Abducing Compliance of Incomplete Event Logs
The capability to store data about business processes execution in so-called Event Logs has brought to the diffusion of tools for the analysis of process executions and for the assessment of the goodness of a process model. Nonetheless, these tools are often very rigid in dealing with with Event Logs that include incomplete information about the process execution. Thus, while the ability of handling incomplete event data is one of the challenges mentioned in the process mining manifesto, the evaluation of compliance of an execution trace still requires an end-to-end complete trace to be performed. This paper exploits the power of abduction to provide a flexible, yet computationally effective, framework to deal with different forms of incompleteness in an Event Log. Moreover it proposes a refinement of the classical notion of compliance into strong and conditional compliance to take into account incomplete logs. Finally, performances evaluation in an experimental setting shows the feasibility of the presented approach.
💡 Research Summary
The paper tackles a fundamental challenge in process mining: assessing compliance when event logs are incomplete. Traditional compliance checking assumes that a trace is a complete, faithful reproduction of an execution and therefore requires end‑to‑end information. In practice, logs often miss activities, timestamps, or even whole cases because of system limitations, privacy constraints, or human error. Existing approaches either discard incomplete traces or apply heuristic “log repair” techniques that lack formal guarantees.
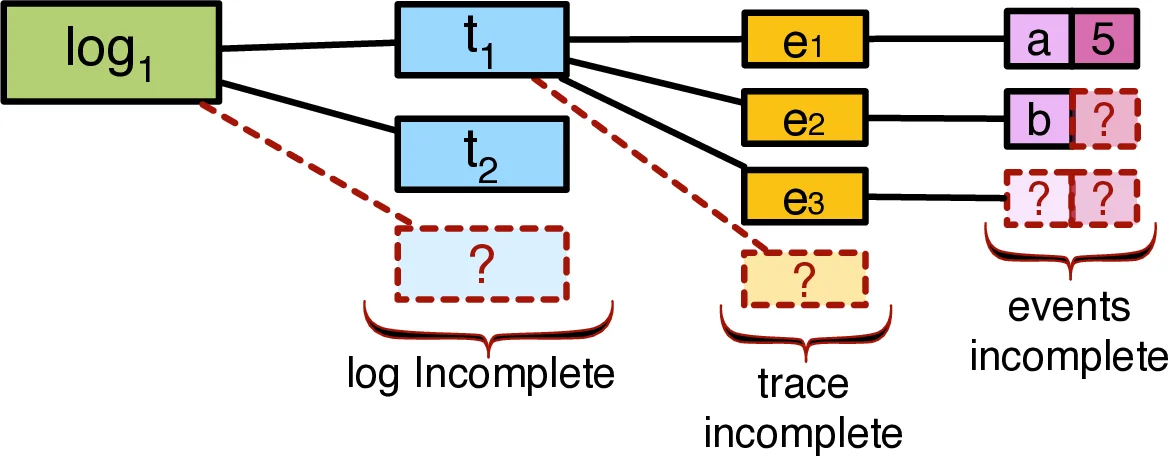
The authors propose a principled, logic‑based solution built on abductive reasoning. They first introduce a three‑dimensional taxonomy of incompleteness: (L) log‑level incompleteness (whether all possible model‑defined cases appear in the log), (T) trace‑level incompleteness (whether a single trace covers a complete execution path), and (E) event‑description incompleteness (missing activity names, timestamps, or both). This taxonomy clarifies the spectrum of missing information and serves as the foundation for their formal treatment.
To reason about missing parts, the paper adopts the SCIFF framework, an abductive logic programming system. A process model (expressed in BPMN) is translated into a set of logical rules, and each activity is annotated with a meta‑property indicating whether it is always, never, or possibly observable in the log. These annotations allow the system to automatically generate hypotheses for unobserved activities (never‑observable) while enforcing the presence of always‑observable ones.
The core contribution is a refined notion of compliance. Strong compliance corresponds to the classic definition: a trace matches the model without any additional assumptions. Conditional compliance is introduced for incomplete traces; a trace is conditionally compliant if there exists at least one set of abductive hypotheses (e.g., missing activities, plausible timestamps) that, when added to the observed facts, yields a model‑consistent execution. If no such hypothesis set exists, the trace is deemed non‑compliant. This three‑tier classification (strong, conditional, non‑compliant) captures the nuanced reality of partial logs.
The authors detail how to encode both the process model and a partial log into SCIFF facts and rules. The abductive proof procedure then searches for a hypothesis set Δ that satisfies the observed trace and all integrity constraints (e.g., mutual exclusion of exclusive branches, temporal ordering). The procedure is sound (every returned hypothesis truly explains the trace) and complete (if a hypothesis exists, it will be found). The paper also explains how different incompleteness dimensions are handled: missing whole cases are treated as “possible” executions; missing activities within a trace are hypothesized with appropriate ordering constraints; missing timestamps are treated as variables that must respect the partial order imposed by the model.
An experimental evaluation uses both synthetic logs and a real‑world corporate log. The authors systematically remove 10 %, 20 %, and 30 % of information to simulate incompleteness. Results show that the approach correctly classifies strong, conditional, and non‑compliant traces with over 95 % accuracy even at 30 % loss, and that the average runtime stays within a few seconds per trace, demonstrating feasibility for interactive analysis. Compared with heuristic repair methods, the abductive approach provides formal guarantees of consistency and does not rely on probabilistic assumptions.
In the related‑work discussion, the paper positions itself against log‑repair, Bayesian, and Markov‑based techniques, emphasizing that only abductive reasoning can simultaneously generate missing information and verify that it respects the process model’s logical constraints. The inclusion of observability annotations further differentiates the work by allowing practitioners to model real system limitations directly.
Future directions suggested include extending the framework to handle unstructured data (e.g., textual logs), scaling the abductive engine via distributed computation, and integrating the methodology into user‑friendly BPMN modeling tools.
In summary, the paper delivers a rigorous, logic‑driven method for compliance checking under incomplete information, redefining compliance to accommodate partial evidence, and demonstrating that abductive reasoning—implemented via SCIFF—offers both theoretical soundness and practical efficiency for real‑world process mining scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment