MatSciBench: Benchmarking the Reasoning Ability of Large Language Models in Materials Science
Large Language Models (LLMs) have demonstrated remarkable abilities in scientific reasoning, yet their reasoning capabilities in materials science remain underexplored. To fill this gap, we introduce MatSciBench, a comprehensive college-level benchmark comprising 1,340 problems that span the essential subdisciplines of materials science. MatSciBench features a structured and fine-grained taxonomy that categorizes materials science questions into 6 primary fields and 31 sub-fields, and includes a three-tier difficulty classification based on the reasoning length required to solve each question. MatSciBench provides detailed reference solutions enabling precise error analysis and incorporates multimodal reasoning through visual contexts in numerous questions. Evaluations of leading models reveal that even the highest-performing model, Gemini-2.5-Pro, achieves under 80% accuracy on college-level materials science questions, highlighting the complexity of MatSciBench. Our systematic analysis of different reasoning strategie–basic chain-of-thought, tool augmentation, and self-correction–demonstrates that no single method consistently excels across all scenarios. We further analyze performance by difficulty level, examine trade-offs between efficiency and accuracy, highlight the challenges inherent in multimodal reasoning tasks, analyze failure modes across LLMs and reasoning methods, and evaluate the influence of retrieval-augmented generation. MatSciBench thus establishes a comprehensive and solid benchmark for assessing and driving improvements in the scientific reasoning capabilities of LLMs within the materials science domain.
💡 Research Summary
**
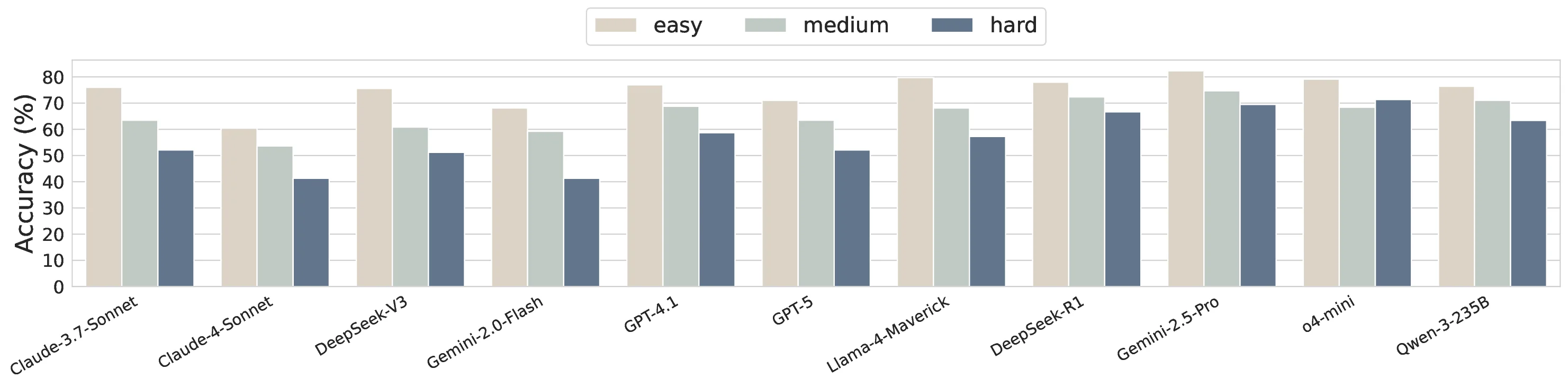
MatSciBench is a newly introduced benchmark designed to evaluate the scientific reasoning abilities of large language models (LLMs) specifically within the domain of materials science. The dataset comprises 1,340 carefully curated, open‑ended questions drawn from ten widely used undergraduate and graduate textbooks covering the essential sub‑disciplines of the field. Each entry includes the question text, a detailed reference solution (available for 944 items), metadata such as difficulty level, primary field, sub‑field, and, when applicable, associated images. The taxonomy is hierarchical: six primary fields (Materials, Properties, Structures, Fundamental Mechanisms, Processes, Failure Mechanisms) are further divided into 31 fine‑grained sub‑categories, reflecting the interdisciplinary nature of materials science. Difficulty is split into three tiers—Easy (50.7 % of questions), Medium (29.1 %), and Hard (20.1 %)—based on the length of model responses required; hard questions (270 in total) demand long, multi‑step reasoning.
A significant portion of the benchmark (315 questions, 23.5 %) incorporates visual contexts such as microstructure images, phase diagrams, or experimental photographs, enabling assessment of multimodal reasoning. The authors evaluate eleven state‑of‑the‑art LLMs, distinguishing between “thinking” models (Claude‑4‑Sonnet, DeepSeek‑R1, Gemini‑2.5‑Pro, Qwen3‑235B, GPT‑5, o4‑mini) that generate extended intermediate reasoning traces, and “non‑thinking” models (GPT‑4.1, Claude‑3.7‑Sonnet, DeepSeek‑V3, Gemini‑2.0‑Flash, Llama‑4‑Maverick). For the non‑thinking models, three reasoning augmentation techniques are applied: basic chain‑of‑thought (CoT), self‑correction, and tool‑augmentation (Python code execution). Performance is measured by strict rule‑based scoring against the reference solutions.
Key findings include: (1) The best overall accuracy is achieved by Gemini‑2.5‑Pro at 77.4 %, while the top non‑thinking model, Llama‑4‑Maverick, reaches 71.6 %. No model surpasses 80 % accuracy, underscoring the difficulty of college‑level materials‑science problems for current LLMs. (2) Thinking models exhibit relative insensitivity to difficulty level, maintaining stable performance across easy, medium, and hard questions, whereas non‑thinking models’ accuracy drops sharply as difficulty increases. (3) Longer generated responses correlate with higher accuracy, revealing a clear efficiency‑accuracy trade‑off: more tokens improve correctness but increase computational cost. (4) Multimodal questions degrade performance for all models; even the strongest thinking models lose 5–10 % absolute accuracy when images are present, highlighting the nascent state of visual‑language integration in this domain. (5) Error analysis categorizes failures into domain‑knowledge inaccuracies, question‑understanding mistakes, arithmetic/unit conversion errors, and hallucinations. CoT reduces arithmetic errors, self‑correction mitigates some comprehension failures, and tool‑augmentation boosts performance on calculation‑heavy sub‑fields (e.g., property estimation) but can introduce new errors elsewhere. (6) Retrieval‑augmented generation (RAG) offers limited benefit: it slightly lowers knowledge‑based errors but simultaneously raises hallucination rates, resulting in negligible net gain.
The authors conclude that MatSciBench provides a rigorous, multidimensional evaluation platform for LLMs in materials science, exposing current limitations in domain knowledge, multimodal reasoning, and efficient reasoning strategies. The benchmark, along with its publicly released dataset and code, is intended to drive future research toward more robust scientific reasoning, better integration of visual information, and more effective use of external tools and retrieval mechanisms in specialized scientific domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment