VADMamba: Exploring State Space Models for Fast Video Anomaly Detection
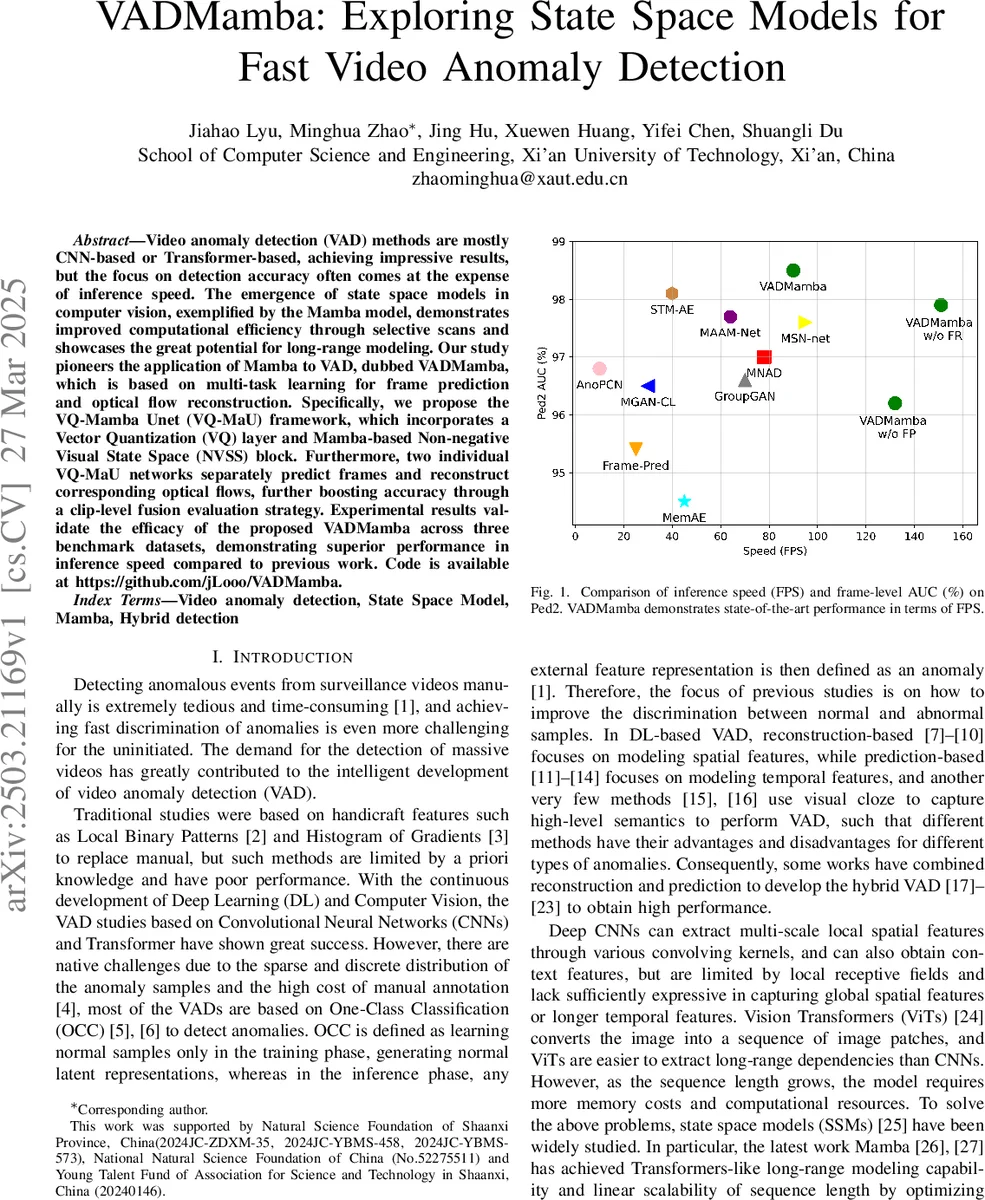
Video anomaly detection (VAD) methods are mostly CNN-based or Transformer-based, achieving impressive results, but the focus on detection accuracy often comes at the expense of inference speed. The emergence of state space models in computer vision, exemplified by the Mamba model, demonstrates improved computational efficiency through selective scans and showcases the great potential for long-range modeling. Our study pioneers the application of Mamba to VAD, dubbed VADMamba, which is based on multi-task learning for frame prediction and optical flow reconstruction. Specifically, we propose the VQ-Mamba Unet (VQ-MaU) framework, which incorporates a Vector Quantization (VQ) layer and Mamba-based Non-negative Visual State Space (NVSS) block. Furthermore, two individual VQ-MaU networks separately predict frames and reconstruct corresponding optical flows, further boosting accuracy through a clip-level fusion evaluation strategy. Experimental results validate the efficacy of the proposed VADMamba across three benchmark datasets, demonstrating superior performance in inference speed compared to previous work. Code is available at https://github.com/jLooo/VADMamba.
💡 Research Summary
Video anomaly detection (VAD) traditionally relies on CNN or Transformer architectures that achieve high detection accuracy at the cost of heavy computation and low inference speed. This paper introduces VADMamba, the first VAD framework that leverages the Mamba state‑space model (SSM) to obtain Transformer‑like long‑range modeling with linear complexity. The core of VADMamba is the VQ‑Mamba Unet (VQ‑MaU), a symmetric U‑shaped encoder‑decoder that integrates three novel components: (1) a Patch Embedding layer that splits the input frame into non‑overlapping 4×4 patches and projects them to 64 channels; (2) a Non‑negative Vision State Space (NVSS) block, which combines the vanilla VSS of Mamba, a 2‑D Selective‑Scan (SS2D) mechanism for global receptive fields, and a Non‑negative Enhanced (NE) module that applies LayerNorm → Linear → ReLU → Conv → BatchNorm to keep activations non‑negative, improve gradient flow, and accelerate convergence; (3) a Vector Quantization (VQ) bottleneck that compresses latent features into a codebook of K entries, thereby preserving normal patterns with low reconstruction error while amplifying errors for anomalous patterns.
Training proceeds in two stages. First, a frame‑prediction (FP) task receives a sequence of t=16 frames and learns to predict the next frame using a loss composed of pixel‑wise L2 error, gradient loss, and the VQ commitment loss. After the FP model converges, its encoder weights initialize the optical‑flow reconstruction (FR) task, which reconstructs the optical flow of the predicted frame. FR’s loss combines flow L2 error, a structural similarity (SSIM) term, a VQ loss, and a motion‑difference regularizer. This sequential training avoids the instability caused by simultaneous optimization of tasks that converge at different speeds.
During inference, the model produces two anomaly scores: PSNR‑based scores from FP (Sp) and from FR (Sr). Both scores are normalized to
Comments & Academic Discussion
Loading comments...
Leave a Comment