From Concept to Practice: an Automated LLM-aided UVM Machine for RTL Verification
Verification presents a major bottleneck in Integrated Circuit (IC) development, consuming nearly 70% of the total development effort. While the Universal Verification Methodology (UVM) is widely used in industry to improve verification efficiency through structured and reusable testbenches, constructing these testbenches and generating sufficient stimuli remain challenging. These challenges arise from the considerable manual coding effort required, repetitive manual execution of multiple EDA tools, and the need for in-depth domain expertise to navigate complex designs.Here, we present UVM^2, an automated verification framework that leverages Large Language Models (LLMs) to generate UVM testbenches and iteratively refine them using coverage feedback, significantly reducing manual effort while maintaining rigorous verification standards.To evaluate UVM^2, we introduce a benchmark suite comprising Register Transfer Level (RTL) designs of up to 1.6K lines of code.The results show that UVM^2 reduces testbench setup time by up to UVM^2 compared to experienced engineers, and achieve average code and function coverage of 87.44% and 89.58%, outperforming state-of-the-art solutions by 20.96% and 23.51%, respectively.
💡 Research Summary
The paper introduces UVM², an automated verification framework that harnesses large language models (LLMs) to generate Universal Verification Methodology (UVM) testbenches and iteratively improve stimulus generation using coverage feedback. The authors identify two major pain points in functional verification: (1) the labor‑intensive creation of hierarchical UVM testbenches, which often balloon to four‑to‑five times the size of the original RTL, and (2) the difficulty of achieving comprehensive functional coverage because test‑case creation and refinement are manual, error‑prone, and time‑consuming.
UVM² addresses these challenges with a three‑agent architecture:
-
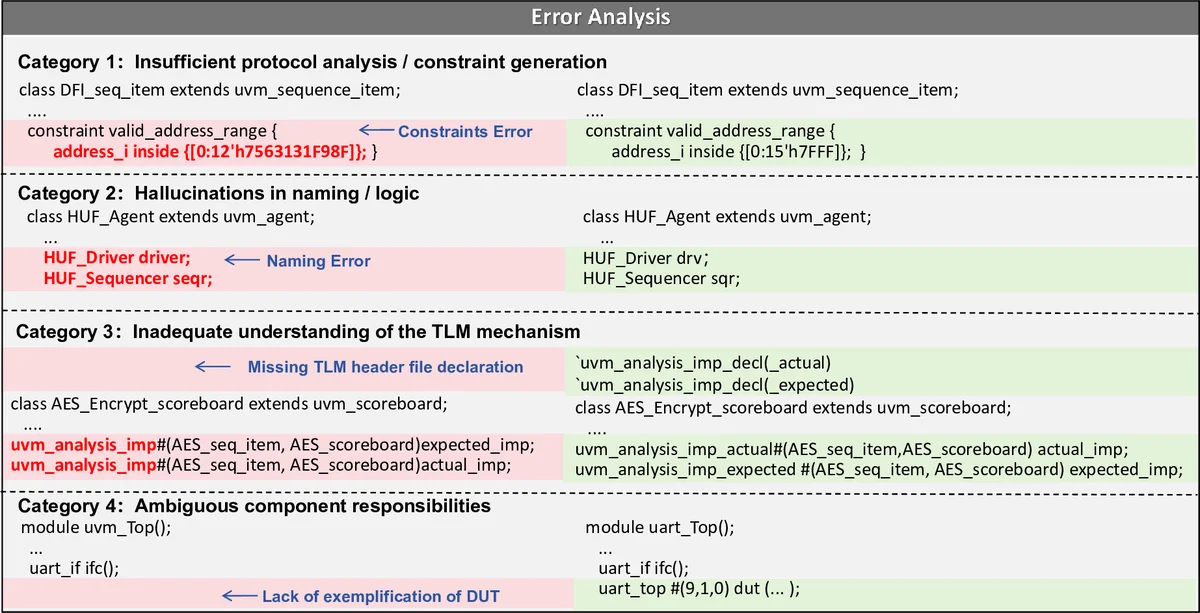
Analysis Agent (AgentA) parses a Markdown design specification, adopts a role‑customized prompt that makes the LLM act as a verification engineer, extracts functional points, and produces a structured test‑plan template. This step ensures deterministic extraction of requirements and reduces hallucination.
-
Generation Agent (AgentG) consumes the test‑plan and builds a complete UVM testbench. A dependency‑driven flow orders component creation (interface → driver/monitor → sequencer → agent → environment → scoreboard → top). Regular, structural components are instantiated from pre‑validated SystemVerilog templates, while behavior‑rich modules (e.g., transaction sequencing, protocol checks) are generated by the LLM. This hybrid template + LLM strategy balances speed, correctness, and flexibility.
-
Optimization Agent (AgentO) runs the generated testbench in a simulator, collects code and functional coverage reports, and identifies uncovered functional points. It then prompts the LLM to synthesize targeted sequences that specifically exercise the missing scenarios. The process repeats until user‑defined coverage goals or iteration limits are met.
The framework requires only three inputs that already exist in typical industrial flows: a design specification (Markdown), a JSON configuration file (DUT name, reset state, etc.), and the RTL source. All artifacts are exchanged in standard formats, allowing seamless integration with existing EDA tools and easy substitution of LLMs or additional verification stages.
Evaluation: The authors assembled a benchmark of ten real‑world RTL designs ranging from 400 to 1,600 lines of code. Compared with experienced verification engineers, UVM² reduced testbench setup time by up to 38.82 ×. Coverage results show an average code coverage of 87.44 % and functional coverage of 89.58 %, which are 20.96 % and 23.51 % higher, respectively, than the best prior LLM‑assisted solutions (MEIC, UVLLM). Importantly, UVM² operates within a full UVM workflow, scaling to realistic design sizes that earlier works could not handle.
Contributions:
- An end‑to‑end, domain‑aware LLM‑driven pipeline that automatically produces industrial‑grade UVM testbenches.
- A coverage‑feedback loop that iteratively refines stimulus, achieving higher verification quality with minimal human intervention.
- Open‑source release of the framework, templates, and benchmark suite to foster reproducibility and community adoption.
Limitations and Future Work: The approach relies heavily on the quality of prompts and the LLM’s pre‑training data; poorly crafted prompts can still lead to logical errors. The current implementation is tied to SystemVerilog/UVM, so extending to other verification languages (e.g., e, SystemC) will require additional engineering. Moreover, the iterative coverage loop incurs simulation cost, which may diminish time‑saving benefits for extremely large designs. Future directions include multi‑model ensembles, integration with alternative verification methodologies, and smarter sampling techniques to reduce the number of simulation iterations.
In summary, UVM² demonstrates that large language models, when combined with carefully designed prompts and template‑based synthesis, can dramatically automate the most tedious aspects of functional verification, delivering substantial productivity gains and higher coverage without sacrificing adherence to industry‑standard UVM practices.
Comments & Academic Discussion
Loading comments...
Leave a Comment