Data-driven simulator of multi-animal behavior with unknown dynamics via offline and online reinforcement learning
Simulators of animal movements play a valuable role in studying behavior. Advances in imitation learning for robotics have expanded possibilities for reproducing human and animal movements. A key challenge for realistic multi-animal simulation in biology is bridging the gap between unknown real-world transition models and their simulated counterparts. Because locomotion dynamics are seldom known, relying solely on mathematical models is insufficient; constructing a simulator that both reproduces real trajectories and supports reward-driven optimization remains an open problem. We introduce a data-driven simulator for multi-animal behavior based on deep reinforcement learning and counterfactual simulation. We address the ill-posed nature of the problem caused by high degrees of freedom in locomotion by estimating movement variables of an incomplete transition model as actions within an RL framework. We also employ a distance-based pseudo-reward to align and compare states between cyber and physical spaces. Validated on artificial agents, flies, newts, and silkmoth, our approach achieves higher reproducibility of species-specific behaviors and improved reward acquisition compared with standard imitation and RL methods. Moreover, it enables counterfactual behavior prediction in novel experimental settings and supports multi-individual modeling for flexible what-if trajectory generation, suggesting its potential to simulate and elucidate complex multi-animal behaviors.
💡 Research Summary
The paper tackles a fundamental obstacle in animal‑behavior simulation: the lack of explicit, accurate transition models for real organisms. While robotics and sim‑to‑real research assume a known dynamics model, biological multi‑agent systems often exhibit abrupt starts, stops, and complex interactions that cannot be captured by simple physics‑based equations. The authors therefore formulate a “Real‑to‑Sim” domain adaptation problem, where the source domain consists of real‑world trajectory data with unknown dynamics, and the target domain is a virtual environment that must faithfully reproduce those trajectories while still allowing reward‑driven optimization.
The proposed framework, named AnimaRL, proceeds in four stages. First, raw positional and velocity data from four datasets—synthetic predator‑prey agents, fruit flies, newts, and silkmoths—are collected in a two‑dimensional arena. Second, the authors treat the key locomotion parameters—damping coefficient d and control‑input amplitude u—as latent variables of a simple velocity transition equation: v′ = (1‑d) v + u a Δt. These parameters are estimated offline from the data using least‑squares (or Bayesian) fitting, yielding low root‑mean‑square errors (≤ 0.045 for artificial agents, ≤ 0.009 for silkmoths). By embedding the estimated d and u into the simulator, each virtual agent inherits a dynamics model that is calibrated to the observed animal.
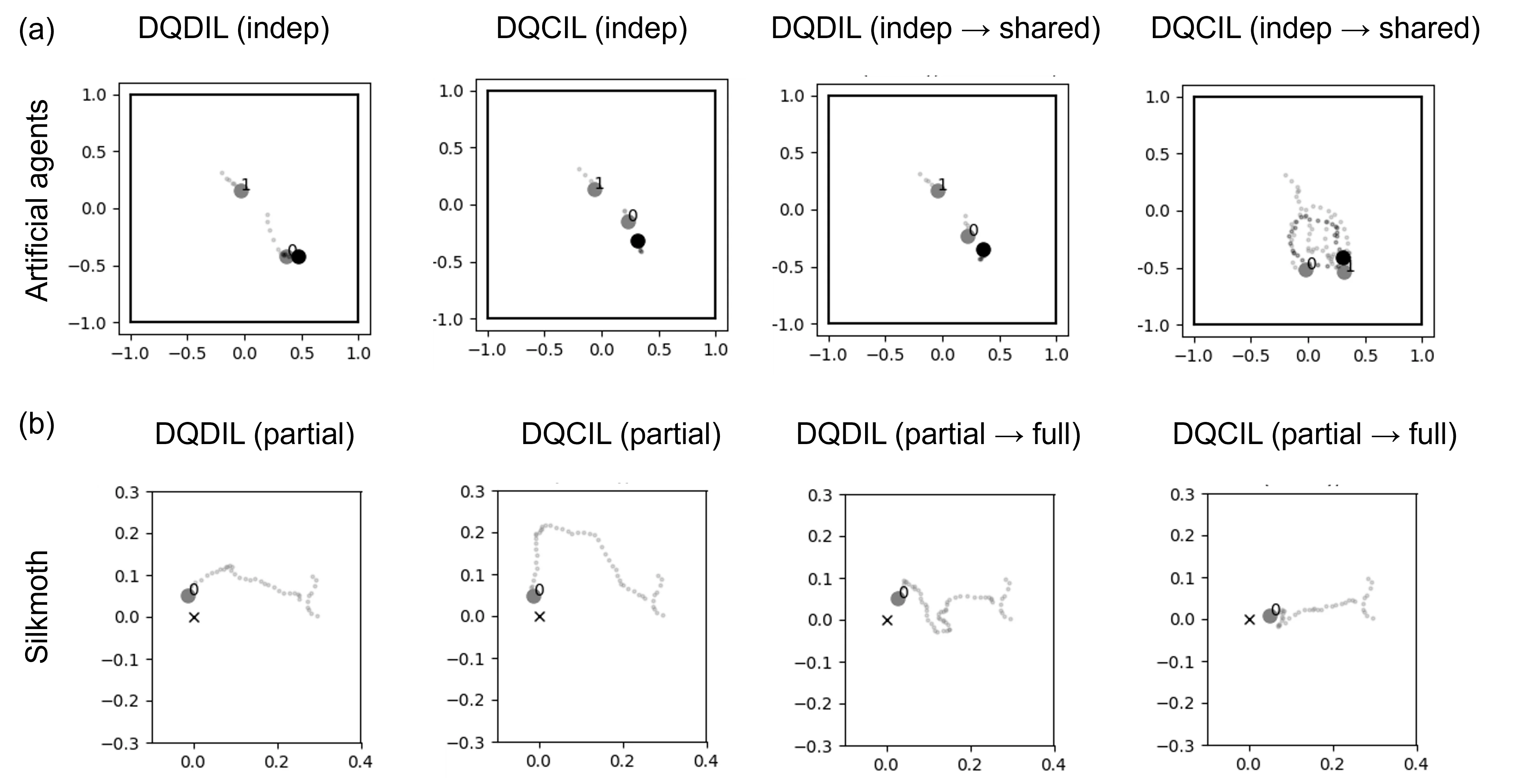
Third, an offline reinforcement‑learning phase learns a policy that simultaneously imitates the demonstrations and maximizes the original task reward (e.g., successful capture of a target). To enforce imitation, the authors introduce a distance‑based pseudo‑reward: the Euclidean distance between the current cyber state and the corresponding physical state is subtracted from the true reward, yielding the DQDIL (Deep Q‑Learning with Distance‑based Imitation Learning) objective. This encourages the Q‑function to generate actions that keep the simulated trajectory close to the real one while still pursuing the task.
Fourth, the pretrained policy is deployed in the simulated environment and refined online. Standard DQN updates are applied, but the state‑action pairs generated during interaction are also used to re‑estimate d and u, allowing the dynamics model to adapt to any distribution shift introduced by the policy’s own exploration. This two‑phase (offline + online) learning pipeline ensures both high fidelity to observed behavior and the ability to generalize to novel scenarios.
The authors evaluate AnimaRL on four datasets. Metrics include (1) return (number of successful contacts with the target), (2) path‑length and episode‑duration distribution similarity measured by kernel‑density estimation (KDE) distance, and (3) dynamic‑time‑warping (DTW) distance between simulated and ground‑truth trajectories. Across all species, AnimaRL outperforms pure behavioral cloning (BC) and standard DQN baselines. For example, return improves by 15‑30 % and DTW distance drops by roughly 20 % relative to BC. The framework also supports counterfactual imitation learning (DQCIL), enabling prediction of behavior under altered experimental conditions (e.g., new obstacles or modified reward structures) without additional data collection.
A notable contribution is the ability to simulate multiple agents simultaneously. The system learns separate d, u, and policies for each individual, yet the agents interact within the same virtual arena, reproducing collective dynamics such as coordinated pursuit or swarm‑like navigation. This multi‑agent capability opens the door to virtual ethology experiments where researchers can test hypotheses about group behavior, competition, or cooperation in silico.
Limitations are acknowledged. The linear damping‑input model may be insufficient for highly non‑linear motions like rapid turns, jumps, or terrain‑dependent friction. Future work is suggested to incorporate mixture models, state‑switching dynamics, or meta‑RL techniques to capture richer biomechanics. Extending the approach to three‑dimensional spaces and integrating multimodal sensory inputs (visual, olfactory, auditory) are also proposed.
In summary, AnimaRL demonstrates that a data‑driven simulator can bridge the Real‑to‑Sim gap for multi‑animal systems by estimating unknown locomotion parameters, using distance‑based imitation rewards, and combining offline and online reinforcement learning. The resulting simulator reproduces species‑specific trajectories with high fidelity, achieves superior task performance, and provides a flexible platform for counterfactual experiments, offering valuable tools for ethology, neuroscience, and bio‑inspired robotics.
Comments & Academic Discussion
Loading comments...
Leave a Comment