BOLT: Bandwidth-Optimized Lightning-Fast Oblivious Map powered by Secure HBM Accelerators
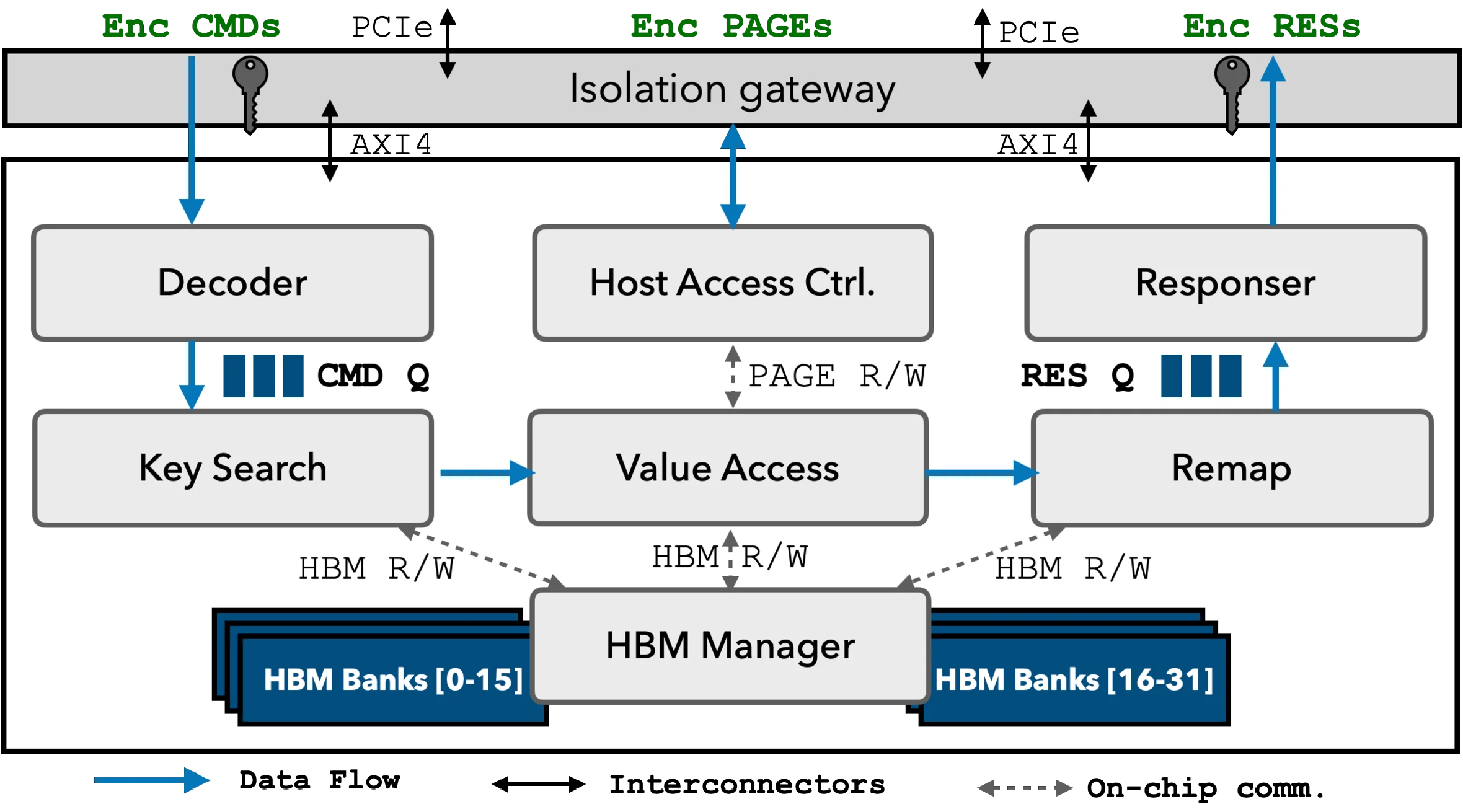
While Trusted Execution Environments provide a strong foundation for secure cloud computing, they remain vulnerable to access pattern leakages. Oblivious Maps (OMAPs) mitigate this by fully hiding access patterns but suffer from high overhead due to randomized remapping and worst-case padding. We argue these costs are not fundamental. Modern accelerators featuring High-Bandwidth Memory (HBM) offer a new opportunity: Vaswani et al. [OSDI'18] point out that eavesdropping on HBM is difficult – even for physical attackers – as its memory channels are sealed together with processor cores inside the same physical package. Later, Hunt et al. [NSDI'20] show that, with proper isolation, HBM can be turned into an unobservable region where both data and memory traces are hidden. This motivates a rethink of OMAP design with HBM-backed solutions to finally overcome their traditional performance limits. Building on these insights, we present BOLT, a Bandwidth Optimized, Lightning-fast OMAP accelerator that, for the first time, achieves O(1) + O(log_2(log_2 (N))) bandwidth overhead. BOLT introduces three key innovations: (i) a new OMAP algorithm that leverages isolated HBM as an unobservable cache to accelerate oblivious access to large host memory; (ii) a self-hosted architecture that offloads execution and memory control from the host to mitigate CPU-side leakage; and (iii) tailored algorithm-architecture co-designs that maximize resource efficiency. We implement a prototype BOLT on a Xilinx U55C FPGA. Evaluations show that BOLT achieves up to 279x and 480x speedups in initialization and query time, respectively, over state-of-the-art OMAPs, including an industry implementation from Facebook.
