Embedding Shift Dissection on CLIP: Effects of Augmentations on VLM's Representation Learning
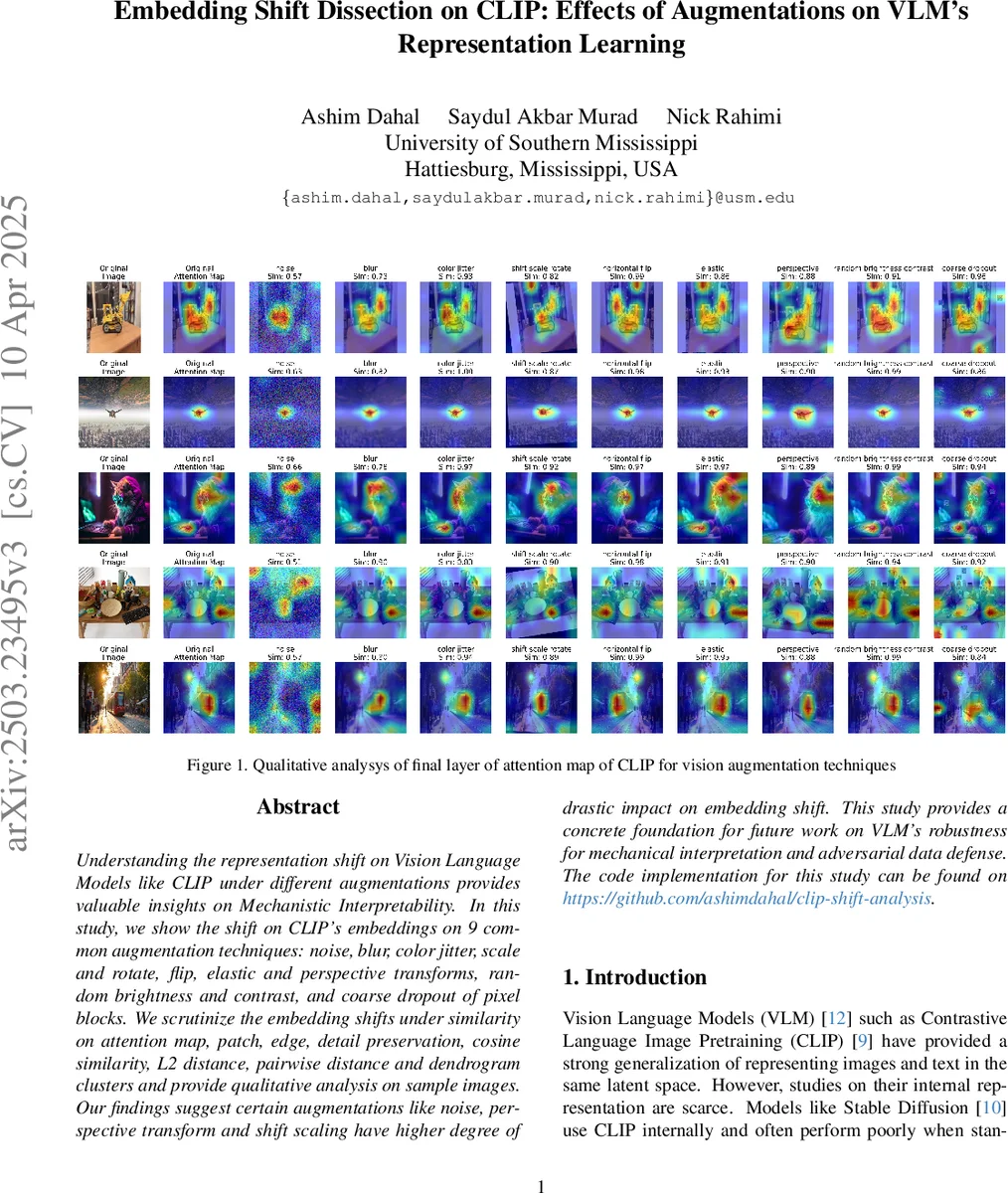
Understanding the representation shift on Vision Language Models like CLIP under different augmentations provides valuable insights on Mechanistic Interpretability. In this study, we show the shift on CLIP’s embeddings on 9 common augmentation techniques: noise, blur, color jitter, scale and rotate, flip, elastic and perspective transforms, random brightness and contrast, and coarse dropout of pixel blocks. We scrutinize the embedding shifts under similarity on attention map, patch, edge, detail preservation, cosine similarity, L2 distance, pairwise distance and dendrogram clusters and provide qualitative analysis on sample images. Our findings suggest certain augmentations like noise, perspective transform and shift scaling have higher degree of drastic impact on embedding shift. This study provides a concrete foundation for future work on VLM’s robustness for mechanical interpretation and adversarial data defense. The code implementation for this study can be found on \href{https://github.com/ashimdahal/clip-shift-analysis}{https://github.com/ashimdahal/clip-shift-analysis}.
💡 Research Summary
This paper investigates how nine common image augmentation techniques affect the internal representations of the CLIP vision‑language model. The authors select noise, Gaussian blur, color jitter, shift‑scale‑rotate, horizontal flip, elastic transform, perspective transform, random brightness‑contrast, and coarse dropout as the augmentation set. Using a subset of 13,312 validation images from the Conceptual Captions dataset (with an additional 2,000‑image sample for detailed metric computation), they process each image through CLIP‑base‑patch32 and compute a suite of quantitative metrics: cosine similarity, Euclidean (L2) distance, attention‑map shift (mean‑squared difference), patch similarity (MSE over 16×16 patches), edge similarity (Sobel‑based absolute difference), and detail similarity (log‑ratio of patch standard deviations). They also perform hierarchical clustering (dendrogram) on the average distances between original and augmented embeddings.
The methodology is clearly laid out: augmentations are implemented via the Albumentations library with fixed hyper‑parameters (e.g., Gaussian noise σ = 0.44–0.88, perspective scale = 0.05–0.1). All metrics are averaged across the full 13k set (SciPy‑based similarity/distance) or the 2k subset (custom metrics). The authors provide explicit formulas for each metric and detail implementation notes such as grayscale conversion and gradient computation.
Results show a consistent pattern: additive noise produces the largest embedding drift, reflected in the lowest cosine similarity, highest L2 distance, and greatest attention‑map divergence. Perspective transform and shift‑scale‑rotate follow closely, indicating that geometric distortions significantly perturb CLIP’s visual encoder. In contrast, brightness‑contrast adjustments and horizontal flips cause minimal changes across all metrics, suggesting that CLIP is relatively invariant to color‑intensity shifts and simple mirroring. Blur, color jitter, and coarse dropout occupy an intermediate position, with noticeable but not extreme shifts.
Attention‑map analysis reveals that geometric augmentations disperse the focus of the final attention layer, reducing the concentration on primary objects. Noise, in particular, leads to a highly scattered attention pattern, while blur reduces object fixation without dramatically altering overall attention magnitude. Patch‑level analyses confirm that color‑variant augmentations (color jitter, coarse dropout) degrade local texture and edge information, whereas geometric augmentations primarily affect spatial arrangement rather than texture fidelity.
Hierarchical clustering groups embeddings into distinct clusters: noise forms its own isolated cluster, while blur, shift‑scale‑rotate, and perspective transform cluster together, reflecting similar types of representation change. The authors visualize these findings with KDE plots of L2 distances, cosine‑similarity histograms, and radar plots that combine all metrics for each augmentation, providing an intuitive “performance profile” for each transformation.
The discussion interprets these findings in the context of mechanistic interpretability. The strong correlation between attention‑map shift and cosine similarity suggests that attention redistribution is a primary driver of embedding drift. The relative robustness to color‑intensity changes aligns with CLIP’s training on large, diverse internet images where color variations are common. Conversely, sensitivity to high‑frequency noise and perspective distortions points to limitations in the model’s ability to maintain invariant representations under severe geometric perturbations.
The paper concludes that CLIP does not treat all augmentations equally; its visual encoder is more stable under color‑based augmentations than under noise or geometric transformations. The authors propose future work including layer‑wise analysis of attention and representation drift, cross‑modal alignment studies to see whether embedding shifts correlate with textual descriptors of the augmentations, and extending the analysis to other VLMs such as BLIP, Kosmos‑2, and Flamingo. They also suggest exploring more complex transformations like style transfer, domain shift, and adversarial attacks to deepen understanding of VLM robustness.
Overall, the study provides a comprehensive, reproducible framework for quantifying how image augmentations affect CLIP’s latent space, offering valuable insights for robustness evaluation, interpretability research, and the design of augmentation‑aware defenses in multimodal AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment