Lifelong Federated Reinforcement Learning: A Learning Architecture for Navigation in Cloud Robotic Systems
This paper was motivated by the problem of how to make robots fuse and transfer their experience so that they can effectively use prior knowledge and quickly adapt to new environments. To address the problem, we present a learning architecture for na…
Authors: Boyi Liu, Lujia Wang, Ming Liu
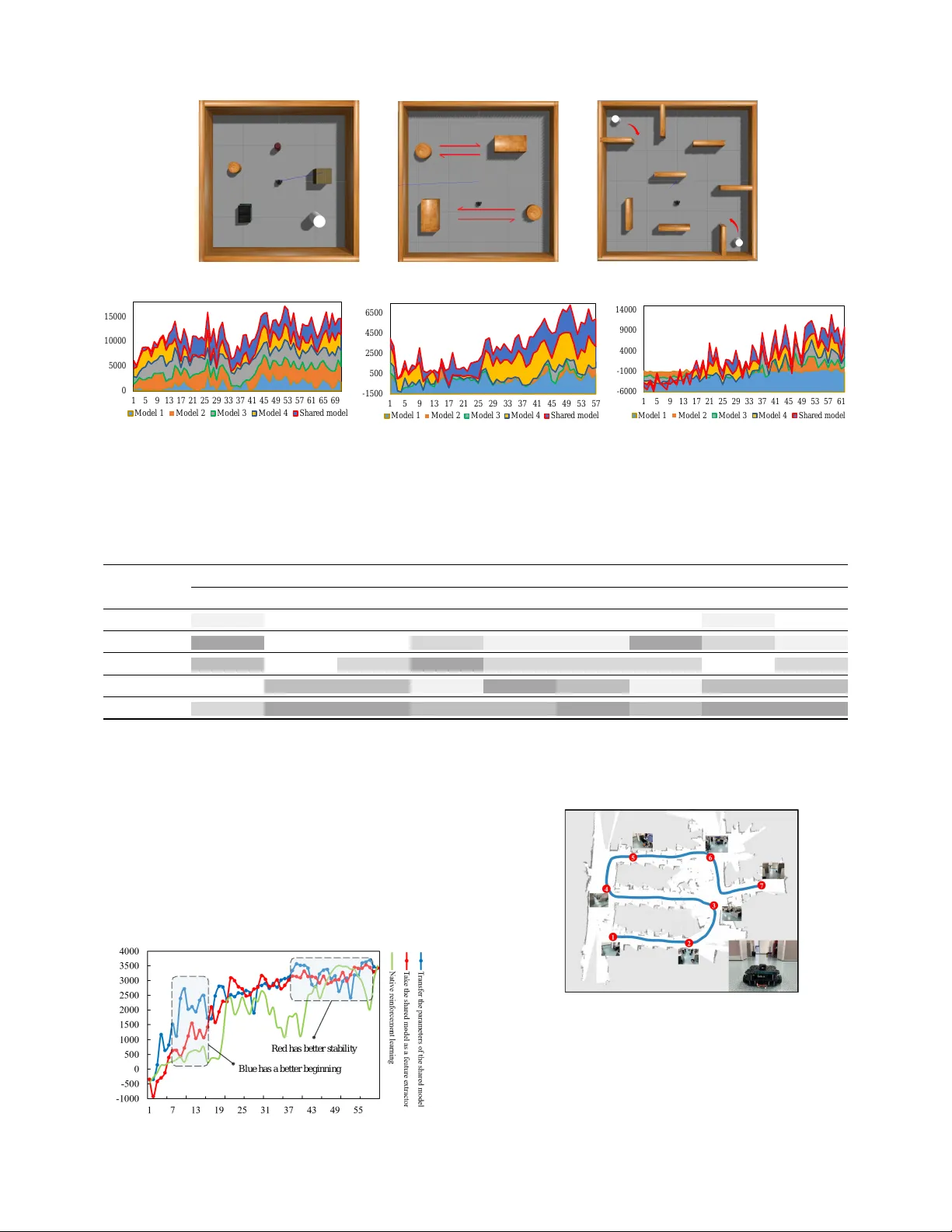
Lifelong F ederated Reinf or cement Learning: A Lear ning Ar chitecture f or Na vigation in Cloud Robotic Systems Boyi Liu 1 , 3 , Lujia W ang 1 and Ming Liu 2 Abstract — This paper was motivated by the problem of how to make robots fuse and transfer their experience so that they can effectively use prior kno wledge and quickly adapt to new en vironments. T o address the pr oblem, we present a learning architectur e for navigation in cloud r obotic systems: Lifelong Federated Reinf orcement Learning (LFRL). In the work, we propose a knowledge fusion algorithm for upgrading a shared model deployed on the cloud. Then, effective transfer learning methods in LFRL are introduced. LFRL is consistent with human cogniti ve science and fits well in cloud robotic systems. Experiments sho w that LFRL greatly impro ves the efficiency of reinf orcement learning f or robot navigation. The cloud robotic system deployment also sho ws that LFRL is capable of fusing prior knowledge. In addition, we release a cloud robotic navigation-lear ning website to provide the service based on LFRL: www .shared-robotics.com . I . I N T RO D U C T I O N Autonomous navigation is one of the core issues in mobile robotics. It is raised among v arious techniques of av oiding obstacles and reaching target position for mobile robotic navigation. Recently , reinforcement learning (RL) algorithms are widely used to tackle the task of navigation. RL is a kind of reacti ve navig ation method, which is an important meaning to improve the real-time performance and adaptability of mobile robots in unkno wn en vironments. Nevertheless, there still exists a number of problems in the application of reinforcement learning in navig ation such as reducing training time, storing data ov er long time, separating from computation, adapting rapidly to ne w en vironments etc [1]. In this paper , we address the problem of how to make robots learn efficiently in a new en vironment and extend their experience so that they can effectively use prior knowledge. W e focus on cloud computing and cloud robotic technologies [2], which can enhance robotic systems by fa- cilitating the process of sharing trajectories, control policies and outcomes of collectiv e robot learning. Inspired by human congnitiv e science present in Fig.1, we propose a L ifelong F ederated R einforcement L earning (LFRL) architecture to realize the goal. With the scalable architecture and knowledge fusion algorithm, LFRL achieves exceptionally efficienc y in *This work was supported by National Natural Science Foundation of China No. 61603376; Guangdong-Hongkong Joint Scheme (Y86400); Shen- zhen Science, T echnology and Innovation Commission (SZSTI) Y79804101S awarded to Dr . Lujia W ang. 1 Boyi liu, Lujia W ang are with Cloud Computing Lab of Shenzhen Institutes of Advanced T echnology , Chinese Academy of Sciences. liuboyi17@mails.ucas.edu.cn ; lj.wang1@siat.ac.cn ; cz.xu@siat.ac.cn 2 Ming liu, is with Department of ECE, Hong Kong Univ ersity of Science and T echnology . eelium@ust.hk 3 Boyi liu is also with the University of Chinese Academy of Sciences. Actor1: The next step may have little effect. Actor3: For the next step, there are two better choices. Actor2: For the next step, there is a very certain decision. ¼¼ Chess The man needs to make decisions based on the rules of the chess, his chess experience and the chess experience of others he has seen. Fig. 1. The person on the right is considering where should the next step go. The chess he has played and the chess he has seen are the most two influential factors on making decisions. His memory fused into his polic y model. So how can robots remember and mak e decisions like humans? Motivated by this human cognitive science, we propose the LFRL in cloud robot systems. LFRL makes the cloud remember what robots learned before like a human brain. reinforcement learning for cloud robot navigation. LFRL en- ables robots to remember what they have learned and what other robots hav e learned with cloud robotic systems. LFRL contains both asynchronization and synchronization learning rather than limited to synchronous learning as A3C [3] or UNREAL [4]. T o demonstrate the efficacy of LFRL, we test LFRL in some public and self-made training en vironments. Experimental result indicates that LFRL is capable of enabling robots effecti vely use prior knowledge and quickly adapt to new environments. Overall, this paper mak es the following contributions: • W e present a Lifelong Federated Reinforcement Learning architecture based on human cognitive science. It makes robots perform lifelong learning of navig ation in cloud robotic systems. • W e propose a knowledge fusion algorithm. It is able to fuse prior kno wledge of robots and e volv e the shared model in cloud robotic systems. • T wo ef fectiv e transfer learning approaches are introduced to mak e robots quickly adapt to ne w en vironments. • A cloud robotic navigation-learning website is built in the work: www .shared-r obotics.com . It provides the service based on LFRL. I I . R E L A T E D T H E O RY A. Reinfor cement learning for navigation Eliminating the requirements for location, mapping or path planning procedures, se veral DRL works have been presented that successful learning navigation policies can be achieved directly from raw sensor inputs: target-dri ven navigation [5], successor feature RL for transferring na vigation policies [6], and using auxiliary tasks to boost DRL training [7]. Many follow-up works have also been proposed, such as embedding SLAM-like structure into DRL networks [8], or utilizing DRL for multi-robot collision av oidance [9]. T ai et al [10] suc- cessfully appplied DRL for mapless na vigation by taking the sqarse 10-dimensional range findings and the target position , defining mobile robot coordinate frame as input and contin- uous steering commands as output. Zhu et al. [5] input both the first-person view and the image of the target object to the A3C model, formulating a target-dri ven navigation problem based on the univ ersal v alue function approximators [11]. T o make the robot learn to navigate, we adopt a reinforcement learning perspective, which is built on recent success of deep RL algorithms for solving challenging control tasks [12-15]. Zhang [16] presented a solution that can quickly adapt to ne w situations (e.g., changing navigation goals and environments). Making the robot quickly adapt to ne w situations is not enough, we also need to consider how to make robots capable of memory and ev olution, which is similar to the main purpose of lifelong learning. B. Lifelong machine learning Lifelong machine learning, or LML [17], considers system that can learn many tasks from one or more domains ov er its lifetime. The goal is to sequentially store learned knowledge and to selectiv ely transfer that knowledge when a robot learns a new task, so as to dev elop more accurate hypotheses or poli- cies. Robots are confronted with different obstacles in different en vironments, including static and dynamic ones, which are similar to the multi-task learning in lifelong learning. Although learning tasks are the same, including reaching goals and av oiding obstacles, their obstacle types are different. There are static obstacles, dynamic obstacles, as well as dif ferent ways of movement in dynamic obstacles. Therefore, it can be regarded as a low-le vel multitasking learning. A lifelong learning should be able to efficiently retain knowledge. This is typically done by sharing a representation among tasks, using distillation or a latent basis [18]. The agent should also learn to selectively use its past knowledge to solve new tasks efficiently . Most works hav e focused on a special transfer mechanism, i.e., they suggested learning differentiable weights are from a shared representation to the ne w tasks [4, 19]. In contrast, Brunskill and Li [20] suggested a temporal transfer mechanism, which identifies an optimal set of skills in ne w tasks. Finally , the agent should have a systematic approach that allows it to ef ficiently retain the kno wledge of multiple tasks as well as an efficient mechanism to transfer knowledge for solving ne w tasks. Chen [21] proposed a lifelong learning system that has the ability to reuse and transfer knowledge from one task to another while ef ficiently retaining the previously learned knowledge-base in Minecraft. Although this method has achie ved good results in Mincraft, there is a lack of multi-agent cooperativ e learning model. Learning different tasks in a same scene is similar but different for robot navigation learning. C. F ederated learning LFRL realizes federated learning of multi robots through knowledge fusion. Federated learning was first proposed in [22], which sho wed its effecti veness through experiments on various datasets. In federated learning systems, the raw data is collected and stored at multiple edge nodes, and a machine learning model is trained from the distrib uted data without sending the raw data from the nodes to a central place [23, 24]. Different from the traditional joint learning method where multiple edges are learning at the same time, LFRL adopts the method of fir st tr aining then fusing to reduce the dependence on the quality of communication[25, 26]. D. Cloud r obotic system LFRL fits well with cloud robotic system. Cloud robotic system usually relies on many other resources from a network to support its operation. Since the concept of the cloud robot was proposed by Dr . Kuf fner of Carnegie Mellon Uni versity (now working at Google company) in 2010 [27], the research on cloud robots is rising gradually . At the beginning of 2011, the cloud robotic study program of RoboEarth [28] was initiated by the Eindhoven University of T echnology . Google engineers hav e developed robot software based on the Android platform, which can be used for remote control based on the Lego mind-storms, iRobot Create and V ex Pro, etc. [29]. W ang et al. present a frame work tar geting near real-time MSDR, which grants asynchronous access to the cloud from the robots [30]. Howe ver , no specific navigation method for cloud robots has been proposed up to no w . W e believe that this is the first navigation learning architecture for cloud robotic systems. Generally , this paper focuses on de veloping a reinforcement learning architecture for robot navigation, which is capable of lifelong federated learning and multi robots federated learning. This architecture is well fit in cloud robot systems. I I I . M E T H O D O L O G Y LFRL is capable of reducing training time without sacri- ficing accuracy of navigating decision in cloud robotic sys- tems. LFRL uses Cloud-Robot-En vironment setup to learn the navigation policy . LFRL consists of a cloud server , a set of environments, and one or more robots. W e develop a federated learning algorithm to fuse priv ate models into the shared model in the cloud. The cloud server fuses priv ate models into the shared model, then e volves the shared model. As illustrated in Fig.2, LFRL is an implementation of lifelong learning for navig ation in cloud robotic systems. Compared with A3C or UNREAL approaches which update parame- ters of the polic y network at the same time, the proposed knowledge fusion approach is more suitable for the federated architecture of LFRL. The proposed approach is capable of fusing models with asynchronous e volution. The approach of updating parameters at the same time has certain requirements for en vironments, while the proposed kno wledge fusion algo- rithm has no requirements for en vironments. Using generative network and dynamic weight labels are able to realize the integration of memory instead of A3C or UNREAL method, which only generates a decision model during learning and Transfor- reinforcement learning Shared Model 2G Transfor- reinforcement learning Transfor-reinforcement learning Private Models Shared Model 4G …… …… …… Ability Lifelong learning Shared Model 1G Shared Model-1G Private Models Shared Model-2G Private Models Shared Model 3G Shared Model-3G Environment 1 Environment 2 Environment 3 Federated Learning Fig. 2. Proposed Architecture. In Robot → En vironment, the robot learns to avoid some new types of obstacles in the new en vironment through reinforcement learning and obtains the private Q-network model. Not only from one robot training in dif ferent en vironments, pri vate models can also be resulted from multiple robots. It is a type of federated learning. After that, the private network will be uploaded to the cloud. The cloud server evolv es the shared model by fusing priv ate models to the shared model. In Cloud → Robot, inspired by transfer learning, successor features are used to transfer the strategy to unknown en vironment. W e input the output of the shared model as added features to the Q-network in reinforcement learning, or simply transfer all parameters to the Q-network. Iterating this step, models on the cloud become increasingly powerful. … A3C/UNREAL LFRL Fig. 3. LFRL compared with A3C or UNREAL has no memory . As illustrated in Fig.3. In the algorithm of A3C or UNREAL, the training environment is constant. States of agents are countable. The central node only needs to fuse parameters, which can be performed at the same time. The two methods are capable of fusing parameters while training. Network structures of agents must be the same. Howe ver , in LFRL, the training en vironment is variable. State of agents are uncountable with more training en vironments uploading. In different agents, the structure of hiden layers of the policy network can be different. The cloud fuse training results. The robots are trained in new en vironments based on the shared model. Robots and the cloud ha ve interactions in upload and download procedures. LFRL is more suitable for the cloud robot system where the environment is uncountable, especially in the lifelong learning framew ork. A. Pr ocedure of LFRL This section displays a practical example of LFRL: there are 4 robots, 3 different en vironments and cloud servers. The first robot obtains its pri vate strategy model Q1 through reinforcement learning in Environment 1 and upload it to the cloud server as the shared model 1G. After a while, Robot 2 and Robot 3 desire to learn na vigation by reinforcement learning in Environment 2 and En vironment 3. In LFRL, Robot 2 and Robot 3 download the shared model 1G as the initial actor model in reinforcement learning. Then they can get their priv ate networks Q2 and Q3 through reinforcement learning in En vironment 2 and Environment 3. After completing the training, LFRL uploads Q2 and Q3 to the cloud. In the cloud, strategy models Q2 and Q3 will be fused into shared model 1G, and then shared model 2G will be generated. In the future, the shared model 2G can be used by other cloud robots. Other robots will also upload their priv ate strate gy models to the cloud serv er to promote the ev olution of the shared model. The more complicated tasks responded to more kinds of obstacles in robot navigation. The learning environment is gigantic in robot navigation learning. This case is dif ferent from the chess. So we borrow the idea of lifelong learning. Local robots will learn to av oid more kinds of obstacles and the cloud will fuse these skills. These skills will be used in more defined and undefined en vironments. For a cloud robotic system, the cloud generates a shared model for a time, which means an e volution in lifelong learning. The continuous ev olution of the shared model in cloud is a lifelong learning pattern. In LFRL, the cloud server achiev es the kno wledge storage and fusion of a robot in dif ferent en vironments. Thus, the shared model becomes powerful through fusing the skills to a void multi types of obstacles. For an indi vidual robot, when the robot downloads the cloud model, the initial Q-network has been defined. Therefore, the initial Q-network has the ability to reach the target and av oid some types of obstacles. It is conceiv able that LFRL can reduce the training time for robots to learn navigation. Furthermore, there is a surprising experiment result that the robot can get higher scores in na vigation with LFRL. Ho wever , Algorithm 1: Processing Algorithm in LFRL Initialize action-value Q-network with random weights θ ; Input: θ a : The parameters of the a-th shared model in cloud ; m : The number of priv ate networks. Output: The ev olved θ a while cloud server is running do if service request=T rue then T ransfer θ a to π ; for i = 1; i ≤ m ; i + + do θ i ← r obot ( i ) perform reinforcement learning with π in en vironment.; Send θ i to cloud; end end if e volve time=T rue then Generate θ a + 1 = fuse ( θ 1 , θ 2 , · · · , θ m , θ a ) θ a ← θ a + 1 end end in actual operation, the cloud does not necessarily fuse models ev ery time it receiv es a priv ate network, but fuses at a fixed frequency rate. So, we present the processing flow of LFRL shown in Algorithm 1. Ke y algorithms in LFRL include knowledge