GCC: A 3DGS Inference Architecture with Gaussian-Wise and Cross-Stage Conditional Processing
3D Gaussian Splatting (3DGS) has emerged as a leading neural rendering technique for high-fidelity view synthesis, prompting the development of dedicated 3DGS accelerators for resource-constrained platforms. The conventional decoupled preprocessing-rendering dataflow in existing accelerators has two major limitations: 1) a significant portion of preprocessed Gaussians are not used in rendering, and 2) the same Gaussian gets repeatedly loaded across different tile renderings, resulting in substantial computational and data movement overhead. To address these issues, we propose GCC, a novel accelerator designed for fast and energy-efficient 3DGS inference. GCC introduces a novel dataflow featuring: 1) \textit{cross-stage conditional processing}, which interleaves preprocessing and rendering to dynamically skip unnecessary Gaussian preprocessing; and 2) \textit{Gaussian-wise rendering}, ensuring that all rendering operations for a given Gaussian are completed before moving to the next, thereby eliminating duplicated Gaussian loading. We also propose an alpha-based boundary identification method to derive compact and accurate Gaussian regions, thereby reducing rendering costs. We implement our GCC accelerator in 28nm technology. Extensive experiments demonstrate that GCC significantly outperforms the state-of-the-art 3DGS inference accelerator, GSCore, in both performance and energy efficiency.
💡 Research Summary
The paper tackles the inefficiencies of existing 3D Gaussian Splatting (3DGS) inference accelerators, which follow a conventional two‑stage “preprocess‑then‑render” pipeline combined with tile‑wise rendering. Two major problems are identified: (1) a large fraction of Gaussians are preprocessed even though they are never used during rendering because the α‑blending early‑termination discards many of them; in GSCore up to 60 % of preprocessed Gaussians are wasted, and preprocessing consumes about 40 % of total execution time. (2) Tile‑wise rendering causes the same Gaussian that overlaps multiple tiles to be loaded repeatedly, leading to 3–6× redundant memory accesses per Gaussian.
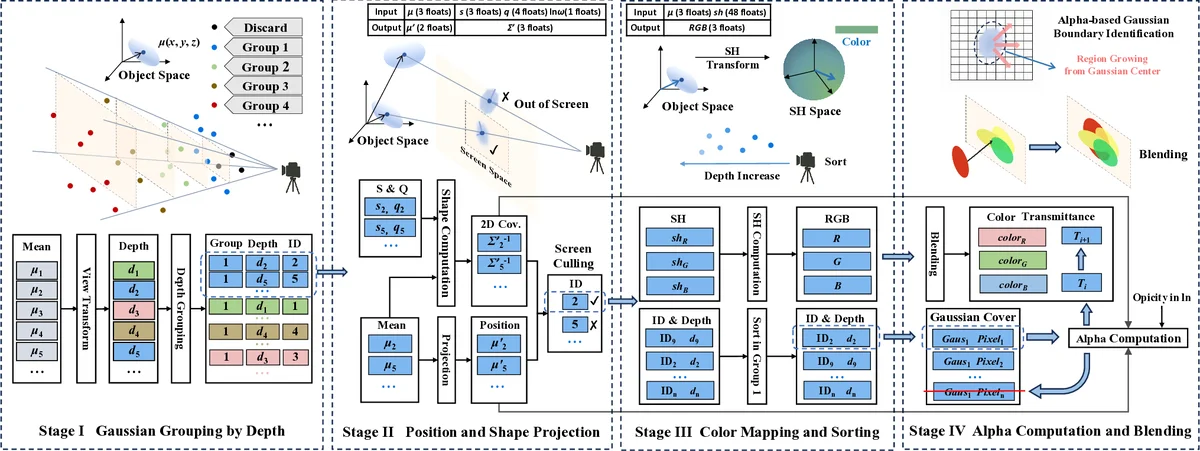
To solve these issues, the authors propose GCC, a novel 3DGS inference accelerator that introduces two key data‑flow innovations. First, cross‑stage conditional processing interleaves preprocessing and rendering. Instead of preprocessing all Gaussians up front, the hardware evaluates each Gaussian on‑the‑fly: if it lies outside the view frustum or its α value falls below a threshold, the preprocessing step is skipped entirely. This dynamic gating eliminates unnecessary data movement and computation, reducing preprocessing overhead dramatically.
Second, Gaussian‑wise rendering replaces tile‑wise processing. Gaussians are sorted by depth (using an on‑chip radix‑sort engine) and rendered one by one in depth order. All pixels affected by a given Gaussian are computed in a single pass, after which the accelerator proceeds to the next Gaussian. Consequently, each Gaussian’s parameters are fetched from on‑chip SRAM only once, eradicating the repeated loads that plague tile‑based approaches.
A complementary alpha‑based boundary identification method is introduced to compute tight per‑Gaussian screen regions. By expanding the α computation and applying early termination, the method derives compact bounding boxes that further cut down the number of pixels processed without sacrificing visual fidelity.
The hardware is implemented in 28 nm CMOS. Its architecture comprises a conditional execution pipeline, a depth‑sorting unit, high‑bandwidth on‑chip SRAM for Gaussian parameters and index tables, and an α‑boundary computation block. The design enables fine‑grained scheduling of preprocessing and rendering, and supports the Gaussian‑wise access pattern efficiently.
Experimental evaluation on several benchmark scenes (Lego, Train, Truck, Playroom, DrJohnson) shows that GCC achieves an average 5.24× speedup and 3.35× area‑normalized energy‑efficiency over the state‑of‑the‑art GSCore accelerator. Peak throughput reaches 667 FPS on the Lego dataset. Detailed profiling reveals that preprocessing time drops by >40 % and memory traffic from redundant Gaussian loads is reduced by >70 %.
In summary, GCC demonstrates that rethinking the data flow of 3DGS—by conditionally skipping unused Gaussians and rendering each Gaussian only once—can dramatically improve both performance and energy consumption, making high‑quality neural rendering feasible on resource‑constrained platforms such as mobile devices and AR headsets.
Comments & Academic Discussion
Loading comments...
Leave a Comment