LyriCAR: A Difficulty-Aware Curriculum Reinforcement Learning Framework For Controllable Lyric Translation
💡 Research Summary
LyriCAR addresses the notoriously difficult task of lyric translation, where preserving musicality (rhythm, rhyme, format) must be balanced with semantic fidelity. Existing approaches rely heavily on handcrafted constraints, sentence‑level modeling, or require large amounts of parallel lyric‑melody data, limiting their ability to capture paragraph‑level rhyme patterns and to scale efficiently. LyriCAR proposes a fully unsupervised, end‑to‑end framework that integrates a difficulty‑aware curriculum, multi‑dimensional reward‑based reinforcement learning, and an adaptive curriculum‑switching mechanism guided by reward convergence.
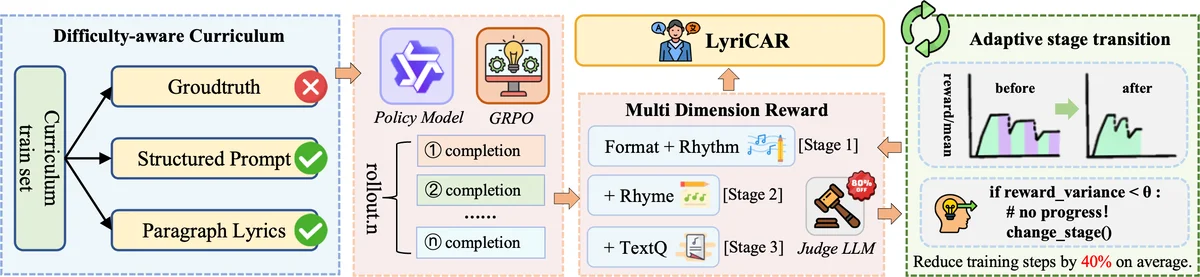
The curriculum designer quantifies the intrinsic linguistic complexity of each raw English lyric paragraph using BERT‑perplexity and LIWC‑inspired lexical, syntactic, and rhyme‑density features. Paragraphs are stratified into Easy, Medium, and Hard tiers, each providing 9,600 samples per stage. This stratification enables a progressive “easy‑to‑hard” training schedule without any manual annotations or alignment information.
For reinforcement learning, the large language model Qwen‑3‑8B is fine‑tuned. Four reward functions are defined: (i) format compliance (preserving special sentence‑boundary tokens), (ii) rhythm compliance (matching target syllable count), (iii) rhyme compliance (encouraging consistent rhyme across adjacent lines), and (iv) text‑quality compliance (evaluated by a prompt‑based Judge LLM that outputs a discrete score of –1, 0, or 1). The overall reward is a weighted sum of these components. Rather than applying these signals as external penalties, LyriCAR adopts Group Relative Policy Optimization (GRPO), which computes a relative advantage for each candidate within a sampled group by subtracting the group’s mean reward. The policy is then updated to maximize the expected relative advantage, allowing the model to internally learn trade‑offs among competing objectives.
Training efficiency is further enhanced by a convergence‑guided curriculum adaptation strategy. After every fixed interval of epochs, the variance of validation rewards over a sliding window is monitored. If the variance stays below a pre‑determined threshold for a patience of k epochs, the current curriculum stage is considered “converged” and the training proceeds to the next, more difficult tier. This self‑paced progression mirrors human tutoring: the model spends most of its capacity on easy data until mastery, then shifts resources to harder data precisely when needed.
Experiments use the DALI dataset, extracting English lyrics from 6,984 songs and constructing EN‑ZH parallel test sets. Training runs on eight NVIDIA A800 (80 GB) GPUs with stage‑specific learning rates (1e‑6 → 5e‑7 → 1e‑7) and KL‑loss coefficients (0.01 → 0.05 → 0.1). Results show that LyriCAR outperforms strong baselines—including the base Qwen‑3‑8B model—on BLEU (up to 21.37 vs. 16.87) and COMET (81.12 vs. 77.37). In the multi‑dimensional reward evaluation, LyriCAR‑SD (dynamic curriculum) achieves the highest scores for rhythm (0.70), rhyme (0.77), and text quality (0.7), while reducing total training steps by roughly 34 % compared to a static curriculum. Ablation studies confirm that full‑data training without curriculum plateaus at a reward of ~0.5, whereas curriculum‑based training reaches ~0.7 and converges faster.
In summary, LyriCAR demonstrates that (1) difficulty‑aware data stratification, (2) carefully designed multi‑dimensional rewards, (3) group‑relative policy optimization, and (4) reward‑convergence‑driven adaptive curricula together enable a model to internalize complex musical‑linguistic patterns without any supervision. This yields state‑of‑the‑art lyric translation quality while markedly improving computational efficiency, offering a scalable blueprint for future research in musically informed language generation.
Comments & Academic Discussion
Loading comments...
Leave a Comment