function algorithm and transferring approaches, as introduced in the follo wing. B. Knowledge fusion algorithm in cloud Inspired by images style transfer algorithm, we dev elop a knowledge fusion algorithm to e volv e the shared model. This algorithm is based on generati ve networks and it is efficient to fuse parameters of networks trained from dif ferent robots or a robot in dif ferent en vironments. The algorithm deployed in the cloud serv er recei ves the pri vately transmitted network and upgrades the sharing network parameters. T o address knowledge fusion, the algorithm generates a ne w shared model from private models and the shared model in cloud. This new shared model is the ev olved model. Fig.4 illustrates the process of generating a policy network. The structure of the policy network has the same input and output dimensions with the priv ate policy network. The number of outputs is equal to the number of action types that robots can act. The dimensions of input also correspond with sensor data and human-made features. The training data of the network is randomly generated based on sensor data attributes. The label on each piece of data is dynamically weighted, which is based on the “confidence value” of each robot in each piece of data. W e define robots as actors in reinforcement learning. Dif ferent robots or the same robot in different en vironments are different actors. The “confidence value” motioned abov e of the actor is the degree of confirmation on which action the robot chooses to perform. For example, in a piece of sample from training data, the pri v ate Netw ork 1 e valuates Q-values of dif ferent actions to (85, 85, 84, 83, 86), but the ev aluation of the k- G sharing network is (20, 20, 100, 10, 10). In this case, we are more confident on actor of k-G sharing network, because it has significant differentiation in the scoring process. On the contrary , the scores from actor of priv ate Network 1 are confusing. Therefore, when generating the labels, the algorithm calculates the confidence value according to the score of different actors. Then the scores are weighted with confidence value and summed up. Finally , we obtain labels of training data by executing the above steps for each piece of data. There are several approaches to define confidence, such as variance, standard deviation, and information entropy . From the definition of the abov e statistical indicators we can infer that using variance to describe uncertainty will fail in some cases because it requires uniform distribution of data and ignores the occurrence of extreme ev ents. The variance needs to meet the relev ant premise to describe the uncertainty of the information. Entropy is more suitable for describing the uncertainty of information than variance, which comes from the definition of entropy . Uncertainty is the embodiment of confidence. So, In this work, we use information entropy to define confidence. Formula (1) is quantitativ e function of robotic confidence (information entrop y): Robot j ”confidence”: c j = − 1 ln m m ∑ i = 1 score i j ∑ m i = 1 score i j · ln score i j ∑ m i = 1 score i j ( 1 ) m is the action size of robot, n is the number of priv ate networks. Memory weight of robot j: w j = ( 1 − c j ) ∑ n j = 1 ( 1 − c j ) ( 2 ) Knowledge fusion function: l abel j = score × ( c 1 , c 2 , · · · c m ) T ( 3 ) It should be noted that Fig.4 only shows the process of one sample generating one label. Actually , we need to generate a large number of samples. For each data sample, the confidence values of the actors are different, so the weight of each actor is not the same. For example, when we generate 50,000 different pieces of data, there are nearly 50,000 kinds of dif ferent combinations of confidence. These changing weights can be incorporated into the data labels, and enable the generated network to dynamically adjust the weights on different sensor data. In conclusion, kno wledge fusion algorithm in cloud can be defined as: ω j = ( 1 − c j ) ÷ n ∑ j = 1 ( 1 − c j ) ( 4 ) y i = num ∑ j = 1 c j · ω j ( 5 ) L ( y , h θ ( x i )) = 1 N N ∑ i = 1 ( y i − h θ ( x i )) 2 ( 6 ) θ ∗ = ar g min θ 1 N N ∑ i = 1 L ( y i · h θ ( x i )) ( 7 ) Ra ndom S e ns or D a t a Ra ndom da t a a bou t t a rg e t F e a t ure 1 F e a t ure 2 F e a t ure x G et h u ma n - mad e fe at u re s fr o m s en s o r d at a S h a ri n g N e t w o rk ( k + 1 ) G ( i n c l o u d ) A c t i on 1 A c t i on 2 A c t i on m S c ore 1 S c ore 2 S c ore m S h a ri n g N e t w o rk kG ( i n c l o u d ) P ri v a t e N e t w o rk 1 S c o re 11 S c o re 21 S c o re m 1 P ri v a t e N e t w o rk n S c o re 1 n S c o re 2 n S c o re m n S c o re 1 ( n + 1 ) S c o re 2 ( n + 1 ) S c o re m ( n + 1 ) S c o re 11 S c o re 21 S c o re m 1 S c o re 1 n S c o re 2 n S c o re m n S c o re 1 ( n + 1 ) S c o re 2 ( n + 1 ) S c o re m ( n + 1 ) Sco re M a tri x ( kno w l e dg e s to r a g e ) Kno w l e dg e F us i o n ba s ed C o n fi de nce o f r o bo ts S c o r e = S c ore 1 S c ore 2 S c ore 3 S c ore m La bel Ge n e r at ive N e t w or k s T r ai n i n g Ge ne r a t e l a r ge a m ount s of s a m pl e da t a N o r m a l i z e e a c h c o l u m n Fig. 4. Knowledge Fusion Algorithm in LFRL: W e generate a large amount of training data based on sensor data, target data, and human-defined features. Each training sample is added into the priv ate network and the k-th generation sharing network, while different actors are scored for different actions. Then, we store the scores and calculate the confidence values of all actors in this training sample data. The “confidence value” is used as a weight, while the scores are weighted and summed to obtain the label of the current sample data. By analogy , all sample data labels are generated. Finally , a network is generated and fits the sample data as much as