LODAP: On-Device Incremental Learning Via Lightweight Operations and Data Pruning
Incremental learning that learns new classes over time after the model’s deployment is becoming increasingly crucial, particularly for industrial edge systems, where it is difficult to communicate with a remote server to conduct computation-intensive learning. As more classes are expected to learn after their execution for edge devices. In this paper, we propose LODAP, a new on-device incremental learning framework for edge systems. The key part of LODAP is a new module, namely Efficient Incremental Module (EIM). EIM is composed of normal convolutions and lightweight operations. During incremental learning, EIM exploits some lightweight operations, called adapters, to effectively and efficiently learn features for new classes so that it can improve the accuracy of incremental learning while reducing model complexity as well as training overhead. The efficiency of LODAP is further enhanced by a data pruning strategy that significantly reduces the training data, thereby lowering the training overhead. We conducted extensive experiments on the CIFAR-100 and Tiny- ImageNet datasets. Experimental results show that LODAP improves the accuracy by up to 4.32% over existing methods while reducing around 50% of model complexity. In addition, evaluations on real edge systems demonstrate its applicability for on-device machine learning. The code is available at https://github.com/duanbiqing/LODAP.
💡 Research Summary
The paper addresses the growing need for on‑device incremental learning (ODIL) in industrial edge scenarios where frequent communication with remote servers is impractical due to privacy, bandwidth, or power constraints. The authors propose LODAP, a lightweight framework that enables a deployed model to continuously acquire new classes while keeping computational and memory footprints low.
The core of LODAP is the Efficient Incremental Module (EIM). EIM retains conventional convolutional layers to produce “Intrinsic Features” (InTFs) that are frozen during incremental phases. To learn representations for newly introduced classes, EIM adds a set of tiny convolutional blocks called “adapters”. Each adapter operates on the intrinsic feature maps with a 1×1 (or 3×3 for cheap features) kernel, generating “Incremental Features” (InCFs) specific to the new task. Because adapters contain far fewer parameters than a full convolutional layer, they add capacity without substantially increasing model size.
A potential drawback of repeatedly adding adapters is the growth of memory usage over many incremental steps. LODAP solves this with structural re‑parameterization (adapter fusion). After each incremental stage, the newly learned adapter weights are zero‑padded to match the shape of the existing cheap‑feature kernels and then summed with them. Consequently, at inference time the adapters are merged into a single convolutional kernel, eliminating any extra runtime cost. This technique is inspired by RepVGG and has been shown to preserve accuracy while simplifying the model.
To further reduce training overhead, LODAP incorporates a progressive data‑pruning strategy based on the Error L2‑Norm (EL2N) score. During the early epochs of a new incremental phase, the L2 norm of the loss gradient for each sample is computed; samples with low EL2N scores are deemed less informative and are removed from the training set. This pruning cuts the amount of data by roughly 50 % and, surprisingly, can slightly improve final accuracy by discarding noisy or redundant examples.
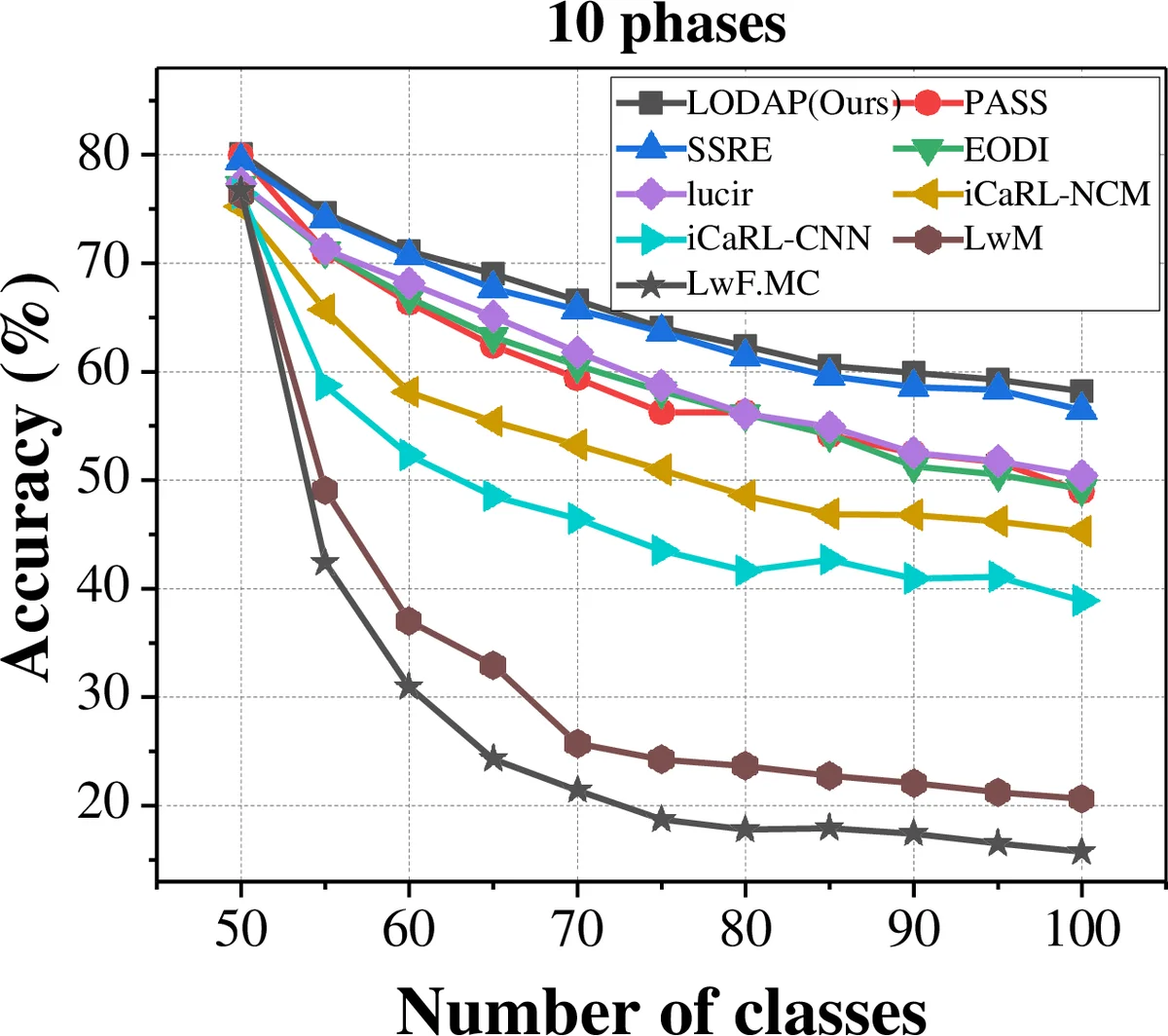
The authors evaluate LODAP on CIFAR‑100 and Tiny‑ImageNet, partitioned into ten incremental stages each. Compared with state‑of‑the‑art incremental methods such as iCaRL, DER, and SSRE, LODAP achieves up to a 4.32 % absolute gain in top‑1 accuracy while using only about half the number of parameters. Ablation studies confirm that both the adapter‑based EIM and the EL2N‑based pruning contribute independently to the performance boost.
Real‑world feasibility is demonstrated on two edge platforms: an NVIDIA Jetson Nano and a Qualcomm Snapdragon 845. On these devices, LODAP reduces training time and energy consumption by 30 %–45 % relative to baseline methods, confirming its suitability for resource‑constrained environments. Sensitivity analyses show that setting the adapter expansion factor s = 2 (one adapter per intrinsic channel) and pruning roughly 40 %–60 % of the data yields the best trade‑off between accuracy and efficiency.
Limitations include the need to tune adapter hyper‑parameters and pruning ratios for each new deployment, and the lack of evaluation on continuous streaming data where class distribution may shift rapidly. Nonetheless, LODAP presents a compelling combination of lightweight architectural extensions, clever parameter merging, and data‑efficient training that together enable practical on‑device incremental learning for edge AI applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment