FML-bench: A Benchmark for Automatic ML Research Agents Highlighting the Importance of Exploration Breadth
💡 Research Summary
FML‑bench is a newly introduced benchmark designed to evaluate automatic machine‑learning research agents in settings that more closely resemble scientific inquiry rather than engineering‑focused tasks. The authors identify two major shortcomings of existing benchmarks such as MLAgentBench, MLE‑Bench, and ML‑Dev‑Bench: (1) they concentrate on application‑oriented problems (e.g., Kaggle competitions) that test data pipeline handling and model training, and (2) they evaluate agents primarily on final performance metrics and computational cost, ignoring the iterative research process itself.
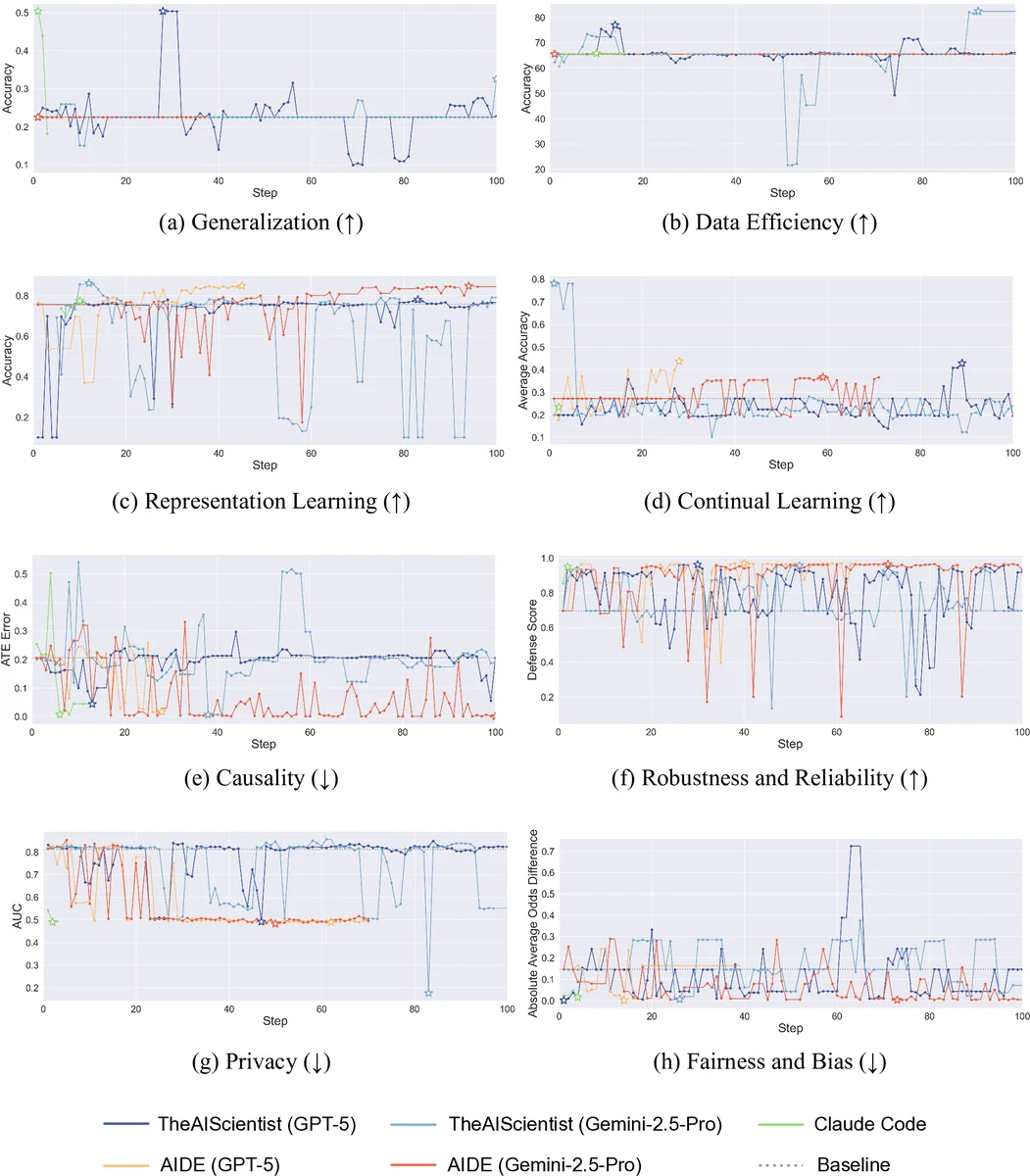
To address these gaps, FML‑bench comprises eight diverse, fundamental ML research problems: Generalization (ColoredMNIST with ERM baseline), Data Efficiency (Mini‑ImageNet with Prototypical Networks), Representation Learning (CIFAR‑10 with MoCo), Continual Learning (splitMNIST with Synaptic Intelligence), Causality (IHDP with DragonNet), Robustness & Reliability (poisoned MNIST with dp‑instahide), Privacy (CIFAR‑10 with Wide‑ResNet‑28‑2 evaluated under membership‑inference attacks), and Fairness & Bias (COMPAS with Adversarial Debiasing). Each task uses a publicly available code repository, limits training/evaluation to roughly two hours, and provides a well‑known baseline that leaves ample headroom for improvement.
The benchmark introduces three process‑level metrics in addition to the usual performance and cost measures. The centerpiece is Exploration Diversity, which quantifies how varied an agent’s proposals are across iterations. Code snippets generated at each step are embedded with GraphCodeBERT; the dispersion of these embeddings around their centroid serves as a proxy for the breadth of exploration. Higher dispersion indicates that the agent is trying a wider range of algorithmic ideas. Complementary metrics are Step Success Rate (the proportion of proposals that run without error and produce experimental results) and Step Completion Rate (the proportion of full research cycles—hypothesis, code edit, experiment, analysis—that are completed). These metrics allow researchers to assess reliability and stability of the agents, not just end‑point accuracy.
The authors evaluate several state‑of‑the‑art automatic research agents, including AIDE (tree‑search based), AI‑Scientist (end‑to‑end pipeline), and AlphaEvolve (evolutionary search). Empirical results show a clear pattern: agents that adopt broader exploration strategies achieve higher Exploration Diversity scores and, correspondingly, better final performance across most tasks. Statistical analysis reveals a positive correlation (Pearson r ≈ 0.68–0.74) between Exploration Diversity and performance gains, confirming that diverse idea generation is a key driver of success. Moreover, agents with higher Step Success and Completion rates tend to be more cost‑effective, suggesting that reliable execution amplifies the benefits of broad exploration.
A comparative table (Table 1) highlights how FML‑bench differs from prior benchmarks: it focuses on fundamental research problems, supports process‑level evaluation, uses real‑world repositories, and lowers the coding barrier for participants. By providing both the codebases and clear task specifications, the benchmark encourages agents to concentrate on algorithmic innovation rather than low‑level engineering.
In conclusion, the paper proposes a paradigm shift for evaluating automatic ML research agents: moving from single‑shot performance snapshots to a richer, multi‑dimensional assessment that captures idea diversity, execution reliability, and scientific relevance. The findings suggest that future agent designs should prioritize mechanisms that encourage wide‑ranging exploration (e.g., stochastic sampling, diverse prompting, or evolutionary mutation) while maintaining robust execution pipelines. The authors release the benchmark publicly (GitHub link) and anticipate that it will spur further work on metrics, task expansion, and human‑agent collaborative workflows.
Comments & Academic Discussion
Loading comments...
Leave a Comment