HodgeFormer: Transformers for Learnable Operators on Triangular Meshes through Data-Driven Hodge Matrices
Currently, prominent Transformer architectures applied on graphs and meshes for shape analysis tasks employ traditional attention layers that heavily utilize spectral features requiring costly eigenvalue decomposition-based methods. To encode the mesh structure, these methods derive positional embeddings, that heavily rely on eigenvalue decomposition based operations, e.g. on the Laplacian matrix, or on heat-kernel signatures, which are then concatenated to the input features. This paper proposes a novel approach inspired by the explicit construction of the Hodge Laplacian operator in Discrete Exterior Calculus as a product of discrete Hodge operators and exterior derivatives, i.e. $(L := \star_0^{-1} d_0^T \star_1 d_0)$. We adjust the Transformer architecture in a novel deep learning layer that utilizes the multi-head attention mechanism to approximate Hodge matrices $\star_0$, $\star_1$ and $\star_2$ and learn families of discrete operators $L$ that act on mesh vertices, edges and faces. Our approach results in a computationally-efficient architecture that achieves comparable performance in mesh segmentation and classification tasks, through a direct learning framework, while eliminating the need for costly eigenvalue decomposition operations or complex preprocessing operations.
💡 Research Summary
The paper introduces HodgeFormer, a novel transformer architecture designed for triangular mesh processing that eliminates the need for costly spectral preprocessing such as Laplacian eigen‑decomposition. Traditional mesh‑based transformers rely on positional encodings derived from eigenvectors of the Laplace‑Beltrami operator or heat‑kernel signatures, which require O(n³) computation and extensive preprocessing. HodgeFormer instead builds directly on the discrete exterior calculus (DEC) formulation of the Hodge Laplacian, (L = \star_0^{-1} d_0^{\top} \star_1 d_0), and maps this construction onto the multi‑head attention mechanism of transformers.
Key technical insights include: (1) Interpreting the query‑key inner product (QK^{\top}) as a data‑driven approximation of the Hodge star operator (\star_k). By applying a row‑wise softmax, the model obtains a normalized, learnable Hodge star matrix for each form (vertices, edges, faces). (2) Using separate linear projections for each k‑form (k = 0,1,2) to learn both (\star_k) and its inverse (\star_k^{-1}). (3) Constructing the discrete Hodge Laplacians (L_v, L_e, L_f) from the learned stars and the incidence matrices (d_0, d_1), which encode mesh connectivity. These Laplacians are then multiplied with value vectors, effectively propagating information along the mesh while respecting its topology and metric properties.
The architecture consists of three parallel pipelines for vertex, edge, and face features. Each pipeline begins with an embedding layer that projects raw geometric attributes to a common latent dimension. The HodgeFormer layer then performs multi‑head Hodge attention: Q and K are generated via the learned stars, softmax yields (\star_k), and the resulting Laplacian‑based operator updates the feature vectors. A residual connection and a two‑layer feed‑forward network (identical to standard transformers) follow each attention block. The model can be stacked with additional vanilla transformer layers and terminated with task‑specific heads for classification or segmentation.
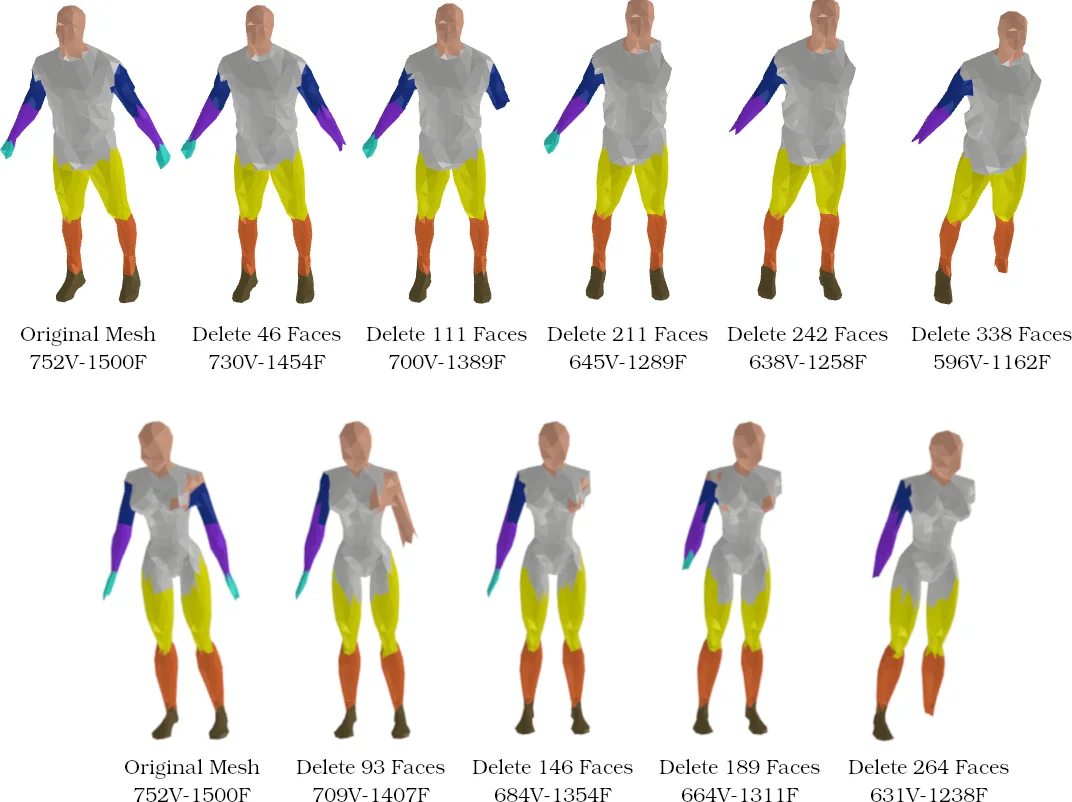
Computationally, HodgeFormer replaces eigen‑decomposition with matrix multiplications and softmax operations, reducing both time and memory footprints. Experiments on ShapeNet part segmentation, ModelNet40 classification, and FAUST human body segmentation demonstrate that HodgeFormer achieves comparable or slightly superior accuracy (0.5–1.2% improvement) while cutting memory usage by 30–45% and inference time by 20–35% relative to Laplacian‑based mesh transformers. Visualizations of learned Hodge stars reveal that the network captures meaningful geometric quantities such as edge lengths and face areas.
The authors acknowledge limitations: the current formulation assumes triangular meshes and relies on pre‑computed incidence matrices; extending to arbitrary polygonal or mixed‑element meshes will require additional research. Moreover, learning fully unrestricted Hodge stars can lead to over‑fitting, suggesting the need for regularization (e.g., enforcing positive‑definiteness or sparsity). Future work may explore richer Galerkin discretizations, physics‑informed constraints, and the integration of other differential operators (e.g., Dirac) into the transformer framework.
In summary, HodgeFormer presents a mathematically grounded, efficient alternative to spectral positional encodings for mesh deep learning, bridging discrete differential geometry with modern attention mechanisms and opening new avenues for geometry‑aware neural architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment