NUMINA: A Natural Understanding Benchmark for Multi-dimensional Intelligence and Numerical Reasoning Abilities
Recent advancements in 2D multimodal large language models (MLLMs) have significantly improved performance in vision-language tasks. However, extending these capabilities to 3D environments remains a distinct challenge due to the complexity of spatial reasoning. Nevertheless, existing 3D benchmarks often lack fine-grained numerical reasoning task annotations, limiting MLLMs’ ability to perform precise spatial measurements and complex numerical reasoning. To address this gap, we introduce NUMINA, the first Natural Understanding benchmark for Multi-dimensional Intelligence and Numerical reasoning Abilities to enhance multimodal indoor perceptual understanding. NUMINA features multi-scale annotations and various question-answer pairs, generated using NUMINA-Flow, an automated annotation pipeline that integrates LLM rewriting and rule-based self-verification. We evaluate the performance of various state-of-the-art LLMs on NUMINA following the Chat-Scene framework, demonstrating that current LLMs struggle with multimodal numerical reasoning, particularly in performing precise computations such as distance and volume estimation, highlighting the need for further advancements in 3D models. The dataset and source codes can be obtained from https://github.com/fengshun124/NUMINA.
💡 Research Summary
The paper introduces NUMINA, the first large‑scale benchmark designed to evaluate multimodal large language models (LLMs) on fine‑grained spatial understanding and numerical reasoning within indoor 3D scenes. Existing 3D vision‑language datasets such as ScanRefer, Talk2Nav, and ScanQA provide object localization or textual QA but lack precise geometric annotations required for tasks like distance measurement, volume calculation, or quantity estimation. To fill this gap, the authors build NUMINA on top of the ScanNet dataset, extracting for every object its centroid coordinates, axis‑aligned bounding‑box dimensions, and the pairwise convex‑hull distance—a metric that captures the shortest distance between the outer boundaries of two point clouds and aligns well with human perception. Volume for irregular objects is approximated by the smallest axis‑aligned bounding box.
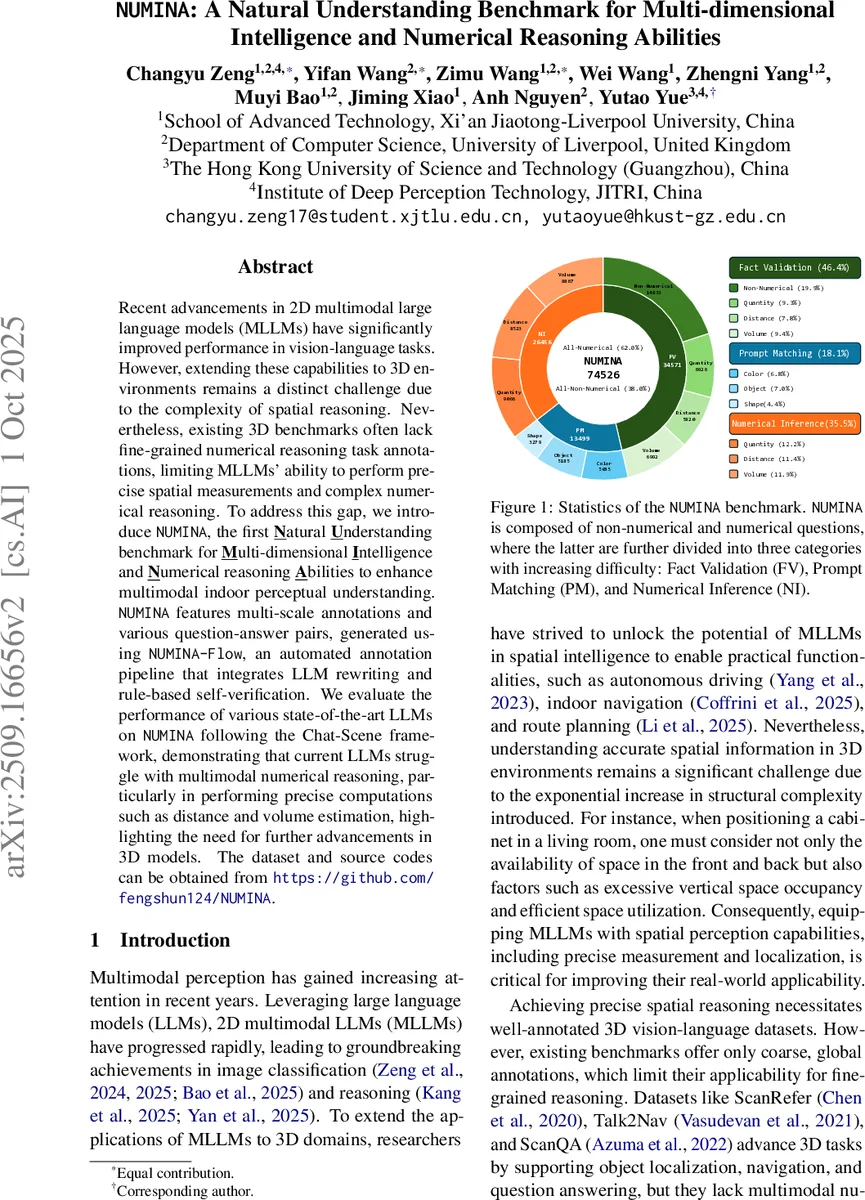
Data generation is fully automated through the NUMINA‑Flow pipeline. First, GPT‑4o creates ten diverse question templates for each of three task categories: Fact Validation (binary yes/no), Prompt Matching (5‑option multiple‑choice), and Numerical Inference (exact numeric answer with units). Place‑holders in the templates are filled with the extracted numerical ground truth (NGT) values and object references, producing concrete QA pairs. The pipeline enforces balanced answer distributions (equal yes/no, uniform correct‑option placement across A‑E) and applies rule‑based as well as human verification to eliminate bias and ensure factual correctness. To enrich non‑numerical content, 14 000 QA pairs from ScanQA are rewritten by Qwen2.5‑72B, adding color, shape, and relational questions. The final corpus contains 74 526 QA pairs, of which 46 194 (62 %) are numerical (sub‑divided into quantity, distance, and volume) and 28 332 are non‑numerical.
For evaluation, the authors integrate several open‑source LLMs (Vicuna, Qwen, etc.) as decoders within the Chat‑Scene framework, enabling simultaneous processing of 3D point clouds, 2D images, and textual prompts. Performance is measured with task‑specific metrics: accuracy for Fact Validation, selection accuracy for Prompt Matching, and both standard accuracy and Threshold Accuracy at 5 % error (T@5) for Numerical Inference. Results reveal a stark contrast: while models achieve reasonable scores on non‑numerical tasks, they struggle dramatically on numeric ones. In distance and volume estimation, T@5 falls below 3 % and overall accuracy hovers around 54 %, essentially random performance. No single model dominates across all categories, indicating varied strengths and weaknesses.
The authors compare NUMINA against prior benchmarks, highlighting its unique contributions: (1) comprehensive multi‑dimensional geometric annotations enabling precise numeric reasoning; (2) a three‑tier difficulty structure that tests models from simple verification to exact numeric computation; (3) an automated, reproducible pipeline that yields high‑quality, bias‑controlled data; and (4) public release of code and data to foster further research. The study concludes that current 3D multimodal LLMs are far from capable of reliable spatial measurement and that future work must explore architectures that can directly ingest and reason over geometric metadata such as convex‑hull distances and bounding‑box volumes, develop specialized prompting strategies, and possibly incorporate differentiable geometry modules. NUMINA thus provides a rigorous testbed for measuring progress toward truly spatially aware AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment