Harnessing Consistency for Robust Test-Time LLM Ensemble
💡 Research Summary
The paper addresses a critical gap in test‑time large language model (LLM) ensembling: robustness against noisy or erroneous signals that arise from heterogeneous tokenization schemes and varying model expertise. While prior work has focused on either token‑level fusion (aligning and averaging next‑token probabilities) or response‑level selection (choosing the best whole answer), they largely ignore the fact that misaligned tokens or low‑confidence models can corrupt the ensemble output.
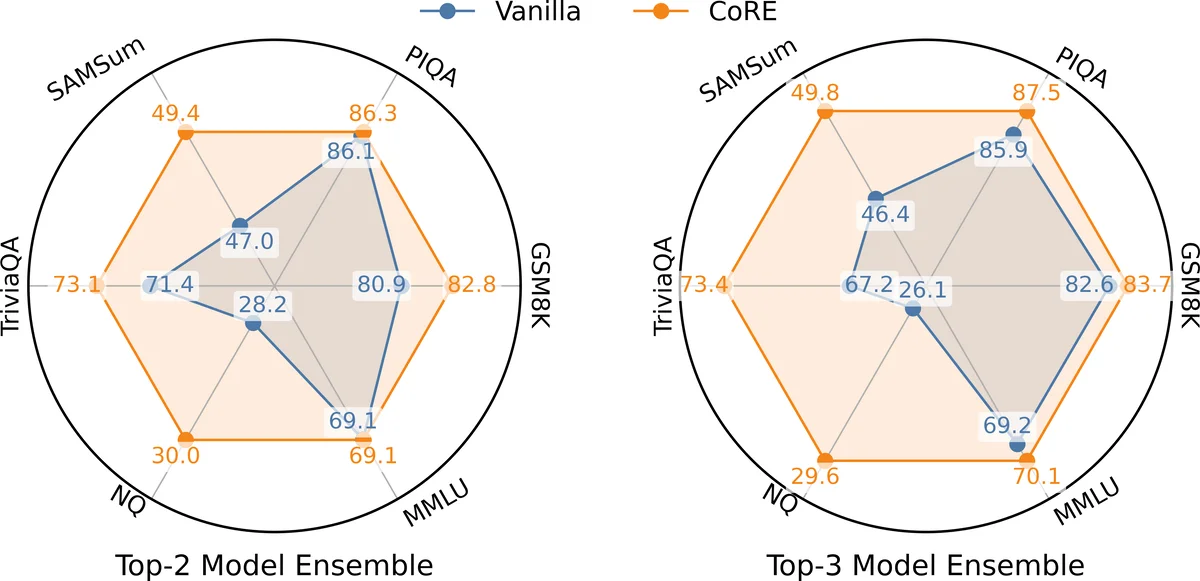
Through extensive empirical analysis on several benchmarks (NQ, PIQA, MMLU, etc.), the authors identify three key failure patterns: (1) large token‑probability disparity between an assistant model’s aligned token distribution and a reference average distribution signals token misalignment; (2) high entropy (low confidence) of a model’s token distribution correlates with wrong answers; (3) the sum of RBF‑transformed token disparities (model consistency) is higher for correct answers. These observations motivate a two‑level consistency framework called CORE (Consistency‑based Robust Ensemble).
Token‑level consistency is defined as a low‑pass filter applied to each token’s probability. For each assistant model i, the disparity vector δ_i = | p̃_i − p* | is computed, where p̃_i is the aligned token distribution and p* is the simple average of all models (the reference). A function f(δ) – e.g., an RBF kernel, a power function, or a sigmoid – maps large disparities to small consistency scores, effectively down‑weighting tokens that are likely misaligned. The filtered token distribution becomes s_t_i ⊙ p̃_i.
Model‑level consistency aggregates token consistency across the whole vocabulary and normalizes it by the model’s entropy, yielding s_m_i = Σ_v s_t_i(v) / H(p̃_i). This score rewards models that both agree with the reference distribution (high Σ s_t_i) and are confident (low entropy). The main model receives a similar score s_m_main.
The final ensembled probability is:
p_ens = s_m_main p_main + Σ_i s_m_i (s_t_i ⊙ p̃_i)
where the model weights
Comments & Academic Discussion
Loading comments...
Leave a Comment