Generative human motion mimicking through feature extraction in denoising diffusion settings
💡 Research Summary
The paper introduces an interactive dance generation system that enables a human performer to “dance” with an AI avatar using only single‑person motion‑capture data. Rather than relying on costly duet datasets that encode human‑human coordination, the authors propose a framework that extracts high‑level features from solo motion sequences and uses them to guide a generative model. The core generative engine is the EDGE architecture, a conditional denoising diffusion model originally designed for music‑conditioned dance synthesis. In this work the audio conditioning is removed, leaving a pure motion diffusion backbone.
To achieve interactive behavior, the motion stream is split into low‑frequency (LF) and high‑frequency (HF) components via a low‑pass filter φ_L and a complementary high‑pass filter φ_H. The LF component of the incoming human performer’s motion is continuously copied into the generation process, ensuring temporal alignment and “mimicry.” The HF component, which encodes rapid stylistic nuances, is sampled from the diffusion model, allowing the AI to introduce creative variations.
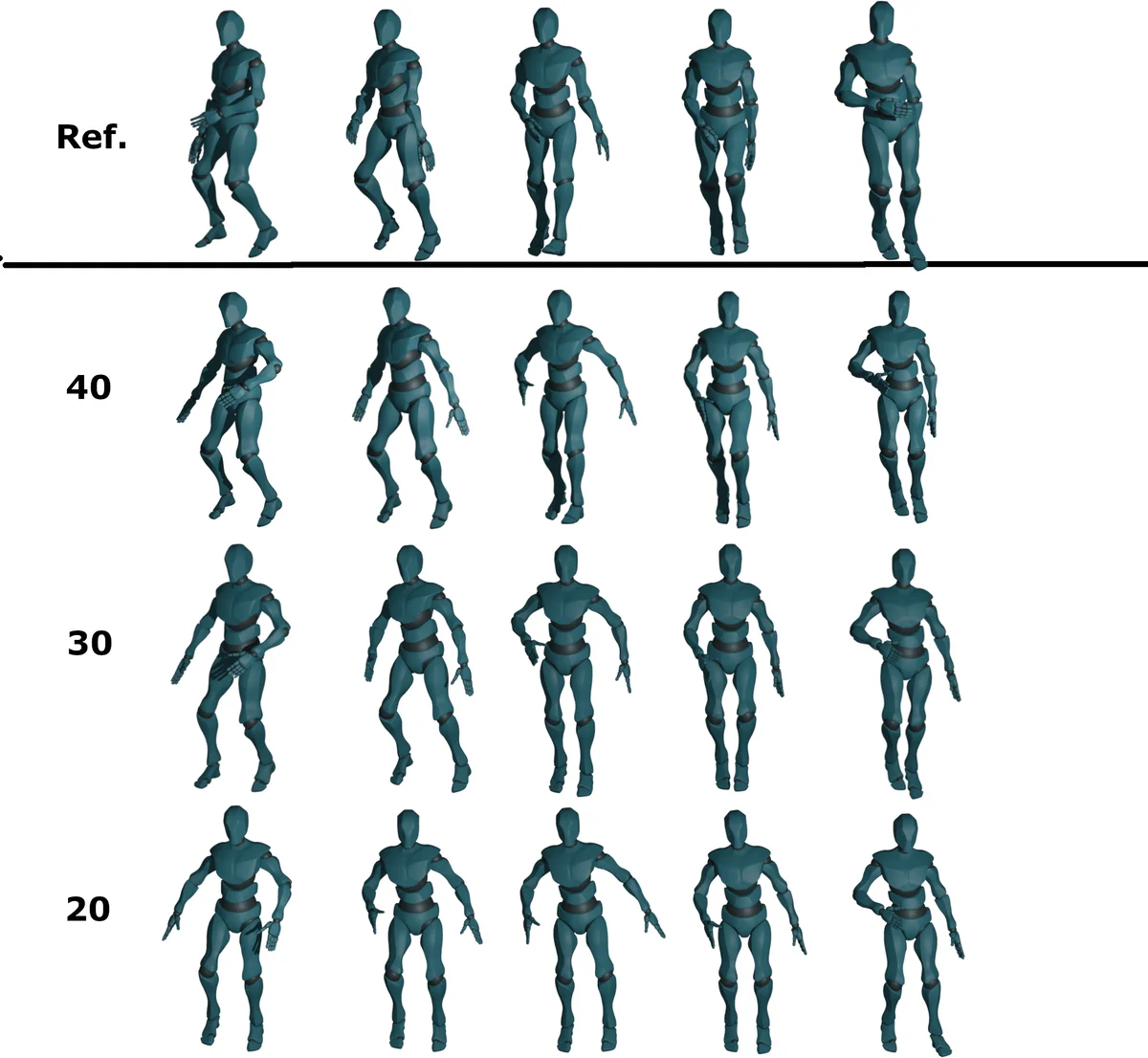
Style transfer is implemented with Iterative Latent Variable Refinement (ILVR). At each denoising step t, the LF part of a reference motion (either the human’s recent frames or a pre‑selected style sample) replaces the LF part of the current latent sample, while the HF part remains unchanged. Repeating this refinement for a configurable number of steps yields a controllable “follow strength”: more ILVR iterations increase similarity to the reference without collapsing diversity after a certain point.
Temporal coherence is maintained through motion inpainting: two consecutive motion windows are encoded into the diffusion latent space, the first half of the second window is forced to match the second half of the first, and the diffusion process then generates a smooth continuation for the remaining frames. This enables the system to extend motion in real time as new human input arrives.
Auxiliary losses—velocity matching and foot‑contact penalties—are added to the diffusion objective to suppress jitter and prevent foot‑sliding, improving physical plausibility. The total loss is L_total = L_denoise + λ_vel·L_vel + λ_fc·L_fc, with λ values taken from the original EDGE implementation.
For inference, the authors adopt DDIM (Deterministic Diffusion Implicit Models) to reduce the number of sampling steps by roughly a factor of 20 while preserving quality. The algorithm (Algorithm 1) interleaves DDIM denoising, ILVR style injection, and inpainting, producing a final motion sequence that respects the human’s LF trajectory and adds AI‑generated HF flair.
Evaluation is performed on the AIST++ dataset, a large benchmark of music‑driven dance motions. Quantitative metrics include diversity (FID, Diversity Score) and alignment (Motion Alignment Score). The generated motions’ feature distribution converges to that of the test set, demonstrating that the model can produce realistic, varied dance movements while staying synchronized with a human partner. Ablation studies show a monotonic increase in similarity metrics with more ILVR steps, followed by diminishing returns, confirming that the follow‑strength parameter can be tuned for a desired balance between imitation and creativity.
The contributions are threefold: (1) an interaction framework that requires only solo motion data and feature‑level guidance, eliminating the need for duet training; (2) a novel integration of EDGE diffusion, ILVR style refinement, and motion inpainting for real‑time, style‑conditioned generation; and (3) an empirical analysis of similarity as a controllable knob governing the trade‑off between stylistic alignment and improvisational freedom.
Limitations include the current offline evaluation setup, latency that is still higher than true real‑time performance, and the lack of multimodal conditioning (e.g., music, emotion) or multi‑partner scenarios. Future work aims to optimize inference speed, incorporate additional modalities, scale up single‑person datasets, and extend the approach to more complex interactive dance settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment