Memory Hierarchy Design for Caching Middleware in the Age of NVM
Advances in storage technology have introduced Non-Volatile Memory, NVM, as a new storage medium. NVM, along with Dynamic Random Access Memory (DRAM), Solid State Disk (SSD), and Disk present a system designer with a wide array of options in designing caching middleware. Moreover, design decisions to replicate a data item in more than one level of a caching memory hierarchy may enhance the overall system performance with a faster recovery time in the event of a memory failure. Given a fixed budget, the key configuration questions are: Which storage media should constitute the memory hierarchy? What is the storage capacity of each hierarchy? Should data be replicated or partitioned across the different levels of the hierarchy? We model these cache configuration questions as an instance of the Multiple Choice Knapsack Problem (MCKP). This model is guided by the specification of each type of memory along with an application’s database characteristics and its workload. Although MCKP is NP-complete, its linear programming relaxation is efficiently solvable and can be used to closely approximate the optimal solution. We use the resulting simple algorithm to evaluate design tradeoffs in the context of a memory hierarchy for a Key-Value Store (e.g., memcached) as well as a host-side cache (e.g., Flashcache). The results show selective replication is appropriate with certain failure rates and workload characteristics. With a slim failure rate and frequent data updates, tiering of data across the different storage media that constitute the cache is superior to replication.
💡 Research Summary
The paper addresses the emerging challenge of designing a memory hierarchy for caching middleware in the era of Non‑Volatile Memory (NVM). With the advent of NVM technologies such as PCM, STT‑RAM, and NAND‑Flash, system designers now have a richer palette of storage options—DRAM, SSD, traditional magnetic disks, and various NVM devices—each with distinct latency, bandwidth, reliability, and cost characteristics. The central question the authors pose is: given a fixed monetary budget, which combination of storage media should be used, how much capacity should be allocated to each, and should data be replicated across multiple levels or tiered (single copy) across the hierarchy?
To answer this, the authors develop a formal optimization framework that models the cache as a set of “stashes” (individual storage media). For each stash they capture read/write latency (δ_R, δ_W), read/write bandwidth (β_R, β_W), failure rate, and price per byte. Each data item (a key‑value pair in a KVS or a disk page in a host‑side cache) is characterized by its size, read frequency f_R, write frequency f_W, and the cost of computing it from the permanent store (comp). A placement option P is any subset of stashes on which a copy of the item may reside; the empty set represents “not cached”. For each (item, placement) pair the model computes:
- The read service time Δ_R(P) = min_{s∈P} (δ_R,s + size/β_R,s)
- The write service time Δ_W(P) = Σ_{s∈P} (δ_W,s + size/β_W,s)
- The expected cost of restoring a failed stash, based on a failure rate λ and a per‑failure restoration cost.
The objective is to minimize the overall average service time across all requests, subject to the budget constraint Σ_{items,placements} price(P,item) ≤ M. This is precisely a Multiple‑Choice Knapsack Problem (MCKP): for each item we must choose exactly one placement option, and each placement consumes a portion of the budget proportional to the size of the item and the per‑byte cost of the selected stashes.
MCKP is NP‑complete, but the authors exploit the fact that its linear‑programming (LP) relaxation can be solved efficiently. Their algorithm first solves the LP to obtain fractional allocations of capacity to each stash, then rounds these values to realistic purchase granularity (e.g., megabytes or gigabytes). A greedy integer‑selection step then picks the most cost‑effective placement options for each item, guaranteeing a solution that is provably close to optimal in practice.
The framework is applied to two representative caching scenarios:
- Application‑side cache (Key‑Value Store) – exemplified by memcached in front of a database such as MySQL. Workloads are highly read‑heavy (e.g., 500 reads per write).
- Host‑side cache – exemplified by Dell Fluid Cache that stages disk pages on faster media before they reach the permanent storage area network.
For both cases the authors construct realistic parameter tables for DRAM, two representative NVM technologies (NVM1, NVM2), SSD (Flash), and magnetic Disk. They then run trace‑driven simulations using social‑network workloads (BG, LinkBench) and synthetic mixes, varying budget, failure rate, and read/write ratios.
Key findings include:
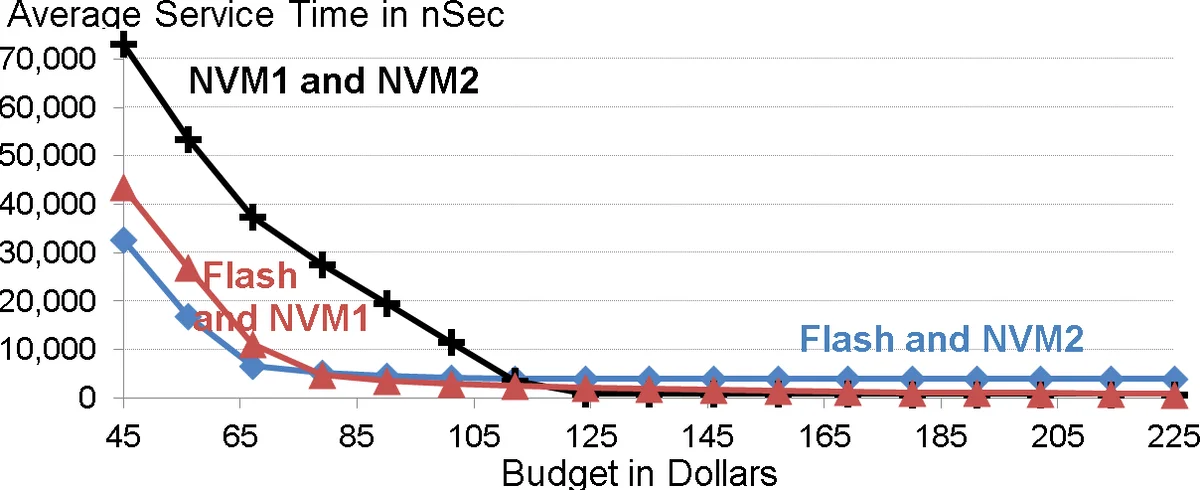
- Budget‑driven media selection – At very low budgets, cheap NAND Flash outperforms DRAM because its lower price allows a larger cache, reducing average service time. As budget grows, NVM devices become preferable to DRAM for most budgets, except when the budget is large enough to hold the entire dataset in DRAM.
- Replication vs. tiering – Replication reduces recovery time after a stash failure but incurs additional write overhead. The model shows that when failure rates are high or workloads are read‑dominant, selective replication of hot items yields measurable latency reductions. Conversely, with slim failure rates and frequent updates, tiering (single copy) is superior because write amplification dominates.
- Diminishing returns – Beyond a certain budget threshold (dependent on dataset size and access skew), adding more capacity or faster media yields marginal service‑time improvements.
- Multiple near‑optimal configurations – The optimization often produces several distinct placements with virtually identical average latency, giving designers flexibility to prioritize secondary criteria such as power consumption or operational complexity.
- Algorithmic flexibility – Because the input parameters are abstracted, the same optimizer can accommodate new NVM technologies, different cost models, or alternative failure assumptions (e.g., simultaneous multi‑stash failures).
The paper also discusses extensions such as dynamic re‑allocation in response to workload shifts, handling of concurrent writes to replicated copies, and the impact of metadata management overhead. Future work is outlined in areas of online adaptive placement, multi‑tenant fairness, and integration with existing cache management frameworks.
In summary, the authors present a rigorous, yet practical, methodology for configuring multi‑level caches that include emerging NVM technologies. By casting the design problem as an MCKP and solving its LP relaxation, they provide system architects with a tool that balances cost, performance, and reliability, and they validate its effectiveness through extensive trace‑driven experiments on realistic workloads. This contribution is highly relevant for the design of next‑generation in‑memory services, large‑scale web applications, and high‑performance data analytics platforms that must judiciously exploit the trade‑offs offered by the evolving memory hierarchy.
Comments & Academic Discussion
Loading comments...
Leave a Comment