Direct Preference Optimization with Unobserved Preference Heterogeneity: The Necessity of Ternary Preferences
💡 Research Summary
This paper tackles a fundamental limitation of current Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO): the implicit assumption that all users share the same preference distribution. In reality, users differ along cultural, political, and personal dimensions, and a single reward model or policy inevitably favors majority preferences while marginalizing minority groups. Existing attempts to address heterogeneity—such as learning multiple reward models, multi‑dimensional reward functions, or hierarchical RL—either require costly multi‑dimensional annotations, pre‑specified objectives, or expensive reinforcement‑learning pipelines.
The authors first ask a theoretical question: under what observation model can latent user types be identified? By borrowing the Bradley‑Terry‑Luce framework from econometrics, they prove that binary comparisons (choosing the better of two responses) are insufficient for identifying a finite set of latent preference types, even with infinite data. In contrast, a single ternary choice (selecting the preferred response among three or more candidates) provides enough information for identifiability under a simple linear reward model. This result establishes a clear data‑collection prescription: ask annotators to rank at least three alternatives.
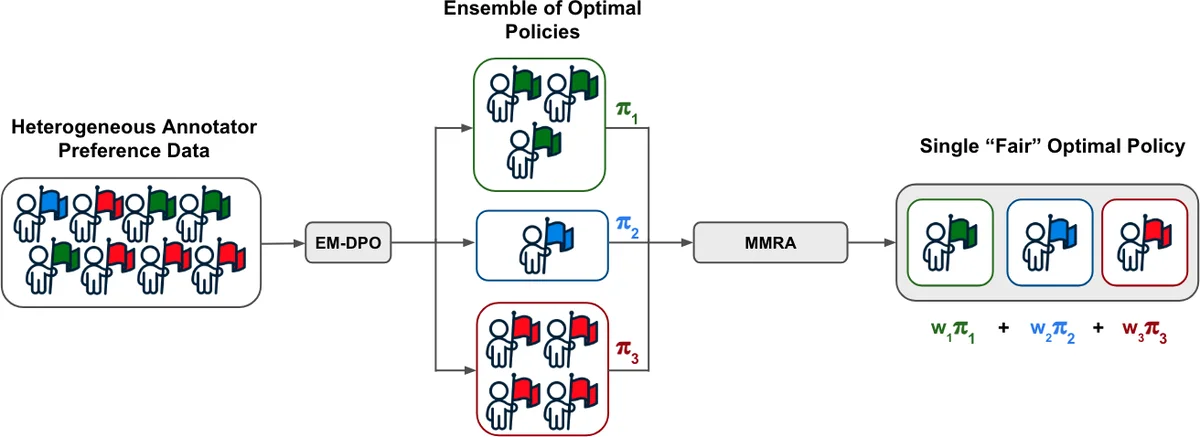
Building on this insight, they introduce EM‑DPO (Expectation‑Maximization Direct Preference Optimization). The method assumes a finite K latent types Z∈{z₁,…,z_K}. Given an offline dataset of annotator‑level preferences D, EM‑DPO iteratively (1) computes posterior responsibilities γ_{i,k} for each annotator i (E‑step) using the current type‑specific policies π_{k}, and (2) updates the mixture weights η_k and the policy parameters for each type by maximizing a weighted DPO objective (M‑step). The algorithm thus simultaneously discovers hidden annotator clusters and learns a dedicated language model for each cluster, without requiring explicit group labels. The framework supports either completely separate policy parameters per type or shared parameters with type‑specific heads, offering a trade‑off between model capacity and computational cost.
After obtaining K type‑specific policies {π*k}, the next challenge is to deploy a single model that serves an unknown mixture of users at inference time. The authors formulate a fairness criterion based on min‑max regret: for each type k define regret R_k(π)=E{π*_k}
Comments & Academic Discussion
Loading comments...
Leave a Comment