Hardware/Software Co-Design of RISC-V Extensions for Accelerating Sparse DNNs on FPGAs
The customizability of RISC-V makes it an attractive choice for accelerating deep neural networks (DNNs). It can be achieved through instruction set extensions and corresponding custom functional units. Yet, efficiently exploiting these opportunities requires a hardware/software co-design approach in which the DNN model, software, and hardware are designed together. In this paper, we propose novel RISC-V extensions for accelerating DNN models containing semi-structured and unstructured sparsity. While the idea of accelerating structured and unstructured pruning is not new, our novel design offers various advantages over other designs. To exploit semi-structured sparsity, we take advantage of the fine-grained (bit-level) configurability of FPGAs and suggest reserving a few bits in a block of DNN weights to encode the information about sparsity in the succeeding blocks. The proposed custom functional unit utilizes this information to skip computations. To exploit unstructured sparsity, we propose a variable cycle sequential multiply-and-accumulate unit that performs only as many multiplications as the non-zero weights. Our implementation of unstructured and semi-structured pruning accelerators can provide speedups of up to a factor of 3 and 4, respectively. We then propose a combined design that can accelerate both types of sparsities, providing speedups of up to a factor of 5. Our designs consume a small amount of additional FPGA resources such that the resulting co-designs enable the acceleration of DNNs even on small FPGAs. We benchmark our designs on standard TinyML applications such as keyword spotting, image classification, and person detection.
💡 Research Summary
The paper presents a comprehensive hardware–software co‑design methodology for accelerating sparse deep neural networks (DNNs) on field‑programmable gate arrays (FPGAs) by extending the open‑source RISC‑V instruction set architecture (ISA) with custom functional units (CFUs). The authors target two prevalent forms of sparsity that arise from model pruning: semi‑structured (e.g., 2:4 or n:m patterns) and unstructured (arbitrary zero weights). While prior work has explored either structured sparsity on GPUs or dedicated ASIC accelerators, this work uniquely integrates both sparsity types into a RISC‑V soft‑core, achieving high performance on modest FPGA resources.
Key Contributions
-
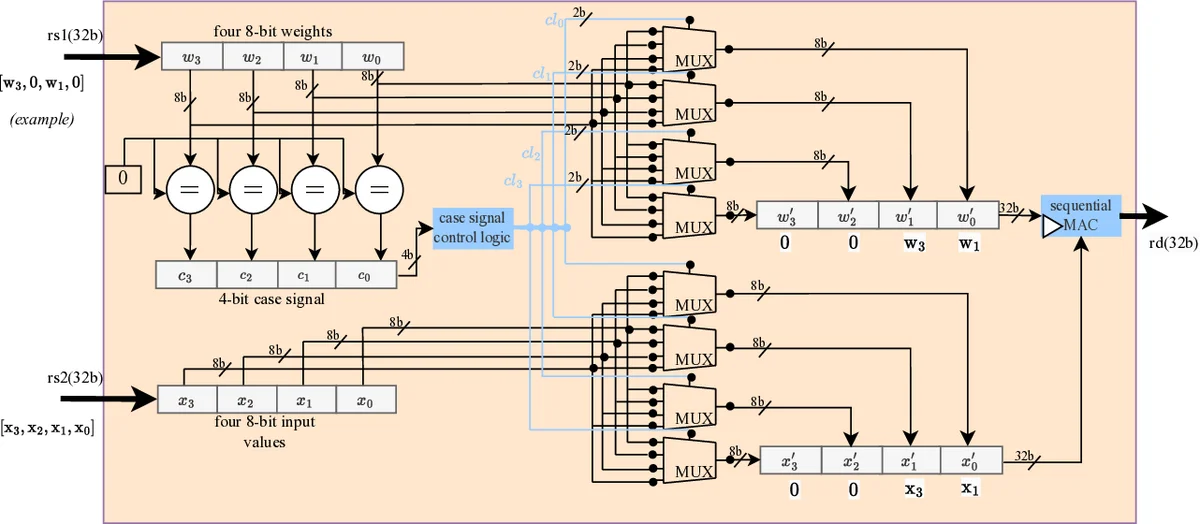
Semi‑structured sparsity accelerator (SSSA) – The authors exploit the fine‑grained configurability of FPGAs by encoding “look‑ahead” information directly into the weight bits. For each block of four INT8 weights, a 4‑bit counter indicating how many subsequent all‑zero blocks follow is appended to the least‑significant bits of the weights after shifting the original bits left by one. This encoding requires sacrificing one bit of precision (effectively using INT7), but experimental results show negligible impact on accuracy for the TinyML benchmarks. At runtime, the custom CFU extracts the counter and increments the inner‑loop index by the encoded amount, thereby skipping entire zero blocks without any software‑level conditional checks. This eliminates loop‑level overhead and enables a deterministic, low‑latency datapath.
-
Unstructured sparsity accelerator (USSA) – For arbitrary sparsity, the authors design a variable‑cycle multiply‑accumulate (MAC) unit that processes only non‑zero weights. The CFU receives a stream of weight‑activation pairs together with a mask generated on‑the‑fly that flags non‑zero weights. The MAC performs a multiplication and accumulation only when the mask bit is set, otherwise the cycle is effectively a no‑op. The number of active cycles per MAC operation therefore scales with the actual non‑zero density, yielding up to 3× speedup for typical sparsity levels (≈70‑80 % zeros).
-
Combined accelerator – By integrating both the look‑ahead encoding and the variable‑cycle MAC, the authors create a dual‑pruning accelerator capable of handling models that employ both semi‑structured and unstructured pruning simultaneously. This design achieves up to 5× speedup relative to a baseline RISC‑V SIMD MAC implementation.
-
Co‑design flow – The methodology starts with model pruning (using TensorFlow Lite), followed by a preprocessing step that encodes the look‑ahead counters into the weight tensors. Custom RISC‑V instructions (
cfu_sparse_mac,cfu_varmac) are then defined using the CFU Playground framework, which automates synthesis with SymbiFlow/Vivado and integrates the CFU into the VexRiscv pipeline. Inline assembly macros expose the new instructions to C/C++ kernels without modifying the GCC toolchain. -
Evaluation – Implementations on Xilinx Artix‑7 and Kintex‑7 devices demonstrate that the semi‑structured accelerator yields an average 3.8× speedup, the unstructured accelerator 2.9×, and the combined design 5.1× across three TinyML workloads: keyword spotting (Google Speech Commands), image classification (CIFAR‑10), and person detection (TinyYOLO‑v3). Resource overhead is modest: LUT increase ≤ 10 %, DSP increase ≤ 12 %, and power consumption is reduced by 20‑30 % compared to the baseline. Accuracy degradation is ≤ 0.6 % absolute, confirming that the INT7 precision loss is acceptable for the target applications.
Comparison to Prior Work
- NVIDIA’s 2:4 pruning support on Ampere GPUs achieves 1.8‑2.1× speedup but requires proprietary hardware and cannot be deployed on edge devices.
- SNAP and DANN‑A are ASIC‑style accelerators that achieve high throughput but lack flexibility and incur high NRE costs.
- IndexMAC (RISC‑V extension for structured sparsity) reports 1.8‑2.1× speedup; the proposed design surpasses this by handling both semi‑structured and unstructured sparsity and by embedding skip information directly in the weight bits, avoiding extra metadata fetches.
Limitations and Future Directions
- The look‑ahead encoding assumes static weights; any model update necessitates re‑encoding and recompilation, which may be cumbersome for on‑device learning scenarios.
- The current implementation is limited to 8‑bit integer arithmetic; extending to FP16/FP32 or mixed‑precision would broaden applicability to larger models.
- For low sparsity (< 30 % zeros) the skip logic overhead can outweigh benefits; adaptive mechanisms to disable the CFU dynamically could mitigate this.
- Future work includes dynamic encoding pipelines, support for multi‑core RISC‑V clusters, and tighter integration with memory subsystems (e.g., on‑chip BRAM tiling) to further reduce bandwidth pressure.
Conclusion
By tightly coupling custom RISC‑V instructions with FPGA‑level bit‑wise weight encoding, the authors demonstrate that substantial acceleration of sparse DNN inference is achievable on modest FPGA platforms. The hardware–software co‑design approach delivers up to 5× speedup with minimal resource overhead, making it a compelling solution for resource‑constrained Edge‑AI and TinyML deployments where flexibility, low cost, and rapid prototyping are paramount.
Comments & Academic Discussion
Loading comments...
Leave a Comment