💡 Research Summary
The paper addresses a critical weakness of current Trusted Execution Environments (TEEs): while they protect data in use, they still leak information through memory access patterns. Oblivious Maps (OMAPs) have been proposed to hide these patterns, but existing designs suffer from prohibitive overheads, typically O(log N) rounds and O(log²N) bandwidth expansion per operation, leading to slowdown factors of several thousand compared to non‑private key‑value stores. The authors argue that these costs are not inherent and can be dramatically reduced by exploiting High‑Bandwidth Memory (HBM) as a hardware‑unobservable memory (HUM) region. Prior work has shown that HBM, tightly integrated with processor dies, is difficult to probe even with physical attacks, and that, with proper isolation, it can serve as a secure enclave.
BOLT (Bandwidth‑Optimized Lightning‑fast Oblivious Map) is introduced as the first OMAP accelerator that achieves an asymptotic bandwidth overhead of O(1) + O(log log N), a substantial improvement over the Ω(log N) lower bound for traditional ORAM‑based OMAPs. The design rests on three innovations: (i) a novel OMAP algorithm that treats HBM as an unobservable cache storing metadata and a hash‑based binning structure, while the bulk data resides in host DRAM; each access reads an entire fixed‑size bin, performs the key lookup, and then randomly remaps the data to a new bin using the power‑of‑two‑choices (P2C) load‑balancing technique, which keeps bin loads low and enables the O(1)+O(log log N) overhead; (ii) a self‑hosted accelerator architecture that internalizes all KV‑store logic, dynamic memory management, and oblivious primitives, thereby eliminating the need for a trusted client or frequent host‑CPU involvement and mitigating indirect side‑channel leakage; (iii) a suite of algorithm‑architecture co‑design optimizations, including decomposed storage, reverse indexing, dynamic HBM partitioning, and streaming pipelines, to avoid resource fragmentation and maximize throughput.
The authors provide a rigorous dimensional analysis to bound the sizes of the hash tables and bins, guiding parameter selection and ensuring that HBM capacity is used efficiently without overflow. The hardware implementation targets a Xilinx U55C FPGA, leveraging its integrated HBM (up to 16 GB) and high‑speed DRAM interfaces. Evaluation against several state‑of‑the‑art OMAPs, including a production‑grade Facebook implementation, shows dramatic speedups: initialization time improves up to 279× and query latency up to 480×, corresponding to normalized slowdown reductions of 760× and 6,338× respectively. Bandwidth measurements confirm the claimed O(1)+O(log log N) behavior across a range of dataset sizes (up to tens of gigabytes).
The paper also discusses limitations. BOLT is currently a single‑accelerator design; scaling to multi‑accelerator clusters or distributed KV stores will require additional coordination mechanisms. The hash table stored in HBM can become a bottleneck if the load factor grows, necessitating periodic rehashing. Moreover, while HBM provides strong physical isolation, the security guarantees still rely on correct TEE configuration and proper key management, which are outside the scope of the hardware design.
Future work includes extending BOLT to multi‑HBM systems, automating parameter tuning via a compiler stack, and integrating with higher‑level oblivious computation frameworks (e.g., secure multi‑party computation or private data analytics). The authors conclude that leveraging HBM as a secure, high‑capacity memory substrate fundamentally reshapes the performance landscape of oblivious data structures, making practical, high‑throughput, privacy‑preserving key‑value stores feasible for real‑world cloud deployments.
Comments & Academic Discussion
Loading comments...
Leave a Comment