MTmixAtt: Integrating Mixture-of-Experts with Multi-Mix Attention for Large-Scale Recommendation
💡 Research Summary
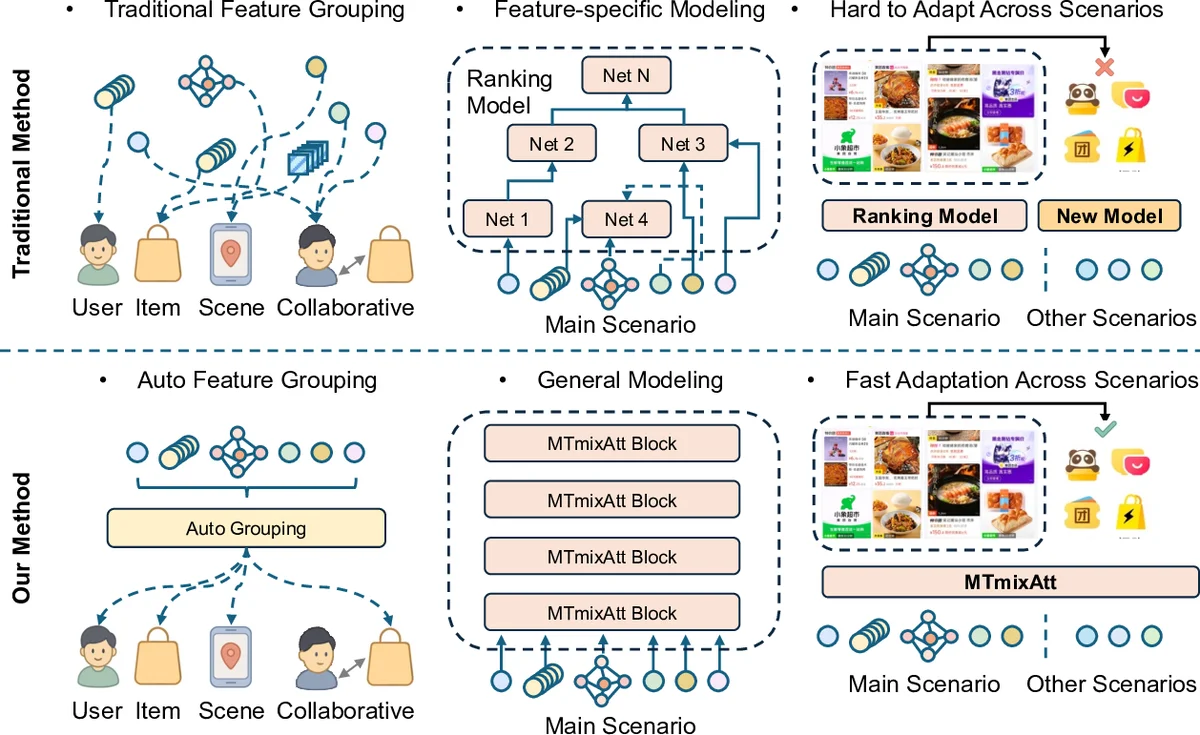
The paper introduces MTmixAtt, a unified Mixture‑of‑Experts (MoE) architecture designed for large‑scale industrial recommendation ranking. Traditional ranking pipelines in industry still rely on manual feature engineering, scenario‑specific network designs, and separate models for each business scenario, which hampers cross‑scenario transfer and limits scalability. MTmixAtt addresses these issues through two tightly coupled components: (1) an Auto Token module that automatically clusters heterogeneous input features into semantically coherent tokens, and (2) an MTmixAttBlock that performs token interaction using a learnable mixing matrix, a shared dense MoE, and scenario‑aware sparse experts.
The Auto Token module first projects each raw feature through a dedicated DNN to a unified embedding dimension. A learnable selection matrix W is then used to pick the top‑k features for each token; the top‑k scores are softmax‑normalized, making the clustering differentiable and end‑to‑end trainable. This eliminates the need for hand‑crafted grouping rules and adapts automatically to data distribution shifts.
MTmixAttBlock builds on the token representations. After transposing the token matrix, it splits the data into H attention heads. For each head, a learnable mixing matrix W_h operates on the token dimension, enabling head‑wise token mixing. Residual connections preserve the original token information. The mixed outputs from all heads are concatenated to form the final token representation.
Following token mixing, a shared dense MoE layer allocates different experts to different token patterns. Each feed‑forward expert is further divided into m sub‑experts, increasing the number of experts without increasing overall compute. This fine‑grained expert splitting enhances representation diversity and captures inter‑group dependencies that static token grouping cannot.
Finally, scenario‑specific sparse MoE layers are introduced. The main scenario primarily uses the shared dense experts, while auxiliary scenarios activate a set of sparse experts selected by a router conditioned on the scenario label. This design enables a single model to adapt quickly across multiple business scenarios without retraining.
Extensive offline experiments on the large‑scale TRec dataset from Meituan show that MTmixAtt consistently outperforms strong baselines—including Transformer‑based models, WuKong, HiFormer, MLP‑Mixer, and RankMixer—across CTR and CTCVR metrics. Scaling the model up to 1 billion parameters yields monotonic performance gains, confirming favorable scaling laws. Ablation studies demonstrate that removing either the Auto Token module or the shared dense MoE leads to noticeable drops in performance, underscoring the importance of each component.
Online A/B testing in Meituan’s production environment further validates the approach: in the Homepage scenario, MTmixAtt increases payment page PV by +3.62% and actual payment GTV by +2.54%, delivering tangible business value. The authors conclude that MTmixAtt provides a unified, scalable solution that simultaneously handles automatic feature grouping, heterogeneous feature modeling, and multi‑scenario adaptation. Future work includes extending the framework to multimodal inputs and exploring meta‑learning for router optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment