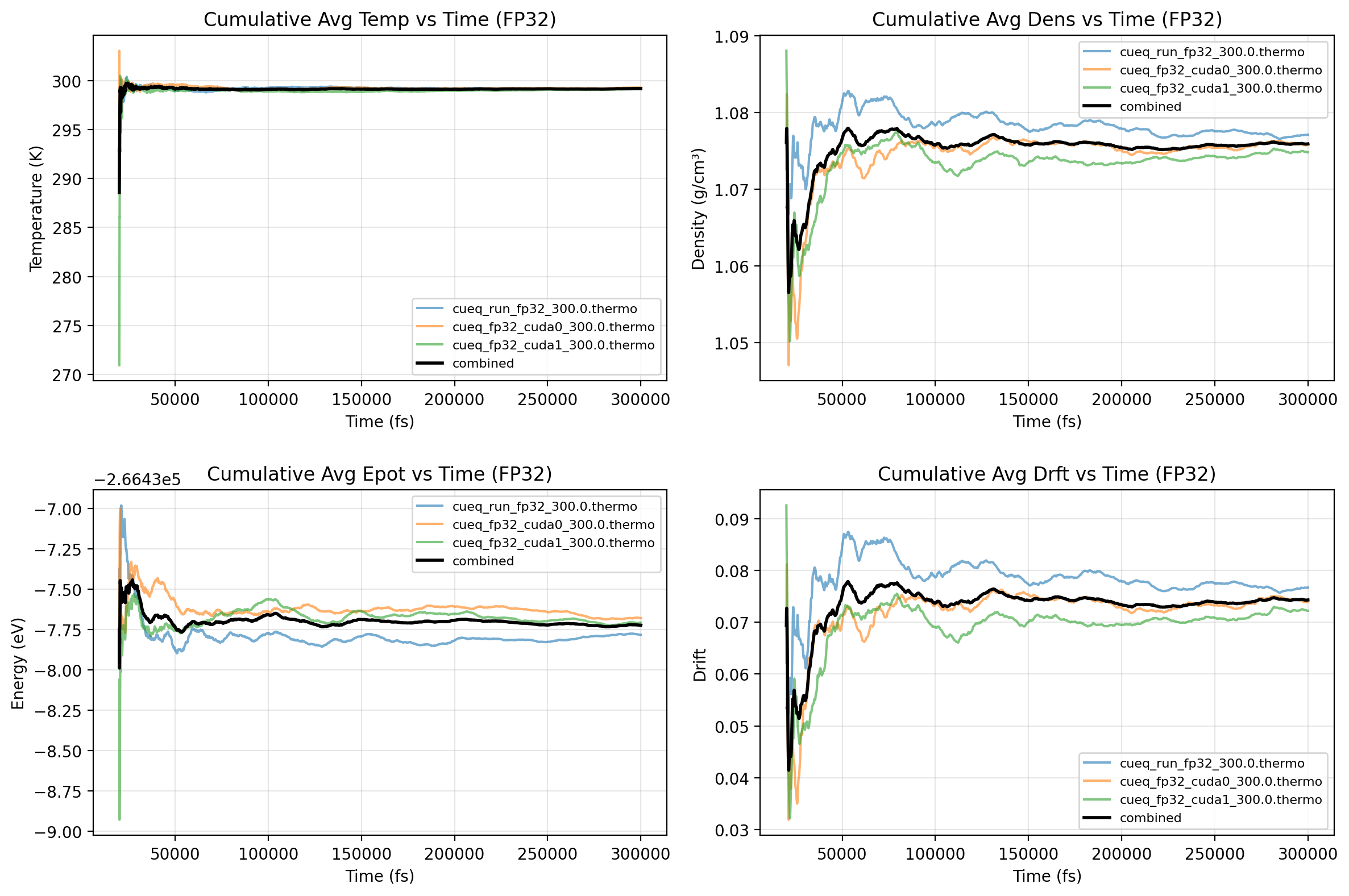
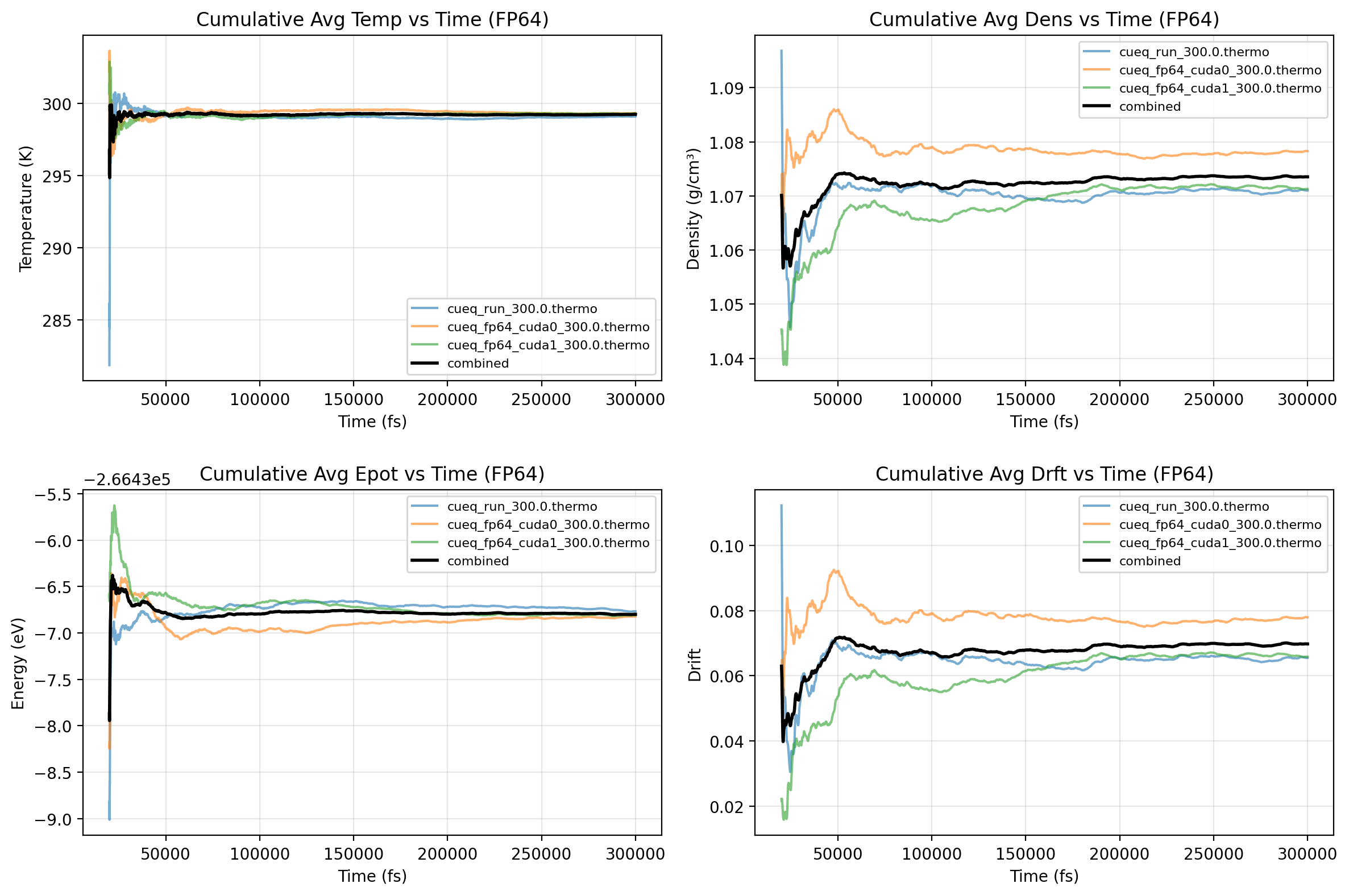
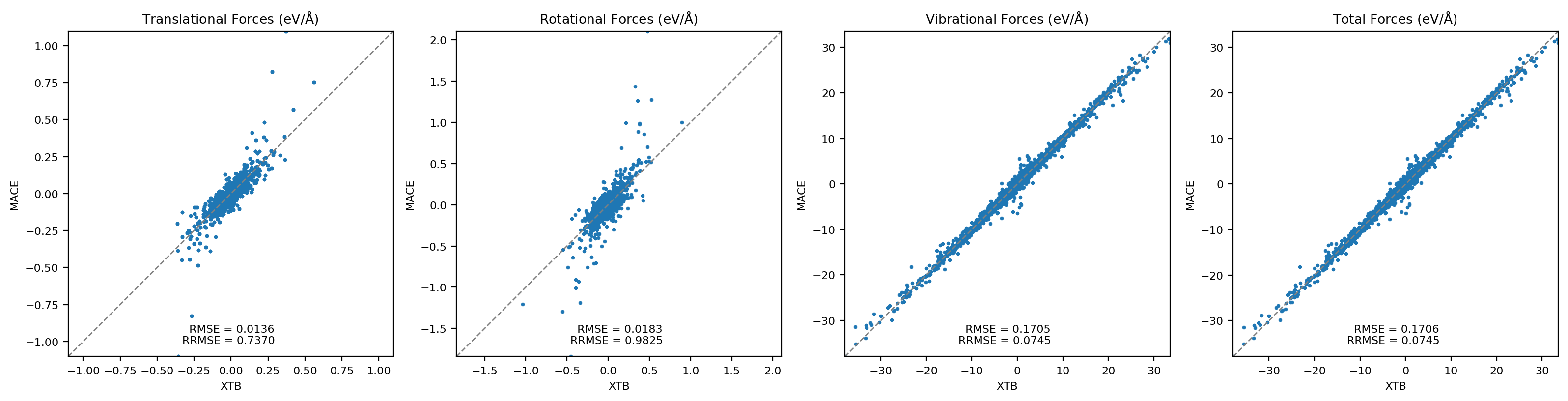
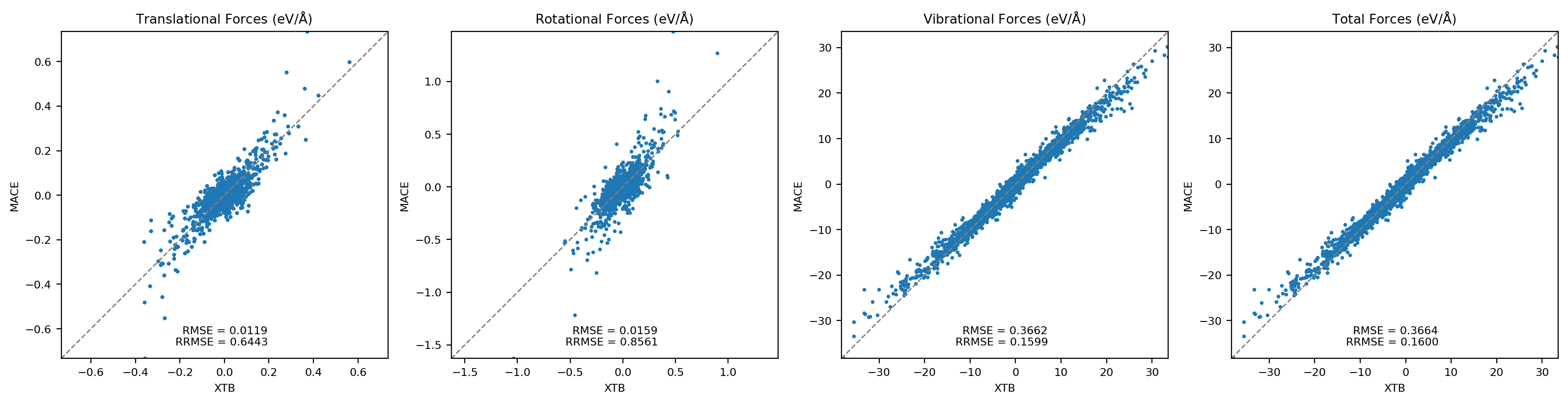
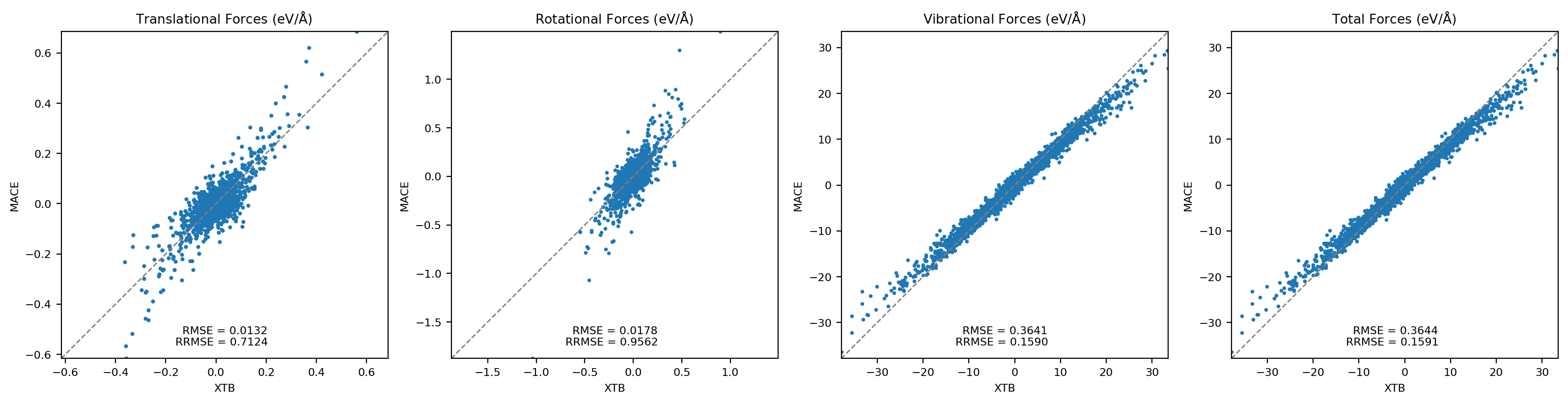
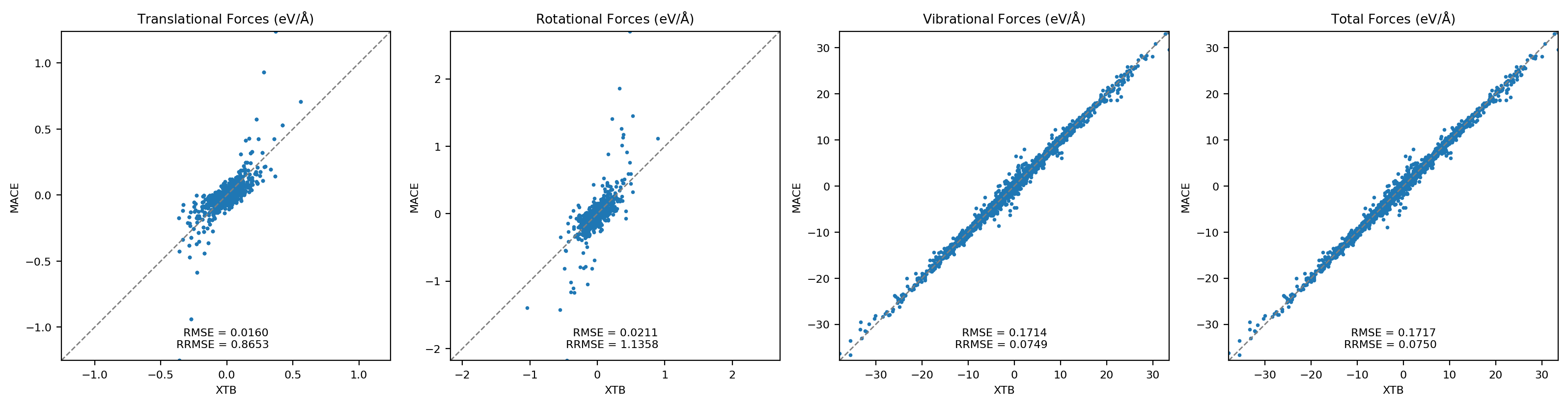
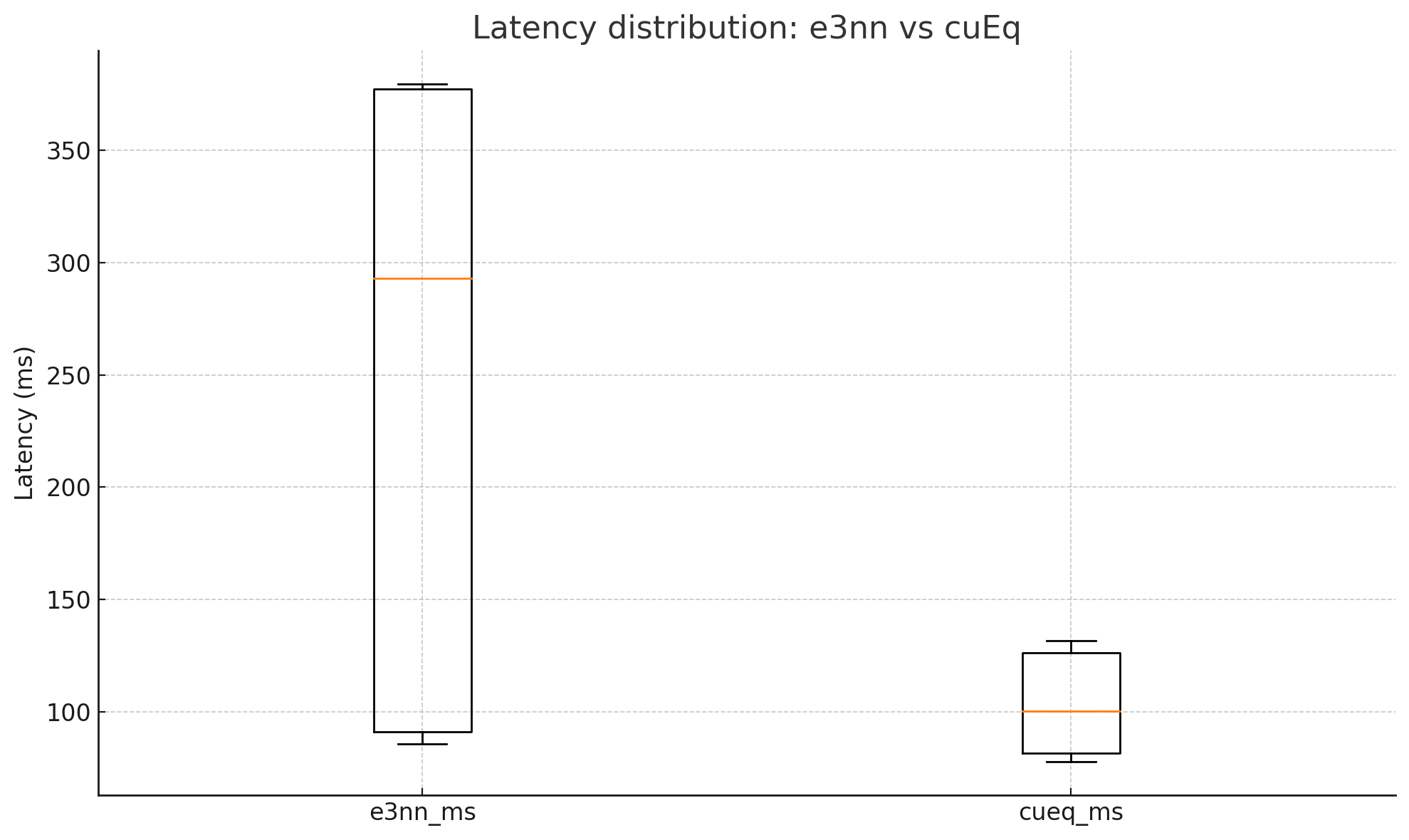
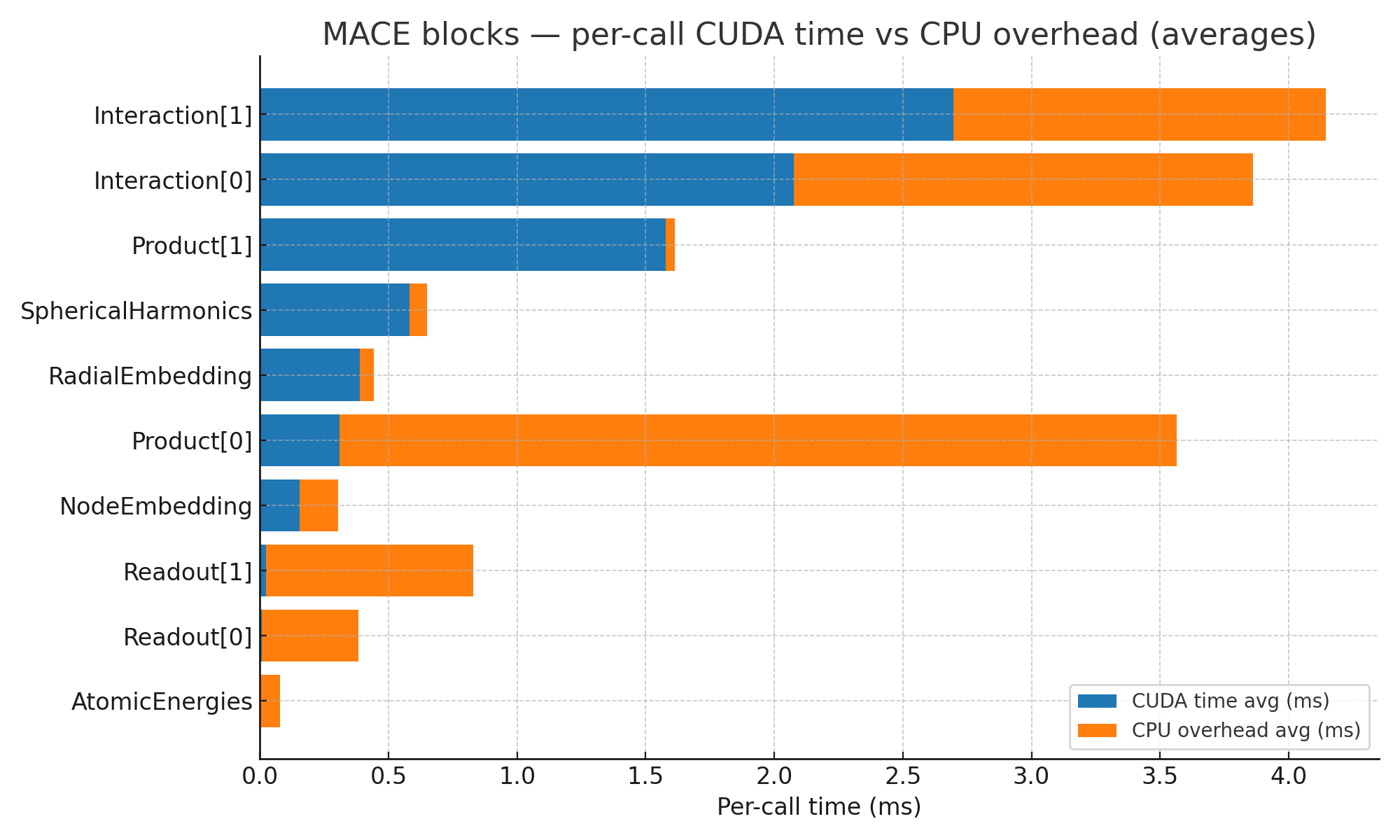
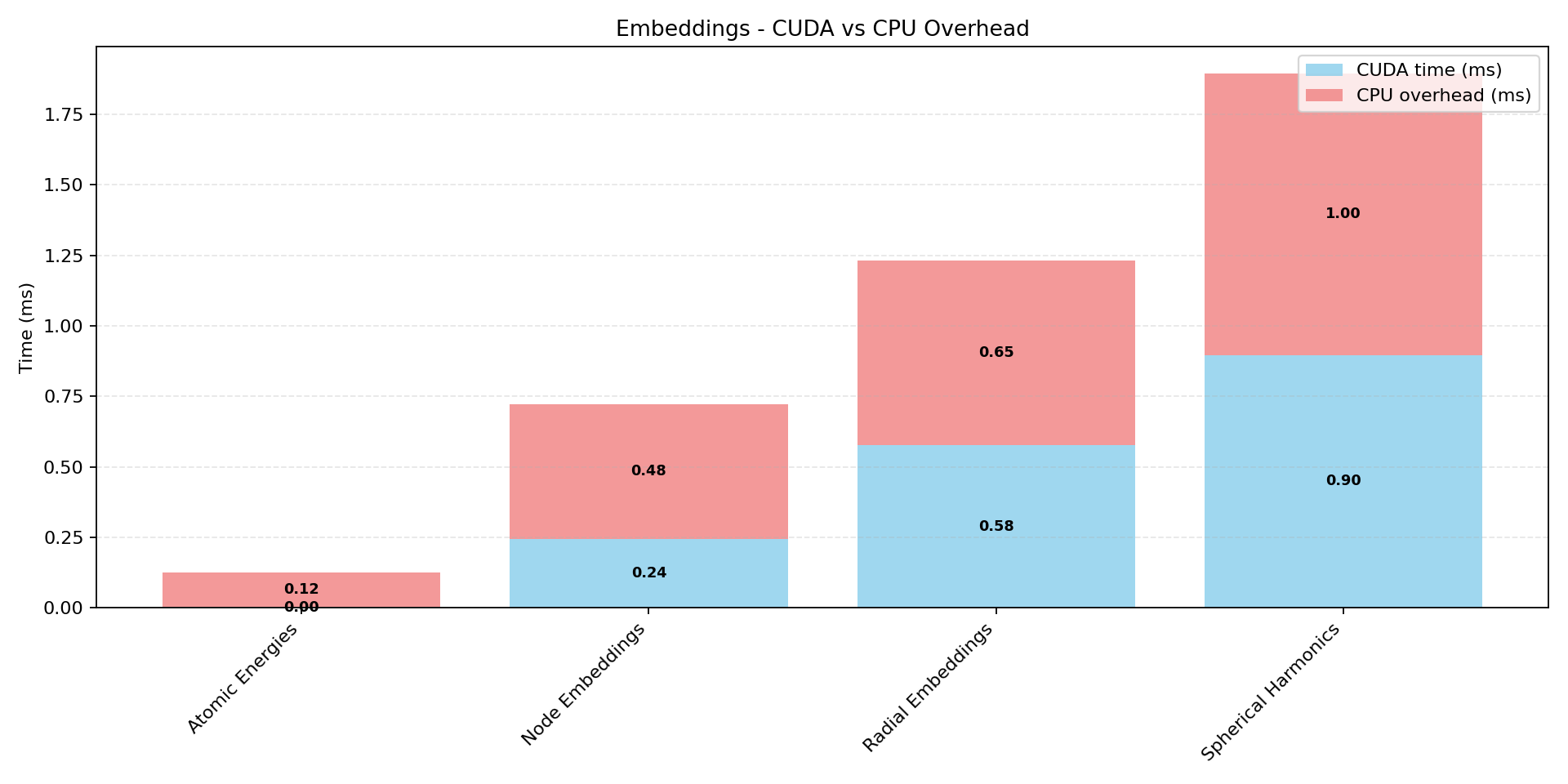
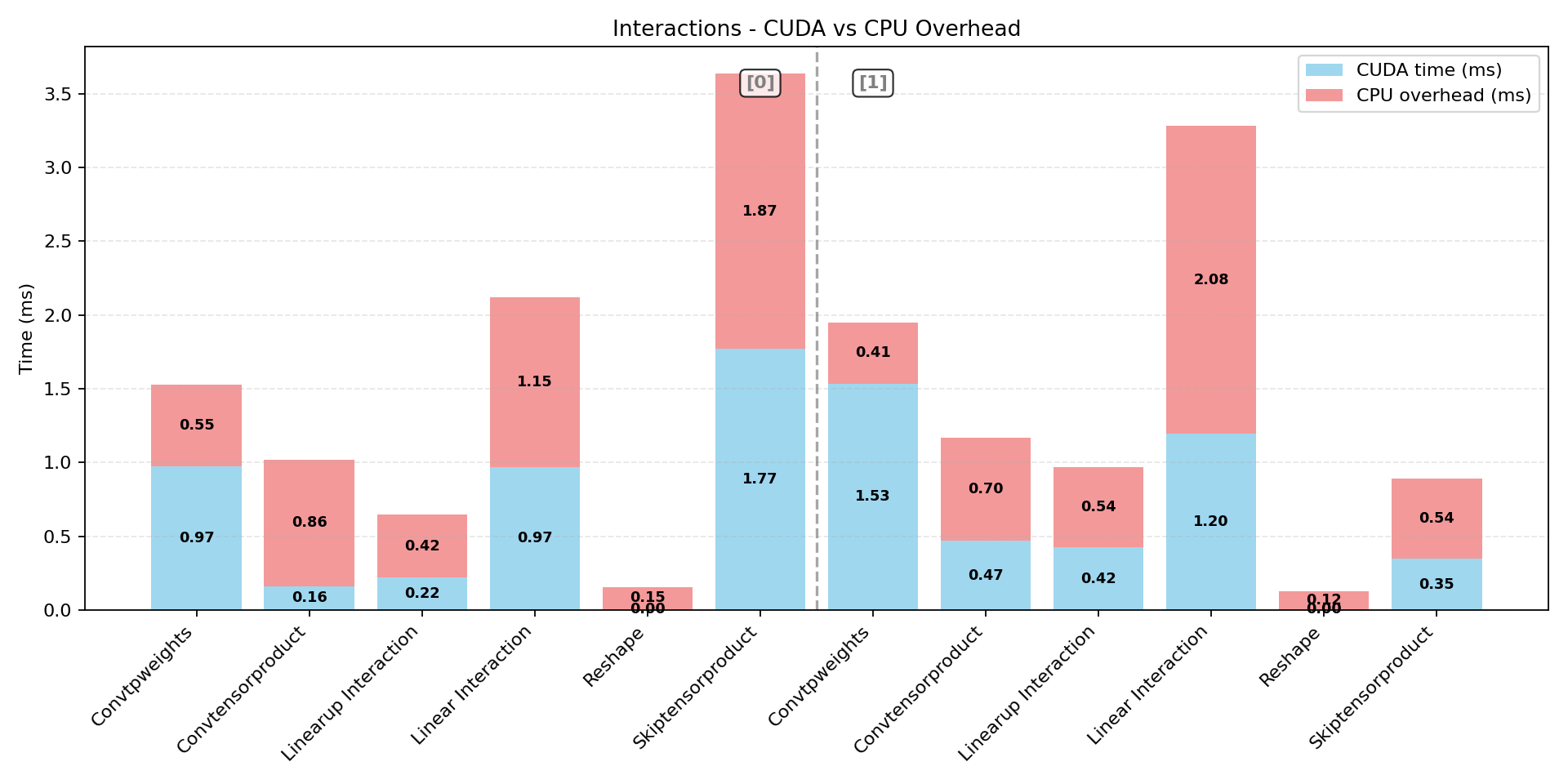
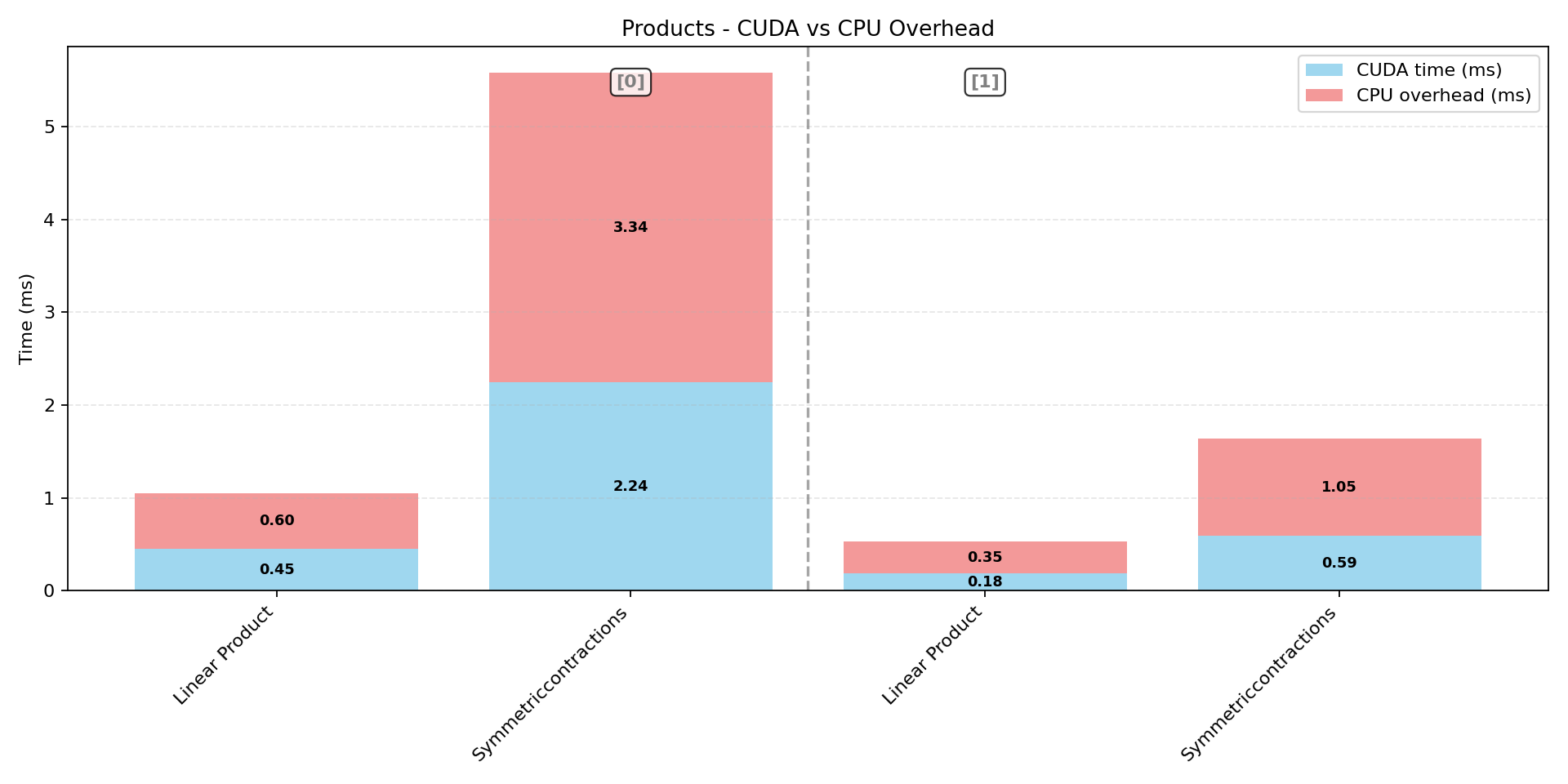
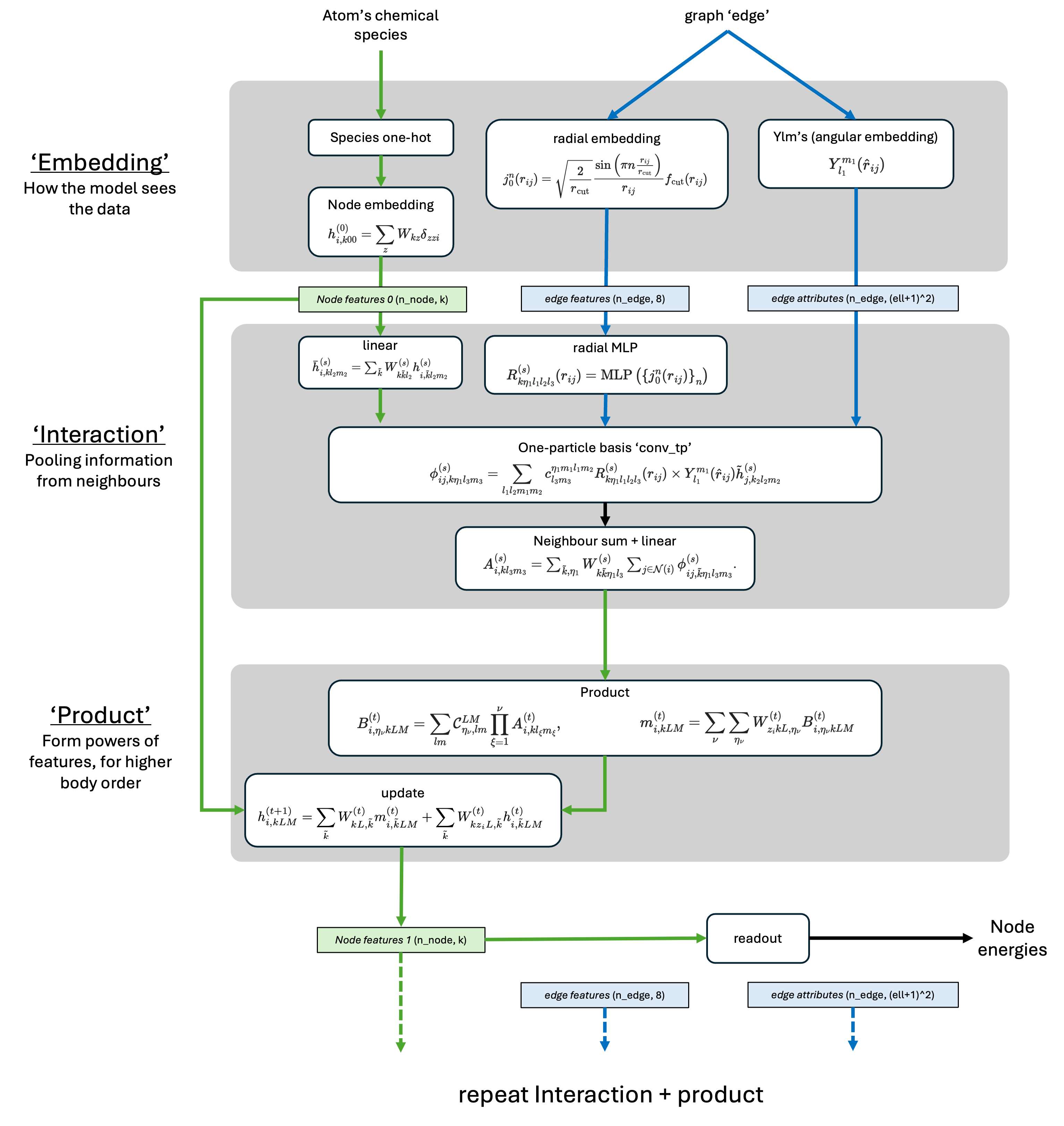
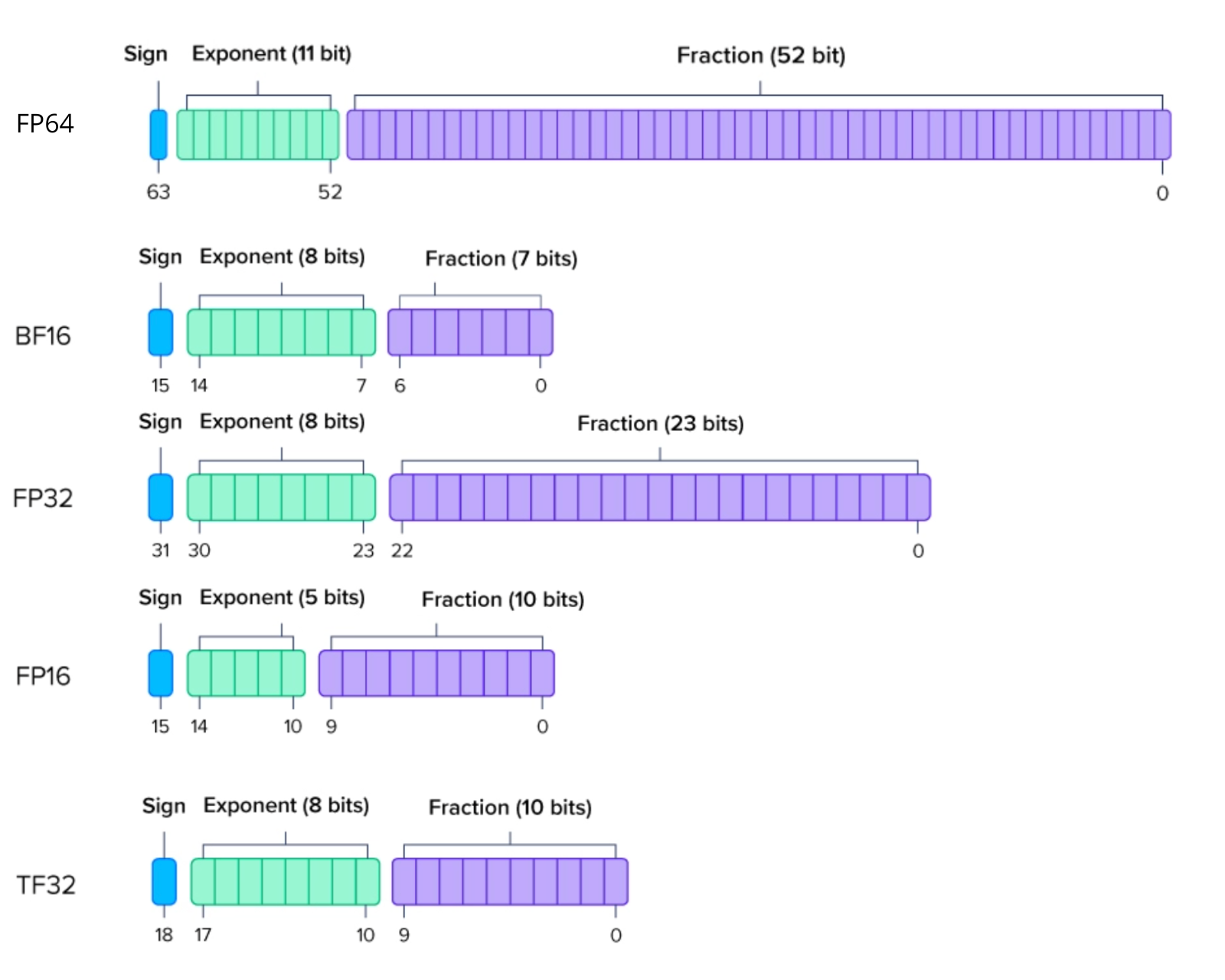
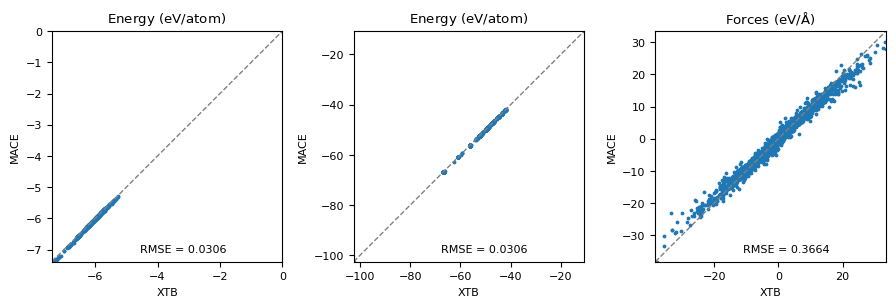
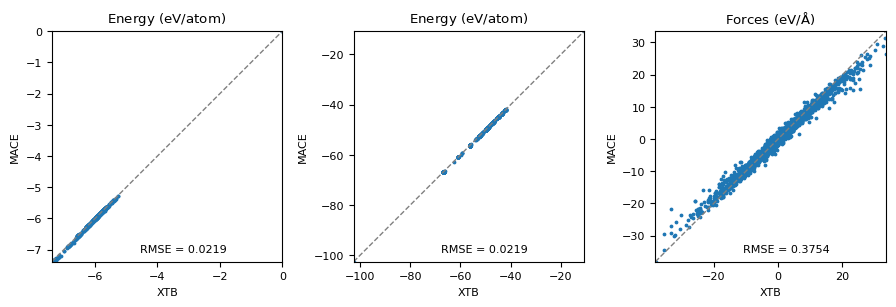
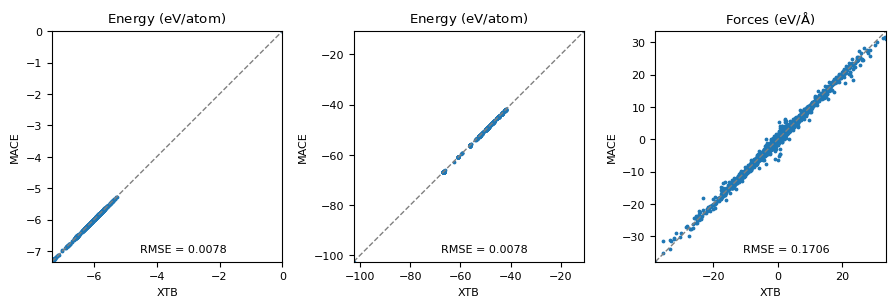
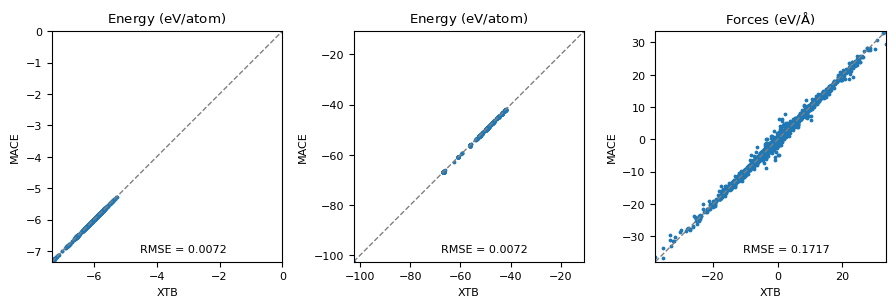
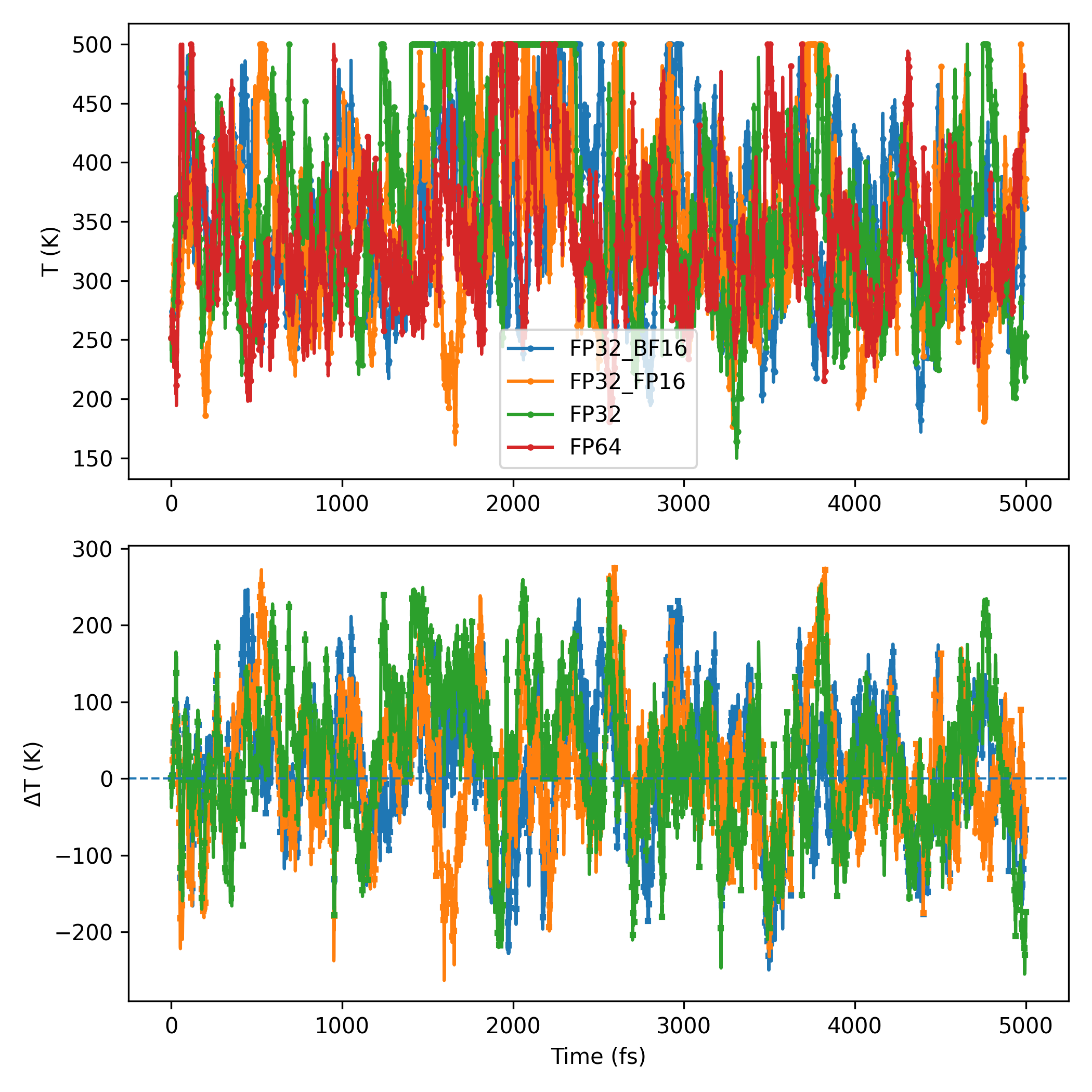
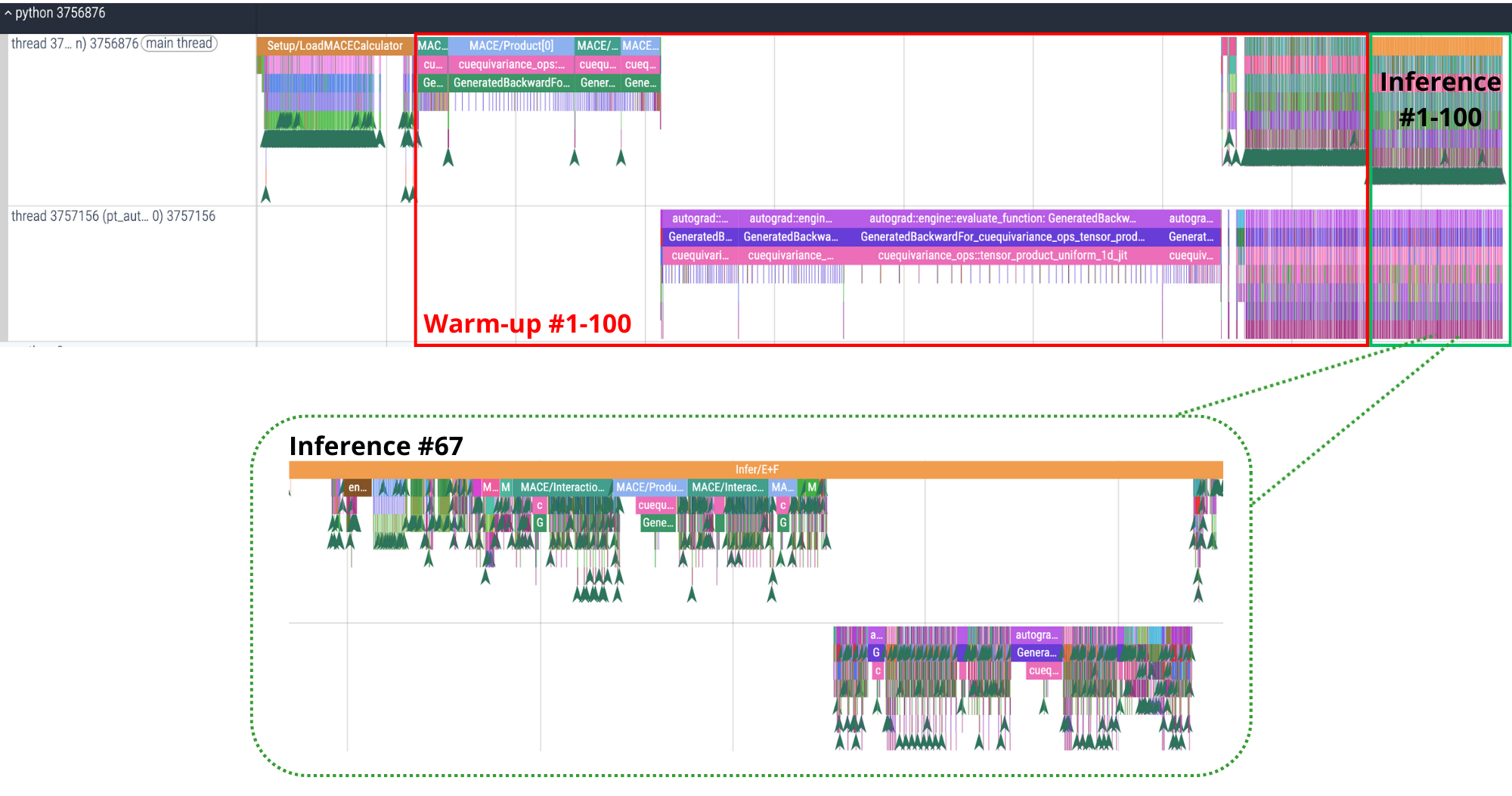
Machine-learning force fields can deliver accurate molecular dynamics (MD) at high computational cost. For SO(3)-equivariant models such as MACE, there is little systematic evidence on whether reduced-precision arithmetic and GPU-optimized kernels can cut this cost without harming physical fidelity. This thesis aims to make MACE cheaper and faster while preserving accuracy by identifying computational bottlenecks and evaluating low-precision execution policies. We profile MACE end-to-end and per block, compare the e3nn and NVIDIA cuEquivariance backends, and assess FP64/FP32/BF16/FP16 settings (with FP32 accumulation) for inference, short NVT and long NPT water simulations, and toy training runs under reproducible, steady-state timing. cuEquivariance reduces inference latency by about $3\times$. Casting only linear layers to BF16/FP16 within an FP32 model yields roughly 4x additional speedups, while energies and thermodynamic observables in NVT/NPT MD remain within run-to-run variability. Half-precision weights during training degrade force RMSE. Mixing e3nn and cuEq modules without explicit adapters causes representation mismatches. Fused equivariant kernels and mixed-precision inference can substantially accelerate state-of-the-art force fields with negligible impact on downstream MD. A practical policy is to use cuEquivariance with FP32 by default and enable BF16/FP16 for linear layers (keeping FP32 accumulations) for maximum throughput, while training remains in FP32. Further gains are expected on Ampere/Hopper GPUs (TF32/BF16) and from kernel-level FP16/BF16 paths and pipeline fusion.💡 Deep Analysis
Deep Dive into Speeding Up MACE: Low-Precision Tricks for Equivarient Force Fields.Machine-learning force fields can deliver accurate molecular dynamics (MD) at high computational cost. For SO(3)-equivariant models such as MACE, there is little systematic evidence on whether reduced-precision arithmetic and GPU-optimized kernels can cut this cost without harming physical fidelity. This thesis aims to make MACE cheaper and faster while preserving accuracy by identifying computational bottlenecks and evaluating low-precision execution policies. We profile MACE end-to-end and per block, compare the e3nn and NVIDIA cuEquivariance backends, and assess FP64/FP32/BF16/FP16 settings (with FP32 accumulation) for inference, short NVT and long NPT water simulations, and toy training runs under reproducible, steady-state timing. cuEquivariance reduces inference latency by about $3\times$. Casting only linear layers to BF16/FP16 within an FP32 model yields roughly 4x additional speedups, while energies and thermodynamic observables in NVT/NPT MD remain within run-to-run variabili
📄 Full Content
📸 Image Gallery