possible. The generated network is the (k+1)th generation. This step of fusion is finished. Formula 4 tak es the proportion of the confidence of robots as a weight. Formula 5 obtains the label of the sensor data by weighted summation. Formula 6 defines the error in the training process of generative network. Formula 7 is the goal of the training process. W e discribe our approach in details in Algorithm 2. For a single robot, priv ate network is obtained in dif ferent en vironments. Therefore, it can be regarded as asynchronous learning of the robot in LFRL. When there are multiple robots, we just need to treat them as the same robot in dif ferent en vironments. At this time, the evolution process is asynchronous, and multiple robots are synchronized. It should be explained that the shared model in the cloud is not the final policy model of the local robot. W e only use the shared model in the cloud as a pre-trained model or a feature extractor . The shared model maintained in the cloud is a cautious policy model but not the optimal for every robot. That is to say , the shared model in the cloud will not make serious mistakes in some pri vate unstructured en vironments but the action is not the best. It is necessary for the robot to train its own policy model based on the shared model from the cloud, otherwise the error rate will be high in its priv ate unstructured environment. As the saying goes, the older the person, the smaller the courage. In the process of lifelong learning, the cloud model will become more and more timid. In order to remove the error rate, we should transfer the shared model and train a new pri vate model through reinforcement learning in a new en vironment. This responded to the transfer learning process in LFRL. C. T ransfer the shar ed model V arious approaches of transfer reinforcement learning have been proposed. In the specific task that a robot learns to navigate, we found that there are two applied approaches. The first one is taking the shared model as initial actor network. While the other one is using the shared model as a feature extractor . If we adopt the first approach that takes the shared model as an initial actor netw ork, abilities of avoiding obstacles and reaching targets can remain the same. In this approach, the robot deserves a good score at the beginning. The e xperimental data shows that the final score of the robot has been greatly improv ed at the same time. Howe ver , every coin has two sides, this approach is unstable. The training time depends on the adjustment of parameters in some extent. For example, we should accelerate updating speed, increase the punishment, reduce the probability of random action etc. The shared model also can be used as a feature extractor in transfer reinforcement learning. As illustrated in Fig.5, this method increases the dimension of the features. So, it can improv e the ef fect stably . One problem that needs to be solved in experiment is that there is a structural difference between input layer of the shared network and pri vate network. The approach in LFRL is that the number of nodes in the input layer is consistent with the number of elements in the original feature vector , as shown in Fig.5. The features from transfer learning are not used as inputs to the shared network. They are just inputs of training priv ate networks. This approach has high applicability , e ven though the shared model and priv ate models ha ve dif ferent network structures. It is also w orth noting that if the robot uses image sensors to acquire images as feature data. It is recommended to use the traditional transfer learning method that taking the output of some con volutional layers as features because the Q-netw ork is a conv olutional neural network. If a non-image sensor such as a laser radar is used, the Q-netw ork is not a conv olutional neural network, then we will use the output of the entire Algorithm 2: Kno wledge Fusion Algorithm Initialize the shared netw ork with random P arameters θ ; Input: K : The number of data samples generated ; N : The number of pri vate networks; M : Action sizes of the robot; Output: θ for i=1,i ≤ N,i++ do ˆ x i ← Calculate indirct features from ˜ x i ; x i ← [ ˜ x i , ˆ x i ] ; for n=1,n ≤ K,n++ do score in ← f n ( x i ) ; score i ← score append scor e in end for n=1,n ≤ K,n++ do for m=1,m ≤ M,m++ do c in ← Calculate the confidence value of the n-th pri vate network in the i-th data based on formula (1) end end l abel i ← Calculate the l abel i based on formula (2) and (3); l abel ← label append l abel i ; end θ ← training the shared network from (x,label); network as additional features, as Fig.5 shows. The learning H i d d e n L a y e r H i d d e n L a y e r F e a t u r e s F e a t u r e s F e a tur e s Q n e t w o r k o f r o b o t r e i n f o r c e m e n t l e a r n i n g P r i v a t e n e t w o r k T h e s h a r e d n e t w o r k 1 G F e a t ur e s T h e s h a r e d n e t w o r k 2 G T h e s h a r e d n e t w o r k 1 G Fig. 5. A transfer learning method of LFRL process of the robot can roughly divided into two stages, the stage of av oiding obstacles and the stage of reaching the target. W ith the former transfer algorithm, it is possible to utilize the obstacle av oidance skills of the cloud model. In the latter transfer method, it is obvious that the e valuation of the directions by cloud model is valuable, which is useful features for na vigation. D. Explanation fr om human cognitive science The design of the LFRL is inspired by the human decision- making process in cognitive science. For example, when play- ing chess, the chess player will make decisions based on the rules and his own experiences. The chess experiences include his own e xperiences and the experiences of other chess players he has seen. W e can regard the chess player as a decision model. The quality of the decision model represents the performance lev el of the chess player . In general, this policy model will become increasingly excellent through experience accumulation, and the chess player’ s skill will be improv ed. This is the iterati vely e volutionary process in LFRL. After each chess player finishing playing chess, his chess le vel or policy model e volves, which is analogous to the process of knowledge fusion in LFRL. And these experiences will also be used in later chess player , which is analogous to the process of transfer learning in LFRL. Fig. 1 demonstrates a concrete example. The person on the right is considering where should the next step goes. The chess he has played and the chess he has seen are the most two influential factors on making decision. But his chess experiences may influence the next step dif ferently . At this time, according to human cognitive science, the man will be more influenced by e xperiences with clear judgments. An experience with a clear judgment will hav e a higher weight in decision making. This procedure of humans makes decisions is analogous to kno wledge fusion algorithm in LFRL. The influence of different chess experience is always dynamic in the decision of each step. The knowledge fusion algorithm in LFRL achie ves this cogniti ve phenomenon by adaptiv ely weighting the labels of training data. The chess player is a decision model that incorporates his own experiences. Corre- sponding to this opinion, LFRL integrates experience into one decision model by generating a network. This process is also analogous to the operation of human cognitiv e science. I V . E X P E R I M E N T S In this section, we intend to answer three questions: 1) Can LFRL help reduce training time without sacrifice accurac y of navigation in cloud robotic systems? 2) Does the kno wledge fusion algorithm is effecti ve to increase the shared model? 3) Are transfer learning approaches effecti ve to transfer the shared model to specific task? T o answer the former question, we conduct experiments to compare the performance of the generic approach and LFRL. T o answer the second ques- tion, we conduct experiments to compare the performance of generic models and the shared model in transfer reinforcement learning. T o answer the third question, we conduct e xperiments to compare the performance of the two transfer learning approaches and the nati ve reinforcement learning. A. Experimental setup The training procedure of the LFRL was implemented in virtual en vironment simulated by gazebo. Four training en vironments were constructed to show the different conse- quence between the generic approach training from scratch and LFRL, as shown in Fig.6. There is no obstacle in En v- 1 e xcept the walls. There are four static c ylindrical obstacles in En v-2, four moving cylindrical obstacles in En v-3. More complex static obstacles are in Env-4. In e very en vironment, a T urtlebot3 equipped with a laser range sensor is used as the robot platform. The scanning range is from 0.13m to 4m. The target is represented by a red square object. During the training process, the starting pose of the robot is the geometric center of the ground in the training en vironment. The target is randomly generated in pose where there are no obstacles in the en vironment. An episode is terminated after the agent either reaches the goal, collides with an obstacle, or after a maximum of 6000 steps during training and 1000 for testing. W e calculated the average reward of the robot ev ery two minutes. W e end the training when the average rew ard of the (a) En v-1 (b) En v-2 (c) En v-3 (d) En v-4 -600 -100 400 900 1400 1900 2400 2900 3400 3900 0 50 100 (e) En v-1 score - 100 0 0 1000 2000 3000 4000 5000 6000 7000 8000 0 20 40 60 80 (f) En v-2 score - 600 - 100 400 900 1400 1900 2400 2900 0 20 40 60 80 100 (g) En v-3 score - 160 0 - 600 400 1400 2400 3400 4400 5400 6400 0 20 40 60 80 (h) En v-4 score Fig. 6. W e present both quantitative and compared results: Subfigure a to Subfigure d are the training environments. Subfigure e to h present scores of the generic approach (blue) compared with LFRL approach (red) in training process.In the training procedure of Env-1, LFRL has the same result with generic approaches. Because there is no antecedent shared models for the robot. In the training procedure of Env-2, LFRL obtained the shared model 1G, which made LFRL get higher reward in less time compared with the generic approach. In Env-3 and En v-4, LFRL evolv e the shared model to 2G and 3G and obtained excellent result. From this figure, we demonstrate that LFRL can get higher reward in less time compared with the generic approach. agent is enough and stable. W e trained the model from scratch on a single Nvidia GeF orce GTX 1070 GPU. The actor-critic network used two fully connected layers with 64 units. The output is used to produce the discrete action probabilities by a linear layer followed by a softmax, and the value function by a linear layer . B. Evaluation for the arc hitectur e T o show the performance of LFRL, we tested it and com- pared with generic methods in the four environments. Then we started the training procedure of LFRL. As mentioned before, we initialized the shared model and e volved it as Algorithm 2 after training in En v-1. In the cloud robotic system, the robot downloaded the shared model 1G. Then, the robot performed reinforcement learning based on the shared model. The robot got a priv ate model after training and it would be uploaded to the cloud server . The cloud server fused the pri vate model and the shared model 1G to obstain the shared model 2G. With the same mode, follow-up evolutions would be performed. W e constructed four environments, so the shared model upgraded to 4G. Performance of LFRL shown in Fig.6 where also shows generic methods performance. In En v2-En v4, LFRL increased accuracy of na vigating decision and reduced training time in the cloud robotic system. From the last row of Fig.6, we can observ e that the impro vement are more efficient with the shared model. LFRL is highly ef fectiv e for learning a policy ov er all considered obstacles. It improves the generalization capability of our trained model across commonly encountered en vironments. Experiments demonstrate that LFRL is capable of reducing training time without sacrificing accuracy of navigating decision in cloud robotic systems. C. Evaluation for the knowledge fusion algorithm In order to verify the effecti veness of the knowledge fu- sion algorithm, we conducted a comparativ e experiment. W e created three ne w en vironments that were not present in the previous experiments. These en vironments are more similar to real situations: Static obstacles such as cardboard boxes, dustbin, cans are in the T est-En v-1. Moving obstacles such as stakes are in T est-En v-2. T est-Env-3 includes more complex static obstacles and moving cylindrical obstacles. W e still used the T urtlebot3 created by gazebo as the testing platform. In order to vertify the adv ancement of the shared model, we trained the navigation policy based on the generic model 1, model 2, model 3, model 4 in T est-En v-1, T est-Env-2 and T est-En v-3 respectively . The generic models are from the previous generic approaches experiments. These policy models are trained from one en vironment without knowledge fusion. According to the hyper-parameters and complexity of en vironments, the average score goal (5 consecutiv e times abov e a certain score) in T est-En v-1 is 4000, T est-En v-2 is 3000, T est-En v-3 is 2600. In the follo wing, we present compared results in Fig.7 and quantitativ e results in T able 1. The shared model steadily reduces training time. In particular , we can observe that the generic method models are only able to make excellent decisions in indi vidual en vironments; while the shared model is able to make excellent decisions in plenty of different en vironments. So, the proposed knowledge fusion algorithm in this paper is effecti ve. (a) En v-1 (b) En v-2 (c) En v-3 0 5 0 0 0 1 0 0 0 0 1 5 0 0 0 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 M o d e l 1 M o d e l 2 M o d e l 3 M o d e l 4 Sha r ed m o d e l (d) En v-1 stacked scores - 1500 500 2500 4500 6500 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 Mode l 1 Mode l 2 Mode l 3 Mode l 4 Shar e d m odel (e) En v-2 stacked scores - 6 0 0 0 - 1 0 0 0 4 0 0 0 9 0 0 0 1 4 0 0 0 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 M o d e l 1 M o d e l 2 M o d e l 3 M o d e l 4 Sh a r ed m o d e l (f) En v-3 stacked scores (sampling) Fig. 7. W e present both quantitative and compared results: Subfigure a to Subfigure c are the testing en vironments. Because of the large amount of data, we present the stacked figure to better repersent the comparison. From the subfigure d to subfigure f, it can seen that the reward of the shared model accounts for a larger proportion in all positive rewards (greater than 0) models in the later stage of training. T ABLE I R E SU LT S O F T H E C O NT R A ST E XP E R I ME N T T ime to meet requirement A verange scores A verange of the last five scores T est-Env-1 T est-Env-2 T est-Env-3 T est-Env-1 T est-Env-2 T est-En v-3 T est-Env-1 T est-Env-2 T est-Env-3 model 1 1h 32min > 3h > 6 h 1353.36 46.5 -953.56 1421.54 314.948 -914.16 model 2 33min > 3h > 6 h 2631.57 71.91 288.61 3516.34 794.02 -132.07 model 3 37min > 3h 5h 50min 2925.53 166.5 318.04 3097.64 -244.17 1919.12 model 4 4h 41min 2h 30min 5h 38min 1989.51 1557.24 1477.5 2483.18 2471.07 3087.83 Shared model 55min 2h 18min 4h 48min 2725.16 1327.76 1625.61 3497.66 2617.02 3670.92 The background color of the cell reflects the performance of the corresponding model. The darker the color, the better the performance. D. Evaluation for the two transfer learning appr oaches In order to verify and compare the two transfer learning approaches, we conducted a comparati ve e xperiment. The result is present in Fig.8. It can be seen from the figure that both transfer learning approaches can effecti vely improve the efficienc y of reinforcement learning. Among them, the approach of parameter transferring has faster learning speed and the approach of feature e xtractor has higher stability . Bl u e ha s a be t t e r b e gi nni n g Re d h a s be t t e r s t a bi l i t y Fig. 8. T ransfer learning approaches comparison E. Real world e xperiments Fig. 9. T rajectory tracking in the real environment W e also conducted real-world experiments to test the per- formance of our approach with different sensor noise. W e use Turtlebot 3 platform, which is shown in Fig.9. The shared model 4G in the cloud was downloaded. Then we performed transferring reinforcement learning in En v-4 and got the policy finally . The T urtlebot navigates automatically in an indoor office en vironment as shown in Fig.9 under the policy . The experiment indicates that the policy is reliable in real environment. The reference [10] also corroborates the conclusion. V . C O N C L U S I O N W e presented a learning architecture LFRL for navig ation in cloud robotic systems. The architecture is able to make navigation-learning robots effecti vely use prior knowledge and quickly adapt to ne w en vironment. Additionally , we pre- sented a knowle ged fusion algorithm in LFRL and introduced transfer methods. Our approach is able to fuse models and asynchronously e volve the shared model. W e validated our architecture and algorithmes in policy-learning experiments and realsed a website to pro vide the service. The architecture has fixed requirements for the dimensions of input sensor signal