ExFace: Expressive Facial Control for Humanoid Robots with Diffusion Transformers and Bootstrap Training
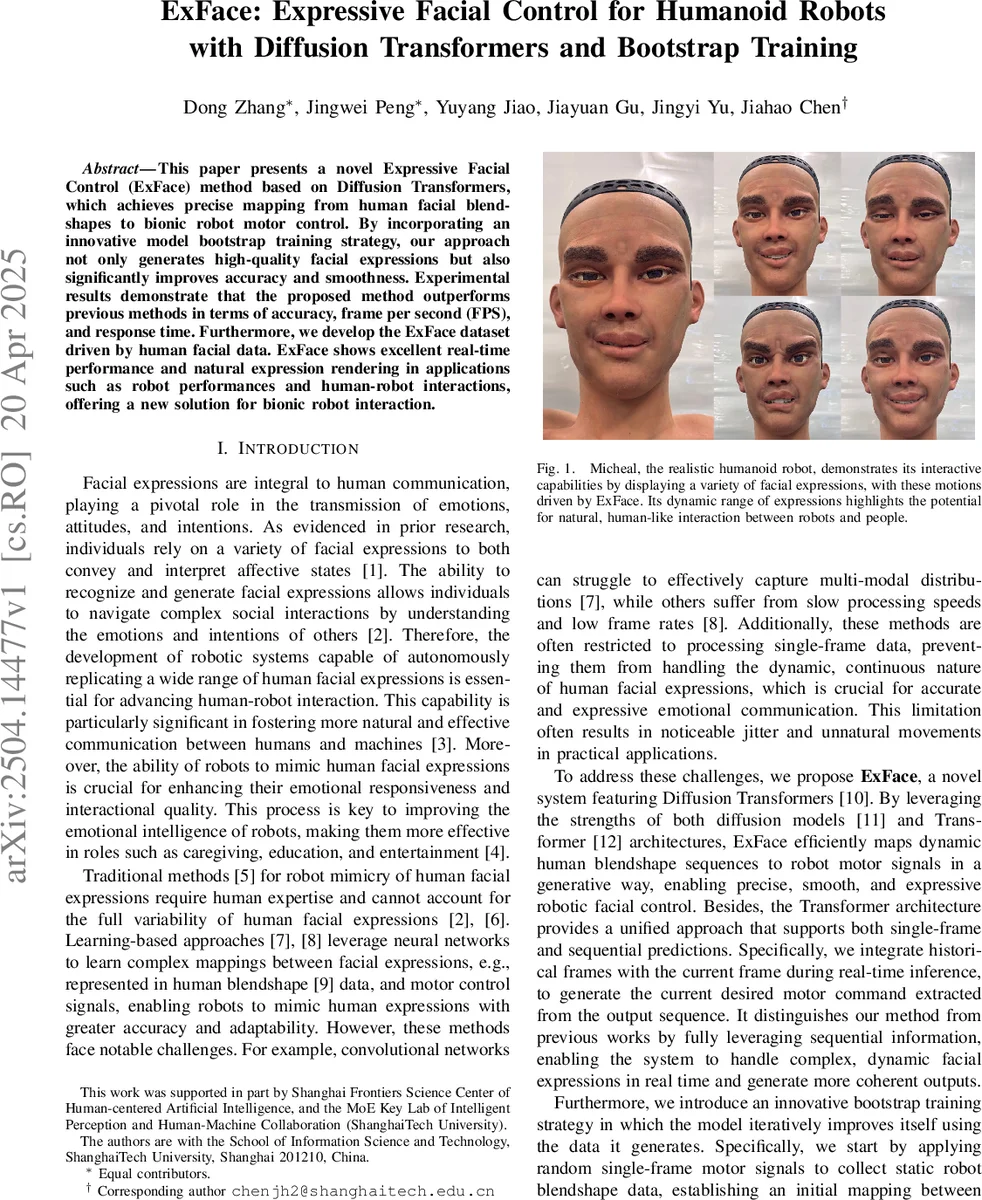
This paper presents a novel Expressive Facial Control (ExFace) method based on Diffusion Transformers, which achieves precise mapping from human facial blendshapes to bionic robot motor control. By incorporating an innovative model bootstrap training strategy, our approach not only generates high-quality facial expressions but also significantly improves accuracy and smoothness. Experimental results demonstrate that the proposed method outperforms previous methods in terms of accuracy, frame per second (FPS), and response time. Furthermore, we develop the ExFace dataset driven by human facial data. ExFace shows excellent real-time performance and natural expression rendering in applications such as robot performances and human-robot interactions, offering a new solution for bionic robot interaction.
💡 Research Summary
The paper introduces ExFace, a novel expressive facial control framework for humanoid robots that maps human facial blendshape parameters to robot motor commands with high precision, smoothness, and real‑time performance. The authors identify three major shortcomings in prior work: (1) template‑based or static methods lack adaptability to the full variability of human expressions; (2) existing learning‑based approaches (e.g., CNNs, MLPs) either struggle to capture multimodal distributions or suffer from low frame rates and jitter because they process single frames independently; and (3) there is a scarcity of large, high‑quality datasets linking human expressions to robot actuation.
To address these issues, ExFace combines two cutting‑edge ideas. First, it employs a conditional Diffusion Transformer, which integrates the denoising diffusion probabilistic model (DDPM) with a transformer encoder‑decoder. In the forward diffusion process, Gaussian noise is added to the motor‑control sequence over N steps; the reverse process, parameterized by a transformer, progressively removes noise while being conditioned on the 55‑dimensional human blendshape sequence. The self‑attention mechanism enables the model to consider the current frame together with a history of 119 preceding frames, thereby preserving temporal continuity and capturing complex, multimodal relationships between blendshapes and motor values.
Second, the authors propose a bootstrap training strategy that iteratively refines the model using data it generates. Initially, random single‑frame motor signals are applied to the robot to collect a sparse set of 600 static blendshape‑motor pairs. This seed data trains a preliminary model, which is then used to drive the robot with real human blendshape inputs captured via Apple’s ARKit. The robot’s resulting dynamic blendshape sequences are recorded and paired with the motor commands that produced them, augmenting the training set by 4,000–8,000 frames per iteration. Over successive iterations the dataset becomes denser in the human expression domain, and the model’s mean‑squared‑error (MSE) on both motor distance and blendshape distance steadily declines, demonstrating self‑improvement without external labeling.
Data collection relies on ARKit to obtain 55‑dimensional blendshape vectors from both a human operator and the robot’s facial surface. The robot platform, named Michael, possesses 42 DOF in its head, of which 33 DOF are dedicated to facial actuation; a second platform, Hobbs, uses articulated linkages. By focusing on these facial DOFs, the authors isolate expression dynamics from head pose.
Experimental evaluation uses a 2,000‑frame validation sequence containing diverse expressions, speeds, and muscle group activations. Quantitative results show that ExFace outperforms two baselines trained on the same data: a multilayer perceptron (MLP) and a vanilla transformer. Specifically, ExFace achieves a motor‑distance MSE of 0.0353 versus 0.0465 (MLP) and 0.0383 (Transformer), and a blendshape‑distance MSE of 0.0025 versus 0.0039 and 0.0029 respectively. Real‑time performance is validated on a Wi‑Fi TCP/IP control loop, delivering 60 FPS inference and a total system latency of 0.15 seconds from human expression detection to robot actuation. Visual results illustrate reduced jitter and more natural transitions compared with baselines, and cross‑platform tests confirm that the same trained model can be deployed on both Michael and Hobbs without retraining.
The authors acknowledge limitations: the model processes fixed‑length 120‑frame windows, which may restrict handling of very long or abrupt expression changes; ARKit’s sensitivity to lighting and pose may affect robustness in uncontrolled environments; and the current dataset, while publicly released, still covers a limited set of facial identities.
In summary, ExFace demonstrates that a diffusion‑based generative model, when coupled with transformer temporal modeling and an iterative bootstrap training regime, can achieve state‑of‑the‑art accuracy, smoothness, and latency for humanoid robot facial expression retargeting. The approach offers a scalable pathway for future research in expressive human‑robot interaction, where high‑fidelity, real‑time facial mimicry is essential for socially aware robots.
Comments & Academic Discussion
Loading comments...
Leave a Comment