GaussianCross: Cross-modal Self-supervised 3D Representation Learning via Gaussian Splatting
The significance of informative and robust point representations has been widely acknowledged for 3D scene understanding. Despite existing self-supervised pre-training counterparts demonstrating promising performance, the model collapse and structural information deficiency remain prevalent due to insufficient point discrimination difficulty, yielding unreliable expressions and suboptimal performance. In this paper, we present GaussianCross, a novel cross-modal self-supervised 3D representation learning architecture integrating feed-forward 3D Gaussian Splatting (3DGS) techniques to address current challenges. GaussianCross seamlessly converts scale-inconsistent 3D point clouds into a unified cuboid-normalized Gaussian representation without missing details, enabling stable and generalizable pre-training. Subsequently, a tri-attribute adaptive distillation splatting module is incorporated to construct a 3D feature field, facilitating synergetic feature capturing of appearance, geometry, and semantic cues to maintain cross-modal consistency. To validate GaussianCross, we perform extensive evaluations on various benchmarks, including ScanNet, ScanNet200, and S3DIS. In particular, GaussianCross shows a prominent parameter and data efficiency, achieving superior performance through linear probing (<0.1% parameters) and limited data training (1% of scenes) compared to state-of-the-art methods. Furthermore, GaussianCross demonstrates strong generalization capabilities, improving the full fine-tuning accuracy by 9.3% mIoU and 6.1% AP$_{50}$ on ScanNet200 semantic and instance segmentation tasks, respectively, supporting the effectiveness of our approach. The code, weights, and visualizations are publicly available at \href{https://rayyoh.github.io/GaussianCross/}{https://rayyoh.github.io/GaussianCross/}.
💡 Research Summary
GaussianCross introduces a cross‑modal self‑supervised framework for learning robust 3D scene representations by leveraging feed‑forward 3D Gaussian Splatting (3DGS). The method first normalizes raw point clouds into a unit cuboid and discretizes them into a uniform voxel grid. Each voxel’s center becomes the initial mean of an anisotropic Gaussian primitive, while voxel‑aggregated features serve as initial color, opacity, and scale parameters. This “cuboid‑normalized Gaussian initialization” eliminates scale variance across scenes and preserves fine geometric details without requiring scene‑specific optimization.
The core learning module, Tri‑attribute Adaptive Distillation Splatting, predicts three complementary attributes for each Gaussian: (i) an offset that refines the mean position, (ii) an opacity value that drives a dynamic pruning mechanism to control primitive density, and (iii) a dense 3D feature field generated by a 3D CNN. The feature field is aligned with latent embeddings from a frozen 2D vision foundation model (e.g., DINOv2 or CLIP) via a projection head, enabling cross‑modal knowledge distillation without any manual annotations.
Training is driven by novel view synthesis: randomly sampled camera poses render the Gaussian primitives into RGB, depth, and semantic maps, which are then compared to the corresponding RGB‑D observations. The total loss combines color reconstruction, depth reconstruction, semantic distillation, and pruning regularization terms. Because supervision comes solely from rendered views, the approach avoids reliance on 3D ground‑truth and mitigates the model‑collapse problem common in contrastive point‑cloud methods.
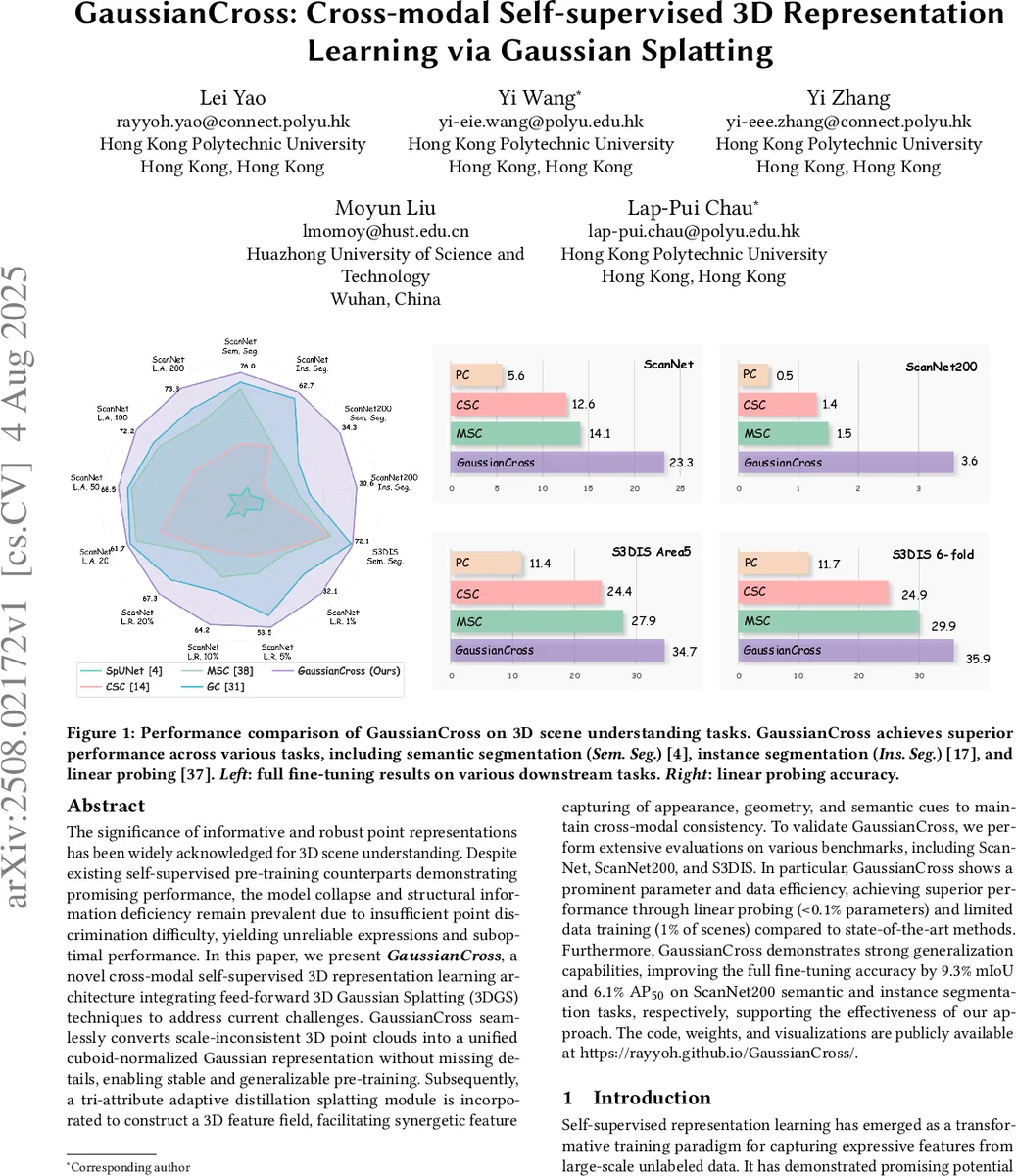
Extensive experiments on indoor benchmarks—ScanNet, ScanNet200, and S3DIS—demonstrate that GaussianCross outperforms prior self‑supervised and rendering‑based methods. In linear probing (training less than 0.1 % of parameters), it achieves mIoU improvements of up to 4.7 % on ScanNet and 9.2 % on ScanNet200. Full fine‑tuning gains are even larger, with +9.3 % mIoU and +6.1 % AP₅₀ on ScanNet200 semantic and instance segmentation, respectively. Remarkably, the model reaches these results using only 1 % of the training scenes, highlighting its data efficiency. Parameter count is reduced by roughly 30 % compared to competing backbones, and real‑time inference (~30 fps) is maintained thanks to the opacity‑driven pruning.
Ablation studies confirm that cuboid normalization is essential for scale‑invariant representations, while each attribute in the adaptive splatting module contributes uniquely to performance gains. The method also shows strong robustness against model collapse, as measured by feature diversity metrics.
Limitations include the reliance on voxel resolution for extremely complex or outdoor scenes, and the current focus on visual (RGB‑D) modalities without textual or auditory extensions. Future work may explore dynamic voxel adaptivity, multimodal distillation (e.g., text‑to‑3D), and more aggressive Gaussian compression to further scale the approach.
In summary, GaussianCross successfully bridges 3D Gaussian Splatting with cross‑modal self‑supervision, delivering a scalable, efficient, and high‑performing solution for 3D scene understanding.
Comments & Academic Discussion
Loading comments...
Leave a Comment