and the dimensions of action. W e leav e it as future work to make LFRL flexible to deal with different input and output dimensions. The more flexible LFRL will offer a wider range of services in cloud robotic systems. V I . A C K N OW L E D G E M E N T This work was supported by National Natural Science Foundation of China No. 61603376; Guangdong-Hongkong Joint Scheme (Y86400); Shenzhen Science, T echnology and Innov ation Commission (SZSTI) Y79804101S awarded to Dr . Lujia W ang. The work also inspired and supported by Chengzhong Xu from Uni versity of Macau. R E F E R E N C E S [1] Y . Li, Deep Reinforcement Learning, arXiv preprint 2018. [2] B. Kehoe, S. Patil, P . Abbeel, and K. Goldberg, A Survey of Research on Cloud Robotics and Automation, IEEE Transactions on Automation Science and Engineering, vol. 12, no. 2, pp. 398-409, 2015. [3] V . Mnih et al., Asynchronous methods for deep reinforcement learning, in International conference on machine learning (ICML), 2016, pp. 1928-1937. [4] M. Jaderberg et al., Reinforcement learning with unsupervised auxiliary tasks, in International Conference on Learning Representations (ICLR), 2017. [5] Y . Zhu et al., T arget-driven visual na vigation in indoor scenes using deep reinforcement learning, in IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 3357-3364. [6] J. Zhang, J. T . Springenberg, J. Boedecker , and W . Burgard, Deep reinforcement learning with successor features for navigation across similar environments, in IEEE International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 2371-2378. [7] P . Mirowski et al., Learning to Navigate in Complex Environments, in International Conference on Learning Representations (ICLR), 2017. [8] J. Zhang, L. T ai, J. Boedecker , W . Burg ard, and M. Liu, Neural SLAM: Learning to Explore with External Memory , arXiv preprint arXiv:1706.09520, 2017. [9] P . Long, T . Fanl, X. Liao, W . Liu, H. Zhang, and J. Pan, T owards optimally decentralized multi-robot collision a voidance via deep rein- forcement learning, in IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 6252-6259. [10] L. T ai, G. Paolo, and M. Liu, V irtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless na vigation, in IEEE International Conference on Intelligent Robots and Systems (IR OS), 2017, pp. 31-36. [11] T . Schaul, D. Horgan, K. Gregor, and D. Silver , Universal V alue Func- tion Approximators, in International Conference on Machine Learning (ICML), 2015, pp. 1312-1320. [12] V . Mnih et al., Human-level control through deep reinforcement learning, Nature, vol. 518, no. 7540, pp. 529-533, 2015. [13] B. Kiumarsi, K. G. V amvoudakis, H. Modares, and F . L. Lewis, Optimal and Autonomous Control Using Reinforcement Learning: A Survey , IEEE T ransactions on Neural Networks and Learning Systems, vol. 29, no. 6, pp. 2042-2062, 2018. [14] H. Xu, Y . Gao, F . Y u, and T . Darrell, End-to-end learning of driving models from large-scale video datasets, in IEEE Conference on Com- puter V ision and Pattern Recognition (CVPR), 2017, pp. 2174-2182. [15] Y . Tsurumine, Y . Cui, E. Uchibe, and T . Matsubara, Deep reinforce- ment learning with smooth policy update: Application to robotic cloth manipulation, Robotics and Autonomous Systems, vol. 112, pp. 72-83, 2019. [16] Z. Chen, B. Liu, R. Brachman, P . Stone, and F . Rossi, Lifelong Machine Learning: Second Edition, 2nd ed. Morgan and Claypool, 2018. [17] A. A. Rusu et al., Policy Distillation, in International Conference on Learning Representations (ICLR), 2016. [18] H. B. Ammar , E. Eaton, P . Ruvolo, and M. E. T aylor, Online Multi-T ask Learning for Policy Gradient Methods, in International Conference on Machine Learning (ICML), 2014, pp. 1206-1214. [19] A. A. Rusu et al., Progressiv e Neural Networks, in Conference and W orkshop on Neural Information Processing Systems (NIPS), 2016. [20] E. Brunskill and L. Li, P AC-inspired Option Discovery in Lifelong Reinforcement Learning, International Conference on Machine Learning (ICML), pp. 316-324, 2014. [21] C. T essler, S. Givon y , T . Zahavy , D. J. Mankowitz, and S. Mannor, A Deep Hierarchical Approach to Lifelong Learning in Minecraft., in AAAI, 2017, vol. 3, pp. 1553-1561. [22] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, Federated Learning of Deep Networks using Model A veraging, arXiv preprint arXiv:1602.05629, 2016. [23] M. Nasr , R. Shokri, and A. Houmansadr, Comprehensiv e Priv acy Analysis of Deep Learning: Stand-alone and Federated Learning under Passi ve and Activ e White-box Inference Attacks, in IEEE Symposium on Security and Priv acy , 2018, pp. 1-15. [24] A. Hard et al., Federated Learning for Mobile Ke yboard Prediction, arXiv preprint arXiv:1811.03604, 2018. [25] X. W ang, Y . Han, C. W ang, Q. Zhao, X. Chen, and M. Chen, In-Edge AI: Intelligentizing Mobile Edge Computing, Caching and Communication by Federated Learning, arXiv preprint arXiv:1809.07857, 2018. [26] S. Samarakoon, M. Bennis, W . Saad, and M. Debbah, Distributed Federated Learning for Ultra-Reliable Low-Latency V ehicular Commu- nications, arXiv preprint arXiv:1807.08127, 2018. [27] J.Kuf fner , Cloud-enabled Robots, in International Conference on Hu- manoid Robot, 2010. [28] M. W aibel et al., RoboEarth - A W orld Wide W eb for Robots, IEEE Robotics and Automation Magazine, vol. 18, no. 2, pp. 69-82, 2011. [29] M. Srinivasan, K. Sarukesi, N. Ravi, and M. T , Design and Implementa- tion of V OD (V ideo on Demand) SaaS Framework for Android Platform on Cloud En vironment, in IEEE International Conference on Mobile Data Management, 2013, pp. 171-176. [30] W ang L , Liu M , Meng Q H. Real-Time Multisensor Data Retriev al for Cloud Robotic Systems, IEEE Transactions on Automation Science and Engineering, 2015, V ol. 12, no. 2, pp. 507-518.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment