A Deep Reinforcement Learning based Scheduler for IoT Devices in Co-existence with 5G-NR
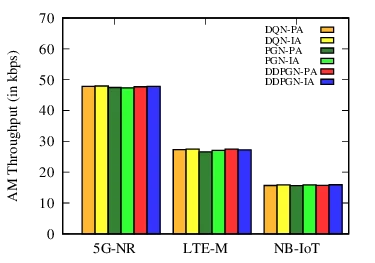
Co-existence of 5G New Radio (5G-NR) with IoT devices is considered as a promising technique to enhance the spectral usage and efficiency of future cellular networks. In this paper, a unified framework has been proposed for allocating in-band resource blocks (RBs), i.e., within a multi-cell network, to 5G-NR users in co-existence with NB-IoT and LTE-M devices. First, a benchmark (upper-bound) scheduler has been designed for joint sub-carrier (SC) and modulation and coding scheme (MCS) allocation that maximizes instantaneous throughput and fairness among users/devices, while considering synchronous RB allocation in the neighboring cells. A series of numerical simulations with realistic ICI in an urban scenario have been used to compute benchmark upper-bound solutions for characterizing performance in terms of throughput, fairness, and delay. Next, an edge learning based multi-agent deep reinforcement learning (DRL) framework has been developed for different DRL algorithms, specifically, a policy-based gradient network (PGN), a deep Q-learning based network (DQN), and an actor-critic based deep deterministic policy gradient network (DDPGN). The proposed DRL framework depends on interference allocation, where the actions are based on inter-cell-interference (ICI) instead of power, which can bypass the need for raw data sharing and/or inter-agent communication. The numerical results reveal that the interference allocation based DRL schedulers can significantly outperform their counterparts, where the actions are based on power allocation. Further, the performance of the proposed policy-based edge learning algorithms is close to the centralized ones.
💡 Research Summary
The paper addresses the challenging problem of jointly allocating in‑band resource blocks (RBs), sub‑carriers (SCs), and modulation‑and‑coding schemes (MCS) for 5G New Radio (5G‑NR) users co‑existing with narrowband IoT (NB‑IoT) and LTE‑M devices in a multi‑cell urban environment. The authors first formulate a benchmark (upper‑bound) scheduler that maximizes instantaneous uplink throughput while guaranteeing proportional fairness across all users and devices. This formulation incorporates realistic constraints such as per‑device power limits, SINR bounds, synchronized RB allocation across neighboring cells, and the need to mitigate severe inter‑cell interference (ICI) that arises when IoT carriers operate in‑band with 5G‑NR. Using a link‑rate model based on a realization‑based approach, the benchmark problem is solved via extensive simulations with realistic ICI parameters, yielding solutions that are close to optimal and serve as a performance reference.
Recognizing that the benchmark problem is NP‑hard and unsuitable for real‑time operation, the authors develop a multi‑agent deep reinforcement learning (DRL) framework. The key novelty is that agents select actions based on observed ICI levels rather than transmit power. Since ICI can be discretized easily and does not require raw data sharing among agents, this approach is well‑suited for edge‑computing deployments where privacy and communication overhead are concerns. Three DRL algorithms are implemented:
- DQN‑IA – a deep Q‑network that learns a discrete Q‑function over ICI‑based states.
- PGN‑IA – a policy‑gradient network that directly optimizes a stochastic policy conditioned on ICI.
- DDPGN‑IA – an actor‑critic deep deterministic policy gradient method where the actor outputs continuous ICI‑based actions and the critic evaluates expected returns.
Both centralized learning (where a central server aggregates experiences) and edge learning (where each gNodeB trains locally without sharing raw data) are evaluated. Results show that the centralized DDPGN‑IA achieves the highest sum‑rate, proportional fairness, and lowest average delay, outperforming power‑based DRL baselines by 12‑18 % in throughput and reducing delay by more than 15 %. Edge‑based PGN‑IA and DQN‑IA attain performance close to the centralized models, demonstrating that the ICI‑driven action space enables efficient learning with minimal inter‑agent communication.
The paper’s contributions are threefold: (i) a rigorous upper‑bound scheduler for joint SC and MCS allocation in a multi‑RAT, multi‑cell scenario; (ii) the introduction of ICI‑based action selection as a new design principle for DRL‑driven radio resource management; and (iii) a comprehensive comparative study of value‑based (DQN) and policy‑based (PGN, DDPG) DRL algorithms under both centralized and edge learning architectures. The findings provide a practical roadmap for deploying real‑time, low‑latency, and spectrally efficient schedulers in future 5G‑NR networks where IoT devices share the same spectrum, highlighting the feasibility of edge‑centric AI solutions that respect privacy and bandwidth constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment