Energy-Efficient Thermal Comfort Control in Smart Buildings via Deep Reinforcement Learning
Heating, Ventilation, and Air Conditioning (HVAC) is extremely energy-consuming, accounting for 40% of total building energy consumption. Therefore, it is crucial to design some energy-efficient building thermal control policies which can reduce the …
Authors: Guanyu Gao, Jie Li, Yonggang Wen
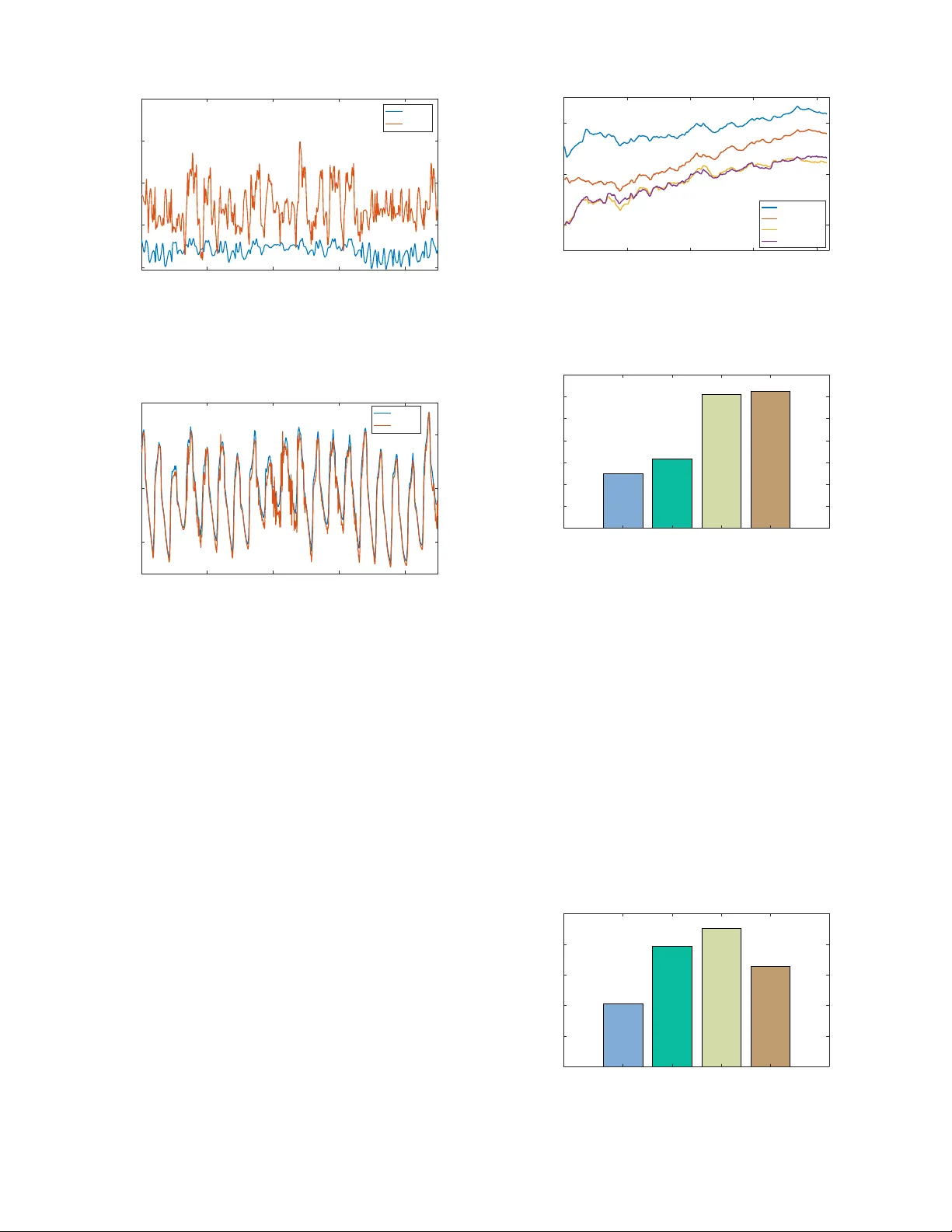
1 Ener gy-Ef ficient Thermal Comfort Control in Smart Buildings via Deep Reinforcement Learning Guanyu Gao, Jie Li, Y onggang W en Abstract —Heating, V entilation, and Air Conditioning (HV A C) is extremely ener gy-consuming, accounting for 40% of total building energy consumption. Theref ore, it is crucial to design some energy-efficient b uilding thermal control policies which can reduce the energy consumption of HV A C while maintaining the comfort of the occupants. Ho wever , implementing such a policy is challenging, because it inv olves various influencing factors in a building envir onment, which are usually hard to model and may be different from case to case. T o address this challenge, we propose a deep reinf orcement lear ning based framework for energy optimization and thermal comfort control in smart buildings. W e formulate the building thermal control as a cost-minimization problem which jointly considers the energy consumption of HV A C and the thermal comfort of the occupants. T o solv e the problem, we first adopt a deep neural network based approach for predicting the occupants’ thermal comfort, and then adopt Deep Deterministic Policy Gradients (DDPG) for learning the thermal control policy . T o evaluate the performance, we implement a building thermal control simulation system and evaluate the performance under various settings. The experiment results show that our method can impr ove the thermal comf ort prediction accuracy , and reduce the energy consumption of HV A C while impro ving the occupants’ thermal comfort. Index T erms —Building thermal control, energy management, thermal comfort, deep reinfor cement learning, smart b uilding. I . I N T R O D U C T I O N Building thermal control is important for providing high- quality working and living en vironments, because occupants can only feel comfortable when the temperature and humidity of the indoor thermal condition are within the thermal comfort zone. Howe ver , the ambient thermal condition may change dramatically , which will lead to the fluctuation of indoor thermal condition and the discomfort of the occupants. There- fore, b uilding thermal control is necessary for maintaining acceptable indoor thermal condition. Heating, V entilation and Air Conditioning (HV A C) systems are usually adopted for controlling indoor thermal conditions. One main concern of the HV AC systems is their high energy consumption, which makes building energy consumption accounts for 20%-40% of the total energy consumption [1]. On the other hand, occupants may feel cold or hot if the set-points of the HV A C systems are inappropriate, although more energy may be consumed. Thus, it is necessary to study how to reduce the ener gy consump- tion of the HV AC systems while keeping occupants comfort, especially due to the high electricity price and the increase of electricity consumption and en vironmental pollution. G.Y . Gao, J. Li and Y .G. W en are with the School of Computer Science and Engineering, Nanyang T echnological University , Singapore, 639798. E-mail: { ggao001, lijie, ygwen } @ntu.edu.sg. V arious factors hav e influences on b uilding thermal control. These factors can be categorized into three parts, namely , HV A C system related factors, building thermal en vironment related factors, and human related factors. The HV AC system can control the building thermal condition by adjusting the set-points of air temperature and humidity , which will also change the energy consumption of the HV AC system. Building thermal environments are determined by the structures of buildings, the indoor and outdoor thermal conditions, and the heat sources (e.g., bulbs, computers, etc). These factors affect the dynamic changes of b uilding thermal conditions. The feelings of the occupants under gi ven thermal conditions are subjectiv e and may be different from person to person [2], howe ver , the de grees of occupants’ satisfaction under gi ven thermal conditions need to be precisely estimated to select the appropriate set-points of the HV A C system for efficient thermal control. The factors of these three parts are correlated, and we need to consider these factors altogether for achie ving thermal comfort and reducing energy consumption. Many approaches hav e been proposed for building ther- mal control and ener gy optimization [3]. The model-based approaches aimed to model the thermal dynamics with sim- plified mathematical models, such as Proportional Integrate Deriv ati ve (PID) [4], [5], Model Predictive Control (MPC) [6], [7], Fuzzy Control [6], [7], Linear-Quadratic Regulator [8]. Howe ver , the complexity of the thermal dynamics and the various influencing factors are hard to be precisely modelled by these methods. These methods also require customized design for the control policy for specified en vironments. Another line of works adopted the learning-based approach for learning the optimal control policy , such as the reinforce- ment learning approach. The reinforcement learning approach can lean the optimal control policy by interactions with the thermal en vironment. Ho wev er, the plain reinforcement learning approaches (e.g., [9], [10], [11], [12], [13], [14]) cannot achiev e high performance if the state-action space is large. Deep reinforcement learning approaches (e.g., [15], [16]) hav e been recently adopted to address this limitation by using deep learning for representation of the large state-action space. Howe ver , the methods adopted in [15], [16] require discretization of the state-action space, which will also limit the performance of the thermal control policy . Different from previous works, we propose a learning-based framew ork for joint ener gy optimization and thermal comfort control in smart buildings. W e first design a deep neural network method with Bayesian regularization for predicting the occupants’ thermal comfort by considering dif ferent influ- encing factors. The method can predict the occupants’ thermal 2 comfort precisely , therefore, the thermal comfort prediction results can be used as a feedback for thermal control. Then, we adopt deep reinforcement learning approach for thermal control to minimize the o verall cost by jointly considering energy consumption of the HV A C system and the thermal comfort of the occupants. W e adopt Deep Deterministic Policy Gradients (DDPG) approach [17], which is a reinforcement learning algorithm for continuous control problem, for learning the optimal control policy . This is because in thermal control, temperature, humidity , and some other control variables are all continuous, therefore, DDPG is very suitable for addressing the problem in this scenario. Compared with the methods adopted in [15], [16], DDPG can a void the discretization of the control variables (e.g., temperature, humidity), which can also improv e the control precision. T o e valuate the performance of our method, we implement a thermal control simulation system with TRNSYS and e valuate the performance under various settings. The main contrib utions of this paper are as follo ws: • W e propose a DDPG approach for learning the control policy for energy optimization and thermal comfort con- trol. Our method can impro ve the occupants’ thermal comfort and reduce the energy consumption of HV A C. • W e design a deep neural network method with Bayesian regularization for predicting thermal comfort. Our method can predict thermal comfort more accurately . • W e implement a building thermal control simulation sys- tem with TRNSYS, and conduct e xtensive experiments for ev aluating the performances of our proposed method under dif ferent e xperiment settings. The rest of this paper are or ganized as follo ws. Section II presents the background and related works. Section III introduces the system design of the thermal control system in smart buildings. Section IV presents the system model and problem formulation. Section V presents the deep neural network based method for predicting thermal comfort and the DDPG method for learning the control policy . Section VI ev aluates the performance of our method and compare it with the baseline methods. Section VII concludes this paper . I I . B AC K G RO U N D A N D R E L A T E D W O R K In this section, we first introduce the background and then discuss the related works on b uilding thermal control. A. Backgr ound 1) HV A C: The HV A C system [18] is used to provide thermal comfort and maintain indoor air quality in buildings. The main functionalities of the HV A C system are heating, ventilation, and air conditioning. Specifically , heating is to generate heat to raise the air temperature in the building. V entilation is to exchange air with the outside and circulate the air within the building. Air conditioning provides cooling and humidity control. In this work, we mainly study the set- points and the energy consumption of the HV A C system, and we do not consider the inside mechanisms of the HV AC system (i.e., ho w the set-points are achiev ed by the HV A C system via its inside functioning), because different HV A C system may ha ve different inside mechanisms. W e design the algorithm independent of the inside mechanisms so that it can be generally applied in different types of HV A C systems. 2) Thermal Comfort: Thermal comfort reflects the occu- pants’ satisf action with the thermal condition [19]. For quan- titativ ely ev aluating thermal comfort, thermal comfort models are introduced for predicting the occupants’ satisfaction under giv en thermal conditions. Because the occupants’ feelings under giv en thermal conditions are subjective, thermal comfort is assessed by subjectiv e e valuation. Many subjects will be in vited to ev aluate their degrees of satisfaction under different thermal conditions, such as cold (-2), cool (-1), neutral (0), warm (1), and hot (2). Then, some mathematical or heuristic methods can be adopted for fitting the data. Many models hav e been de veloped for ev aluating the thermal comfort of the occupants under different thermal conditions [20], for instance, Predicted Mean V ote (PMV), Actual Mean V ote (AMV), Predicted Percentage Dissatisfied (PPD), etc. 3) Reinforcement Learning: Reinforcement learning is con- cerned with how the agent should take actions in a dynamic en vironment to maximize its overall rew ards [21]. It can learn the optimal control polic y by trails during the interactions with the environment. The reinforcement learning process can be modelled as a Marko v Decision Process (MDP), which consists of State, Action, and Rewards, etc. The agent first observes the current state of the en vironment and select an ac- tion to take according to a certain policy , follo wed by obtaining the re wards for the action taken on the observed state. These steps will be iterated during the learning stage and the control policy will be updated until it is conv erged. The optimal policy can be learned during the trails without directly modeling the system dynamics, therefore, reinforcement learning is a natural solution if the policy can be learnt by the interactions with the en vironment and the dynamics of the system is hard to model precisely . Deep reinforcement learning [22] is a combination of deep learning and reinforcement learning. It can significantly improve the performance compared with reinforcement learning if the dimensions of state and action is large, because deep learning has higher capacity for learning the representation of lar ge space and tremendous data. B. Related W ork The existing mathematical approaches for building ther- mal control can be generally classified into two cate- gories, namely , model-based approaches and learning-based approaches. Specifically , the model-based approaches derive the policy by modeling the dynamics of the en vironment; the learning-based approaches deriv e the policy by learning from the interactions with the environment. 1) Model-based Appr oaches: Levermore et al. [4] and Dou- nis et al. [5] used the Proportional Integrate Deri vati ve (PID) method for building ener gy management and indoor air quality control. Shepherd et al. [6] and Calvino [7] proposed a fuzzy control method for managing building thermal conditions and energy cost. K ummert et al. [23] and W ang et al. [24] proposed the optimal control method for controlling the HV A C system. Ma et al. [25] introduced a Model Predictiv e Control (MPC) based approach for controlling building cooling systems by 3 considering thermal energy storage. W ei et al. [26] adopted the MPC based approach for jointly scheduling HV AC, elec- tric vehicle and battery usage for reducing b uilding energy consumption while k eeping temperature within comfort zone. Maasoumy et al. [8] proposed a tracking linear-quadratic regulator for balancing human comfort and energy consump- tion in buildings. Oldewurtel et al. [27] proposed a bilinear model under stochastic uncertainty for b uilding climate control while considering weather predictions. These model-based approaches strive to model the dynamics of the thermal envi- ronment with some simplified mathematical models. Howe ver , the thermal en vironment is af fected by various factors and is complicated in nature, and it is hard to be precisely modeled. Moreov er , the performances of the model-based approaches are constrained by the specified building en vironments, and it is hard to deri ve a generalized model-based approach that can be applicable in v arious b uilding en vironments. 2) Learning-based Appr oaches: Barrett et al. [9], Li et al. [10] and Nikovski et al. [11] adopted Q learning based approaches for the HV A C control. Zenger et al. [12] adopted State-Action-Rew ard-State-Action (SARSA) for achieving the desired temperature while reducing energy consumption. Fazenda et al. [13] proposed a neural fitted reinforcement learning approach for learning ho w to schedule thermostat temperature set-points. Dalamagkidis et al. [14] designed the Linear Reinforcement Learning Controller (LRLC) using linear function approximation of the state-action v alue function to achiev e thermal comfort with minimal ener gy consump- tion. Anderson [28] proposed a robust control frame work for combined Proportional Integral (PI) control and reinforcement learning control for HV AC of buildings. W ei et al. [15] adopted a neural network based deep Q learning method for the HV A C control. W ang et al. [16] adopted a Long-Short T erm Memory (LSTM) recurrent neural network based rein- forcement learning controller for controlling air conditioning system. The tabular Q learning approach, SARSA, and other plain reinforcement learning approaches adopted in [9], [10], [11], [12], [13], [14], [28] are not suitable for problems with large state-action spaces, partly due to that plain reinforcement learning approaches fail to achiev e satisfying generalization of the value function and policy function in large spaces. Deep Q learning [15] and LSTM based reinforcement learning [16] can improve the performances with neural networks, which hav e better generalization capacity . Howe ver , the proposed approaches in these works require discretization of the state- action space, which will decrease the control precision and the performance. T o address these drawbacks in previous works, we propose the DDPG approach for continuous control with deep reinforcement learning in the HV A C system. Our method also provides the capacity for customizing the thermal comfort settings by jointly considering energy consumption and thermal comfort. One can customize the thermal comfort threshold according to the occupants’ thermal requirements for reducing the energy consumption of the HV A C system. I I I . S Y S T E M D E S I G N A N D C O N T RO L F L OW In this section, we present the system design and the workflo w for thermal control in smart b uildings. Con t rol le r Set - Points Tem perat ure Hum i di t y Indoor and Outdoor Sensors Thermal State Building Environment Fig. 1. The system design of the thermal control system. The controller obtains the building thermal state information from the sensors and make control actions by adjusting the set-points of the HV AC system. A. System Design The design of the thermal control system is illustrated in Fig. 1. The system consists of the following components, namely , the sensors, the controller , and the HV A C system. The functionalities of each component are detailed as follows. Sensors: The sensors periodically measure the thermal con- ditions of the indoor and outdoor building en vironments [29], including temperature, humidity , etc. The sensors are con- nected with the controller via Internet of things (IoT) networks [30], and the sensors will send the collected information to the controller for making thermal control decisions. Contr oller: The controller collects the thermal state infor- mation of the indoor and outdoor building en vironment and the energy consumption and the working state information of the HV A C system [29]. Based on these information, the controller will tak e control actions by updating the set-points of the HV A C system periodically according to the control policy . HV AC: The HV AC system will function according to the set-points of the controller . For instance, if the set-point of the temperature is lower than the current indoor temperature, the HV A C system will start cooling until the indoor temperature matches with the set-point temperature. If the set-point temper- ature is higher than the current indoor temperature, the HV AC system will start heating until achieving the specified indoor temperature. The HV A C system may also need to constantly keep heating, cooling, or ventilation for keeping the specified indoor thermal condition due to the influence of the outside building thermal en vironment. B. Contr ol Flow W e illustrate the control flow of the system in Fig. 2. W e adopt deep neural network for predicting the occupants’ thermal comfort value based on the current indoor thermal state, and we use deep reinforcement learning for making control decisions for thermal control. The neural network based thermal comfort predictor can be trained offline us- ing existing thermal prediction dataset. After training, the indoor b uilding thermal state information will be input into the trained thermal prediction model for predicting thermal 4 Action State Rew ard HVAC Syst em DRL Po wer Co nsump tio n Thermal Sta te Neur al Net w or k Tem pera tur e Hum idit y Thermal Comfort Fig. 2. The control flow of the building thermal control system. W e adopt deep neural network for thermal comfort prediction and Deep Reinforcement Learning (DRL) for thermal control. comfort value. The thermal comfort prediction value and the energy consumption information of the HV A C system will be used for calculating the re ward during each time slot. The deep reinforcement learning based thermal controller can learn the control policy by observing the received re wards for taking actions on different states. W e train the thermal controller using the b uilding thermal control simulation system, which will be detailed in Section VI-A. After training, the indoor and outdoor building thermal state will be input into the trained thermal control model for making thermal control actions. I V . P R O B L E M F O R M U L AT I O N In this section, we introduce the notations and formulate the energy optimization and thermal comfort control as a cost- minimization problem using MDP . W e adopt a discrete-time model and the time slot is denoted as t = 0 , 1 , 2 , ... . The duration of each time slot is from several minutes to one hour . The notations used in this paper are summarized in T able I. A. Building Thermal State The ener gy consumption of the HV AC system is affected by both of the indoor thermal en vironment and the outdoor thermal environment. For the indoor and outdoor thermal en vironments, we consider the factors of air temperature and humidity , which ha ve the greatest influences on the energy consumption of the HV A C system and the human thermal comfort. W e denote the indoor air temperature and humidity at time slot t as T in t and H in t , respectively; and we denoted the outdoor air temperature and humidity at time slot t as T out t and H out t , respecti vely . The indoor and outdoor air temperature and humidity can be obtained from the sensors in a smart building. B. Set-P oints of HV A C System The controller can change the set-point air temperature and humidity of the HV A C system for controlling the indoor thermal condition. W e denote the set-point air temperature of the HV AC system at time slot t as T set t , and denote the set- point air humidity as time slot t as H set t . At the beginning of each time slot, the controller updates the set-point air temperature and humidity of the HV A C system according to the indoor and outdoor thermal condition for controlling thermal comfort and ener gy consumption. T ABLE I K E Y N OTA T I O N A N D D E FIN I T I ON t the discrete time slot, t = 0 , 1 , 2 , ... T in t the indoor air temperature at time slot t H in t the indoor air humidity at time slot t T out t the outdoor air temperature at time slot t H out t the outdoor air humidity at time slot t T set t the set-point air temperature at time slot t H set t the set-point air humidity at time slot t M t predicted thermal comfort value at time slot t Φ thermal comfort prediction algorithm P t the energy consumption of the HV A C system at time slot t S t the state of the MDP at time slot t A t the action of the MDP at time slot t R t the reward of the MDP at time slot t π the thermal control policy γ the discount factor for the reward D the threshold for thermal comfort β the weight of the penalty for energy consumption α 1 , α 2 Bayesian hyperparameters n the number of training samples m the number of weights in the neural network w j the j -th weight in the neural network θ Q , θ µ the parameters of the critic network and the actor network N ( t ) the exploration noise for training τ the discount factor for model update C. Thermal Comfort Prediction Thermal comfort prediction predicts the occupants’ satisfac- tion with the thermal condition. Many factors may influence the occupants’ thermal comfort, e.g., metabolic rate, clothing insulation, air temperature and humidity , skin wetness, etc. For some of the factors, they may be dif ferent from person to person, or cannot be easily measured in real en vironments, such as the occupants’ metabolic rate and skin wetness. In this work, we mainly consider the indoor air temperature and humidity as variables for thermal comfort prediction, and the other factors are set as default v alues. The occupants’ thermal comfort v alue at time slot t is predicted as M t = Φ( T in t , H in t ) , (1) where M t is the predicted thermal comfort v alue and Φ is the thermal comfort prediction algorithm. In this work, we adopt the deep neural netw ork method for predicting thermal comfort v alue, which will be detailed in Section V -A. D. Energy Consumption of HV A C system The HV A C system will consume energy for heating, cool- ing, and dehumidification. The information of the energy consumption of the HV A C system during each time slot can be obtained from the smart meter . W e assume that the energy consumption information of the HV A C system during each time slot is kno wn, and we denote the energy consumption of the HV A C system at time slot t as P t . T o make the modeling independent of the inside mechanisms of the HV AC system, we only consider the overall energy consumption of the HV A C system during each time slot. The specified energy consumptions for heating, cooling, dehumidification, or other inside mechanisms are considered as unkno wn. 5 E. Pr oblem F ormulation W e formulate the energy optimization and thermal comfort control in the smart building as a MDP process for minimizing the ov erall cost over time, the details of which are as follows. State: The state of the MDP is the current indoor and outdoor thermal conditions at each time slot, represented as S t = ( T in t , H in t , T out t , H out t ) , (2) where S t is the state of the MDP at time slot t . Action: The action of the MDP is the set-point air temper- ature and humidity of the HV A C system, represented as A t = ( T set t , H set t ) , (3) where A t is the action of the MDP at time slot t . The action is determined according to the control policy by observing the current state. Mathematically , it can be represented as A t = π ( S t ) , (4) where π is the control polic y for thermal control. Reward: The reward of the MDP consists of two parts, namely , the penalty for the energy consumption of the HV AC system and the penalty for the occupants’ thermal discomfort. Specifically , the reward should be less, if more energy is consumed by the HV A C system or the occupants feel uncom- fortable about the building thermal condition. The predicted value of thermal comfort ( M t ) ranges from -3 to 3, where -3 is too cold and +3 is too hot and 0 is neutral. The occupants can feel comfort when the predicted thermal comfort v alue is within an acceptable range. W e denote the range as [ − D , D ] , where D is the threshold for thermal comfort value. If the predicted thermal comfort v alue lies within [ − D, D ] , it will not incur penalty because the occupants feel comfortable. Otherwise, it will incur penalty for the occupants’ dissatisfaction with the building thermal condition. By jointly considering the predicted thermal comfort value and the energy consumption of the HV A C system, we calculate the ov erall re ward of the MDP during a time slot as R t ( S t , A t ) = − β P t − 0 − D < M t < D ( M t − D ) M t > D ( − D − M t ) M t < − D , (5) where R t is the overall reward for time slot t and β is the weight of the energy consumption of the HV A C system. The weigh, β , reflects the relati ve importance of the energy consumption of the HV AC system compared to the occupants’ thermal comfort. If the occupants’ thermal comfort is more important, β should be set as a smaller v alue. Otherwise, β should be set as a larger value for achieving energy-ef ficiency . Cost Minimization: Our objective is to maximize the ov erall discount rew ards from the current time slot by deri ving the optimal thermal control policy for energy optimization and thermal comfort control, mathematically , the objectiv e is max π ∞ X t 0 =0 γ t 0 R t + t 0 ( S t + t 0 , A t + t 0 ) , (6) where γ is the discount factor . If the precise transitions of the system states are available, we can deriv e the optimal policy Tem per atur e In pu t La ye r Hi dde n Layer Ou tpu t Laye r Humid ity Rad ian t Tem per atur e Air Spe ed Metabolic Rate Clo th ing Insu lation Pred ic t ed Ther m al Comf ort Val ue Fig. 3. The structure of the deep neural netw ork for predicting thermal comfort. The inputs of the neural network include temperature, humidity , radiant temperature, air speed, metabolic Rate, and clothing insulation. The output of the neural network is the predicted thermal comfort value. offline. Howe ver , it is impossible to obtain the state transition probabilities in such a complex system, therefore, the optimal control policy cannot be deri ved directly . It moti v ates us to adopt the learning algorithm to learn the optimal polic y . V . L E A R N I N G A L G O R I T H M F O R T H E R M A L C O M F O RT P R E D I C T I O N A N D T H E R M A L C O N T R O L In this section, we first introduce the deep neural network based method for thermal comfort prediction. Then, we intro- duce the DDPG method for learning thermal control polic y . A. Deep Neural Network based Thermal Comfort Prediction W e adopt the feed-forward neural network for predicting thermal comfort. The structure of the neural network that we adopt for predicting thermal comfort is illustrated in Fig. 3. The inputs of the neural network include air temperature, humidity , mean radiant temperature, air speed, metabolic rate, clothing insulation, and all of these values are numerical. The hidden layer of the neural network has two layers, and the output layer has one neuron. The output of the neural network is the predicted thermal comfort value. The activ ation function of the hidden layer is sigmoid function, and the activ ation function of the output layer is a linear function. For training the neural network, some thermal comfort prediction datasets should be adopted as the training data. These datasets are labeled by the subjects for ev aluating their thermal comfort under different thermal conditions, and the labeled data can be noisy . T o interpolate the noisy data, we adopt Bayesian regularization [31] for avoiding overfit- ting. The cost function for training the neural network with Bayesian regularization is to minimize the training error using the minimal weights of the neural network, represented as C ost F unction = α 1 n X i =1 ( Y i − Y 0 i ) 2 + α 2 m X j =1 w 2 j , (7) where α 1 and α 2 are Bayesian hyperparameters for specifying the direction of the learning process to seek (i.e., minimize error or weights), n is the number of training samples, Y i is the i -th labeled v alue by the subject, Y 0 i is the predicted value by the neural network, m is the number of weights in the neural network, and w j is the j -th weight. The training algorithm is Lev enberg-Marquardt backpropagation [32]. 6 DQN Ther mal St ate DDPG Ther mal St ate … … Tem per atur e, Hum idity Tem per atur e Humid ity (25, 5 0%) (25, 6 0%) (26, 5 0%) (26, 6 0%) … 25.4 60.5% Fig. 4. A comparison of DQN and DDPG for thermal control. T emperature and humidity are continuous values, DDPG can be directly applied for continuous action control and DQN needs discretization of the action space. B. Learning Thermal Control P olicy with DDPG 1) Why DDPG?: The control v ariables of the HV A C system (i.e., air temperature and humidity) take continuous values. In Q learning and Deep Q learning, it can only handle problems with discrete and low-dimensional action spaces [17]. Therefore, DQN cannot be directly applied to the thermal control problem, because it needs to find the control action, which is continuous, for maximizing the action-value function. For applying DQN in thermal control, one obvious approach is to discretize the action space. Ho wev er , if one wants to achie ve finer grained dicretization, it may lead to an explosion of the number of actions. For instance, the range of humidity is from 0 to 100, if we discretize with the granularity of one, it will turn into 101 actions. Similarly , suppose that the range of the air temperature is from 15 to 35, and there will be 200 actions if the granularity is 0.1. If one output of DQN represents one possible combination of temperature v alue and humidity v alue, the DQN network will have 20,200 outputs. Therefore, it will lead to a large number of outputs of DQN , which may require more training data and decrease the performance. Compared with Q-Learning and DQN, DDPG is a natural solution for thermal control, because the action space of DDPG is continuous, and we can directly obtain the set- points of the HV A C system from the outputs of DDPG. W e illustrate the comparisons of DQN and DDPG in Fig. 4. With DDPG, the network only has two outputs, namely , the real- valued set-points of air temperature and humidity of the HV A C system. In contrast, DQN may require thousands of outputs, and each output is a possible combination of the set-points of the temperature and humidity of the HV A C system. 2) Learning Contr ol P olicy: DDPG adopts an actor-critic framew ork based on Deterministic Policy Gradient (DPG) [33]. W e illustrate the network architecture of DDPG in Fig. 5. The actor network is denoted as A t = µ ( S t | θ µ ) , where S t is the thermal state and θ µ represents the weights of the actor network and A t represents the control action. The actor network maps the thermal state to a specific control action (i.e., the set-points of the HV AC system). The critic network is denoted as Q ( S t , A t | θ Q ) , where A t is the specified control action by the actor network and θ Q represents the weights of the critic network. The action-v alue function, Q ( S t , A t | θ Q ) , describes the expected reward by taking action A t at state S t by follo wing the policy . The actor network and the critic network will be trained based on T emporal Dif ference (TD) 𝜃 " 𝜃 # 𝑄(𝑠 , 𝑎 ) S + 𝐴 + Actor Network Critic Network Thermal State Control Action Fig. 5. The network architecture of DDPG. The actor network specifies a control action gi ven the current thermal state and the critic network outputs an evaluation of the action generated by the actor network. error . The control action specified by the actor network will be used for selecting actions during the training. After training, only the actor network is required for making control actions. Algorithm 1 T raining Thermal Control Polic y with DDPG 1: Initialize critic network Q ( S t , A t | θ Q ) and actor network µ ( S t | θ µ ) with random weights θ Q and θ µ 2: Initialize target network Q 0 ( S t , A t | θ Q 0 ) and actor network µ 0 ( S t | θ µ 0 ) with θ Q 0 ← θ Q and θ µ 0 ← θ µ 3: Initialize replay buffer B 4: for episode = 0,1,...,M do 5: Obtain the initial thermal state S 0 6: for t = 0,1,...,T do 7: Obtain control action A t according to Eq. (8) 8: Update the set-points of the HV A C system according to the control action, A t 9: Obtain ne w thermal state S t +1 and calculate re ward R t according to Eq. (5) at the end of time slot t 10: Store ( S t , A t , R t , S t +1 ) into replay b uffer B 11: Randomly sample N transitions from replay buf fer B 12: Calculate the estimated reward for each sampled transition using Eq. (9) 13: Update the critic network by minimizing the MSE ov er the sampled minibatch and update the actor network using the sampled polic y gradient 14: Update tar get network Q 0 and µ 0 using Eq. (10) 15: end f or 16: end f or The training for the DDPG network is performed by in- teracting with the building thermal en vironment. The training procedure is illustrated in Algorithm 1. At the beginning of each time slot t , we first obtain the current indoor and outdoor thermal state S t , and input the thermal state into the policy network, which will output the control action. During the training, we need to e xplore the state space so that the polic y will not conv erge to local optimal solutions. Therefore, we add a random noise to the obtained control action for exploration, A t = µ ( S t | θ µ ) + N ( t ) , (8) where N ( t ) is the exploration noise and A t is the control action added with exploration noise. In our w ork, we use an Ornstein-Uhlenbeck process [34] for generating the noise, 7 TRN S YS PyT orch MyS QL Sensor Dat a & Set - Po int s Thermal State Thermal State Control Action Control Action Building HVAC Control Agent Fig. 6. The implementation of the thermal control simulation system. W e adopt TRNSYS for simulating the building thermal en vironment and the HV A C system, MySQL for storing sensor data and the set-points of the HV AC system, PyT orch for implementing the control agent. N ( t ) , for exploration. Then, the control action A t will be applied to the HV A C system. At the end of time slot t , we will obtain the new thermal state S t +1 and calculate the ov erall re- ward R t during the time slot. The transition ( S t , A t , R t , S t +1 ) will be stored in the replay b uffer B for training the policy network and the actor network. After that, we will randomly sample N transitions from the replay buf fer for training the network. For each transition ( S i , A i , R i , S i +1 ) ∈ N , the estimated re ward is calculated as follow , R 0 i = R i + γ Q 0 ( S i +1 , µ 0 ( S i +1 | θ µ 0 ) | θ Q 0 ) . (9) The critic network will be updated by minimizing the MSE between the estimated re ward ( R 0 i calculated from Eq. (9)) and the reward predicted by the critic network ( Q ( S i , A i ) ) ov er the sampled minibatch, and the actor network will be updated using the sampled policy gradient [17]. Then, the target networks will be updated using the following equations, θ Q 0 ← τ θ Q + (1 − τ ) θ Q 0 , θ µ 0 ← τ θ µ + (1 − τ ) θ µ 0 , (10) where τ is the discount factor for model update. After training, only the actor network is applied for making control action. The set-points of the HV A C system will be set as the control actions specified by the actor network. V I . P E R F O R M A N C E E V A L UAT I O N In this section, we first present the implementation of the thermal control simulation system, and then introduce the ex- periment settings and datasets, and compare the performances of our proposed methods with the baseline methods. A. Implementation of Thermal Contr ol Simulation System W e implement the thermal control simulation system for simulating the thermal dynamics in a building and the energy consumption of the equipped HV A C system. The main com- ponents of the thermal control simulation system is illustrated in Fig. 6. W e use TRNSYS [35] to simulate the HV AC system and the thermal dynamics in the b uilding. The thermal control algorithm and the thermal comfort prediction algorithm are implemented with PyT orch [36], which is an open-source machine learning library for Python. W e use MySQL database [37] as an interface for the control interactions between the thermal control agent and TRNSYS, because TRNSYS uses the Matlab-based programming interface for interacting with Fig. 7. The control diagram of building thermal simulation in TRNSYS. other programs. The control diagram of the thermal simulation in TRNSYS is illustrated in Fig. 7. At the beginning of each time slot, the thermal state of the building will be read from TRNSYS and written into MySQL. The control agent will read the thermal state information from MySQL and mak e a control action, which is the new set-points of the HV A C system. The control action will be written into MySQL, and TRNSYS will read the control action from MySQL and update the set-points of the HV A C system. TRNSYS will use the new set-points of the HV A C system and en vironment information (e.g., outside temperature, solar irradiation) to calculate the energy consumption of the HV A C system and the indoor temperature and humidity . The control agent can improve the control policy during the iterations. B. Experiment Settings W e simulate the building environment of a laboratory which is 307 M 2 . It has 30 occupants and 40 computers with monitors. The heat gain from the occupants and computers will also influence the thermal conditions in the en vironment. The air change rate is 0.67/hour . The weather dataset we use for our simulation is SG-Singapore-Airp-486980, which is collected from Singapore. W e use 10,000 hours of the simulation data in TRNSYS for training the models, and use 5,000 hours of data for testing the performances. In our implementation of DDPG, the actor network and the critic network have two hidden layers, and each layer has 128 neurons. W e use the tanh activ ation function and batch normalization in each layer . W e adopt Adam for gradient-based optimization and the learning rate is 0.001. The discount factor τ for model update is 0.001 and the batch size is 128. The duration of each time slot is 30 minutes and each episode consists of 48 time slots. The default weight of energy cost is 0.05. The initial exploration noise scale is 0.7 and the final noise scale is 0.1, and the exploration noise decreases linearly ov er 300 episodes to 0.1. C. Thermal Comfort Prediction P erformance W e adopt the ASHRAE RP-884 thermal comfort dataset [38] for training our deep neural network model for thermal comfort prediction. W e use 11164 samples from the dataset 8 0 50 100 150 200 250 300 350 Training Epoch 10 0 10 1 10 2 Prediction Error (MSE) Best Training Performance is 1.1668 at epoch 356 Train Test Best Fig. 8. The con vergence of the deep neural network method for thermal comfort prediction. The prediction error can conver ge after several epochs of training, and the best training performance is 1.1668. Fig. 9. The distribution of the prediction errors of the training and test samples. The prediction errors of most of the training samples and test samples are within the range [-1, 1]. for training and testing, and each sample is a human subject’ s ev aluation of the thermal comfort under a certain thermal condition. The samples are randomly di vided, and 80% of the samples are used for training and 20% of the samples are used for testing. W e compare the performance of our deep neural network based thermal prediction method with following baseline methods, namely , Linear Regression, Sup- port V ector Machine (SVM), Gaussian Process Re gression, Ensemble Regression. W e ev aluate the prediction errors of different methods using Mean Squared Error (MSE). W e first illustrate the prediction error of our method during different training epochs in Fig. 8. The training error can con ver ge after se veral epochs, and the best training perfor- mance is 1.1668 at epoch 356. The prediction error distribution of our method is illustrated in Fig. 9. From the test, we can observe that for most of the training samples and test samples, the prediction error is within the range [ − 1 , 1] . The performance comparison of different methods is illustrated in Fig. 10. The MSE of our method is 1.1583, and the MSEs of Linear Regression, Support V ector Machine (SVM), Gaussian Process Regression, Ensemble Regression are 1.3555, 1.4026, 2.1486, 1.4374, 1.8145, respectively . It can be observed that our method can achie ve smaller prediction error compared with the baseline methods. The results verify that our method can achie ve a higher prediction accuracy , therefore, it can be adopted for predicting the occupants’ thermal comfort more precisely compared with the other baseline methods. 1.1583 1.3555 1.4026 2.1486 1.4374 1.8145 Deep Neural Network Linear Regression SVM Regression Tree GPR Ensemble 0 0.5 1 1.5 2 2.5 Prediction Error (MSE) Fig. 10. The comparison of prediction errors of different methods. Our method can achieve smaller prediction error compared with the baseline methods. 0 100 200 300 400 Episode -250 -200 -150 Reward Average Reward Episode Reward Fig. 11. The conver gence of the DDPG based thermal control algorithm. The av erage reward improves during the training and con verges. D. P erformance under Differ ent Experiment Settings In this subsection, we ev aluate the performances of the DDPG based thermal control method under dif ferent settings. Con ver gence of the DDPG based thermal contr ol. W e illus- trate the rew ards of the DDPG based thermal control method during different training episodes in Fig. 11. The DDPG algorithm updates the policy during training, and we can observe that the received re ward during each episode improves ov er the training stage and finally conv erges. As illustrated in Fig. 11, the re ward received during each episode (Episode Rew ard) fluctuates during the training, this is because the exploration noise and the varying ambient thermal conditions in each episode affect the energy consumption and thermal comfort, leading to the fluctuant rew ards in each episode. The av erage re ward illustrated in Fig. 11 is the av eraged re ward of the past 100 episodes and reflects the changing trend of the rew ard. W e can observ e that the a verage re ward improves stably during the training and con ver ges. P erformance under differ ent thermal comfort thr esholds. W ith our method one can set different thermal comfort thresh- olds according to the occupants’ thermal comfort require- ments. W e e valuate the energy consumption of the HV A C system and the distribution of the thermal comfort values under different thermal comfort thresholds. In Fig. 12 we illustrate the a verage thermal comfort values under dif ferent prescribed thermal comfort thresholds, and it can be observed that the a verage actual thermal comfort value measured from 9 0.021881 0.2683 0.51287 0.77305 1.0272 1.2657 1.5374 0.0 0.25 0.5 0.75 1.0 1.25 1.5 Thermal Comfort Threshold 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 Average Thermal Comfort Value Fig. 12. The average thermal comfort v alues under dif ferent thermal comfort thresholds. The average thermal comfort values are close to the thresholds. 0 0.25 0.5 0.75 1 1.25 1.5 Thermal Comfort Threshold 0 200 400 600 800 1000 Number of Time Slots Fig. 13. The distribution of the thermal comfort v alues under different thermal comfort thresholds. The thermal comfort v alue of each time slot is closely centered around the prescribed thermal comfort threshold. the building is close to the prescribed thresholds. In Fig. 13 we illustrate the distribution of the thermal comfort value of each time slot under different prescribed thermal comfort thresholds. It can be verified that the thermal comfort values in the indoor en vironment are closely centered around the prescribed thresholds. Therefore, our method can control the indoor thermal comfort precisely , gi ven the occupants’ thermal comfort requirements and appropriate settings. In Fig. 14 we illustrate the average cooling load of the HV A C system under different thermal comfort thresholds. It will lead to less energy consumption of the HV A C system if the thermal comfort threshold is set to a larger value. Therefore, if the occupants do not hav e stringent thermal comfort requirement, the thermal comfort threshold can be set to a larger value for energy ef ficiency . W e illustrate the distribution of the cooling load of the HV A C system under dif ferent thermal comfort thresholds in Fig. 15. W e can observe that the distribution of the cooling load move towards small values when the thermal comfort threshold is lar ger . Therefore, adjusting the thermal comfort threshold can control the ener gy consumption of the HV A C system. P erformance under differ ent weights of energy cost. W e can set different weights for the cost of the energy consumption in the reward function (Eq. 5). If one puts more interests on the occupants’ thermal comfort, the weight can be set smaller . On the contrary , if one puts more interests on energy cost, the 60.3694 59.2669 58.185 56.9688 55.7862 54.6492 53.334 0.0 0.25 0.5 0.75 1.0 1.25 1.5 Thermal Comfort Threshold 50 52 54 56 58 60 62 Average Cooling Load (Kilowatt) Fig. 14. The a verage cooling load of the HV A C system under different thermal comfort thresholds. A larger thermal comfort threshold will result in less energy consumption of the HV AC system. 45 50 55 60 65 70 0 200 400 Threshold = 0.0 45 50 55 60 65 70 0 200 400 Threshold = 0.25 45 50 55 60 65 70 0 200 400 Threshold = 0.5 45 50 55 60 65 70 0 200 400 Number of Time Slots Threshold = 0.75 45 50 55 60 65 70 0 200 400 Threshold = 1.00 45 50 55 60 65 70 0 200 400 Threshold = 1.25 45 50 55 60 65 70 Cooling Load (Kilowatt) 0 200 400 Threshold = 1.5 Fig. 15. The distribution of the cooling load of the HV AC system under different thermal comfort thresholds. The distribution of cooling load moves to smaller values under a larger thermal comfort threshold. weight can be set larger . W e e valuate the performances of our method under dif ferent weights, and the results are sho wn in Fig. 16 and 17. In Fig. 16 we illustrate the changes of the thermal comfort value over time under different weights of energy cost. The thermal comfort threshold in the experiment is 0.0. W e can observe that if the weight is small, the thermal comfort value will be close to the threshold, and the changes of the thermal comfort value will be small. This is because the penalty for violating the thermal comfort threshold is lar ger than the energy cost, due to the smaller weight of the energy cost. Therefore, the thermal comfort v alue will be kept close to the threshold for reducing the cost incurred by violating the thermal comfort threshold. On the contrary , if the weight of the energy cost is large, the thermal comfort v alue may fluctuate largely for reducing the energy consumption. W e illustrate the cooling load of the HV A C system o ver time under dif ferent 10 200 400 600 800 Time Slot 0 0.05 0.1 0.15 0.2 Thermal Comfort Value 0.05 0.075 Fig. 16. The thermal comfort values under different weights of energy cost over time. If the weight of the energy cost is small, the thermal comfort value will be close to the threshold, and the changes of the value will be smaller . 200 400 600 800 Time Slot 55 60 65 Average Cooling Load (Kilowatt) 0.05 0.075 Fig. 17. The time-varying cooling load of the HV AC system under different weights of energy cost. It will incur less energy consumption if the weight of energy cost is set as a larger value. weights of ener gy cost in Fig. 17. It can be observed that it will incur less energy consumption if the weight of the energy cost is high. This is because it will incur more cost if the HV AC system keeps maintaining the thermal comfort v alue within the threshold, which will incur high energy consumption. E. P erformance Comparison with Differ ent Methods W e compare the performance of our thermal control method (DDPG) with the following baseline methods, namely , Q Learning, SARSA, and DQN. In the baseline methods, the temperature is discretized with the granularity of one centi- degree and the humidity is discretized with the granularity of 5 percentages. W e illustrate the conv ergences of different methods in Fig. 18. It can be observed that DDPG can achiev e a faster con vergence speed compared with the other baseline methods. This is because DDPG does not need the discretiza- tion of the action space and has fewer number of outputs of the network. Therefore, DDPG can learn for thermal control more efficiently . Moreover , DDPG can also achieve a higher rew ard compared with the baseline methods. This verifies that our method can achie ve higher performances compared with the baseline methods. This is because Q learning and SARSA adopt the tabular methods for storing and updating the state-action values without generalization, and DQN needs 0 100 200 300 400 Episode -180 -160 -140 Reward DDPG DQN Q Learning SARSA Fig. 18. The con vergence of different algorithms. DDPG can conver ge faster and achieve a higher rew ard than the other baseline methods. DDPG DQN Q Learning SARSA 55 56 57 58 59 60 61 62 Average Cooling Load (Kilowatt) Fig. 19. The average cooling load of different methods. DDPG can achiev e less energy consumption compared with the baseline methods. the discretization of the action space. W e illustrate the average cooling load of dif ferent methods in Fig. 19. It can be observ ed that the av erage cooling load of our method is lower than the other baseline methods, therefore, our method can achie ve higher energy-ef ficiency . W e illustrate the average thermal comfort values of different methods in Fig. 20. The a verage thermal comfort value of DDPG is more close to the preset threshold 0.5 and lo wer than the baseline methods. Therefore, our method can control the set-points of the HV A C system more precisely and it can achiev e a higher degree of thermal comfort compared with the other methods. DDPG DQN Q Learning SARSA 0.4 0.45 0.5 0.55 0.6 0.65 Thermal Comfort Value Fig. 20. The average thermal comfort values of different methods. DDPG can achiev e higher thermal comfort (i.e., smaller thermal comfort value) compared with baseline methods. 11 V I I . C O N C L U S I O N In this paper , we proposed a learning based optimization framew ork for optimizing the occupants’ thermal comfort and the energy consumption of the HV A C systems in smart build- ings. W e first designed a deep neural network based method with Bayesian regularization for thermal comfort prediction, and then we adopted DDPG for controlling the HV A C sys- tem for optimizing the energy consumption whiling meeting the occupants’ thermal comfort requirements. For verifying the ef fectiv eness of our proposed methods, we implement a building thermal control simulation system using TRNSYS. W e ev aluated the performances of our methods under different settings. The results sho w that our method can achie ve better prediction performances for thermal comfort prediction, and it can achie ve higher thermal comfort and ener gy-efficiency compared with the baseline methods. In future works, we may consider using transfer learning to improve learning efficienc y via the transfer of knowledge from dif ferent HV A C systems. R E F E R E N C E S [1] L. P ´ erez-Lombard, J. Ortiz, and C. Pout, “ A revie w on buildings energy consumption information, ” Ener gy and buildings , vol. 40, no. 3, pp. 394–398, 2008. [2] S. P . Corgnati, M. Filippi, and S. V iazzo, “Perception of the thermal en vironment in high school and university classrooms: Subjecti ve pref- erences and thermal comfort, ” Building and envir onment , vol. 42, no. 2, pp. 951–959, 2007. [3] A. I. Dounis and C. Caraiscos, “ Advanced control systems engineering for ener gy and comfort management in a building environmentA review , ” Renewable and Sustainable Ener gy Revie ws , vol. 13, no. 6-7, pp. 1246– 1261, 2009. [4] G. J. Levermore, Building energy management systems: An application to heating and contr ol . E & FN Spon, 1992. [5] A. I. Dounis, M. Bruant, M. Santamouris, G. Guarracino, and P . Michel, “Comparison of con ventional and fuzzy control of indoor air quality in buildings, ” J ournal of Intelligent & Fuzzy Systems , vol. 4, no. 2, pp. 131–140, 1996. [6] A. Shepherd and W . Batty , “Fuzzy control strategies to provide cost and energy efficient high quality indoor environments in buildings with high occupant densities, ” Building Services Engineering Resear ch and T echnology , vol. 24, no. 1, pp. 35–45, 2003. [7] F . Calvino, M. La Gennusa, G. Rizzo, and G. Scaccianoce, “The control of indoor thermal comfort conditions: Introducing a fuzzy adapti ve controller , ” Energy and buildings , vol. 36, no. 2, pp. 97–102, 2004. [8] M. Maasoumy , A. Pinto, and A. Sangiov anni-V incentelli, “Model-based hierarchical optimal control design for HV A C systems, ” in ASME 2011 Dynamic Systems and Contr ol Confer ence and Bath/ASME Symposium on Fluid P ower and Motion Contr ol . American Society of Mechanical Engineers, 2011, pp. 271–278. [9] E. Barrett and S. Linder , “ Autonomous HV A C control, a reinforcement learning approach, ” in Joint Eur opean Conference on Machine Learning and Knowledge Discovery in Databases . Springer , 2015, pp. 3–19. [10] B. Li and L. Xia, “ A multi-grid reinforcement learning method for energy conservation and comfort of HV AC in buildings, ” in Automation Science and Engineering (CASE), 2015 IEEE International Conference on . IEEE, 2015, pp. 444–449. [11] D. Niko vski, J. Xu, and M. Nonaka, “ A method for computing optimal set-point schedules for HV A C systems, ” in REHV A W orld Congr ess CLIMA ’13 , 2013. [12] A. Zenger , J. Schmidt, and M. Kr ¨ odel, “T owards the intelligent home: Using reinforcement-learning for optimal heating control, ” in Annual Confer ence on Artificial Intelligence . Springer, 2013, pp. 304–307. [13] P . Fazenda, K. V eeramachaneni, P . Lima, and U.-M. O’Reilly , “Using reinforcement learning to optimize occupant comfort and energy usage in HV AC systems, ” Journal of Ambient Intelligence and Smart En vir on- ments , vol. 6, no. 6, pp. 675–690, 2014. [14] K. Dalamagkidis, D. K olokotsa, K. Kalaitzakis, and G. S. Stavrakakis, “Reinforcement learning for energy conservation and comfort in build- ings, ” Building and en vir onment , vol. 42, no. 7, pp. 2686–2698, 2007. [15] T . W ei, Y . W ang, and Q. Zhu, “Deep reinforcement learning for building HV A C control, ” in Design Automation Confer ence (D AC), 2017 54th ACM/ED AC/IEEE . IEEE, 2017, pp. 1–6. [16] Y . W ang, K. V elswamy , and B. Huang, “ A long-short term memory recurrent neural network based reinforcement learning controller for office heating ventilation and air conditioning systems, ” Processes , vol. 5, no. 3, p. 46, 2017. [17] T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver , and D. Wierstra, “Continuous control with deep reinforcement learning, ” arXiv pr eprint arXiv:1509.02971 , 2015. [18] F . McQuiston and J. Park er, “Heating, ventilating, and air conditioning: analysis and design. ” [19] A. society of heating refrigerating and air conditioning engineers, ASHRAE STAND ARD: An American Standar d: Thermal Envir onmental Conditions for Human Occupancy . American Society of Heating refrigerationg and air conditioning engineers, 1992. [20] Y . Cheng, J. Niu, and N. Gao, “Thermal comfort models: A re view and numerical investig ation, ” Building and En vir onment , vol. 47, pp. 13–22, 2012. [21] M. van Otterlo and M. Wiering, “Reinforcement learning and markov decision processes, ” in Reinfor cement Learning . Springer , 2012, pp. 3–42. [22] V . Mnih, K. Kavukcuoglu, D. Silver , A. A. Rusu, J. V eness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al. , “Human-lev el control through deep reinforcement learning, ” Natur e , vol. 518, no. 7540, p. 529, 2015. [23] M. Kummert, P . Andr ´ e, and J. Nicolas, “Optimal heating control in a passiv e solar commercial building, ” Solar Energy , vol. 69, pp. 103–116, 2001. [24] S. W ang and X. Jin, “Model-based optimal control of V A V air- conditioning system using genetic algorithm, ” Building and Envir on- ment , vol. 35, no. 6, pp. 471–487, 2000. [25] Y . Ma, F . Borrelli, B. Hencey , B. Coffe y , S. Bengea, and P . Haves, “Model predictiv e control for the operation of building cooling systems, ” IEEE T ransactions on contr ol systems technology , v ol. 20, no. 3, pp. 796–803, 2012. [26] T . W ei, Q. Zhu, and M. Maasoumy , “Co-scheduling of HV AC control, EV charging and battery usage for building energy efficienc y , ” in Pr o- ceedings of the 2014 IEEE/ACM International Confer ence on Computer- Aided Design . IEEE Press, 2014, pp. 191–196. [27] F . Oldewurtel, A. Parisio, C. Jones, M. Morari, D. Gyalistras, M. Gw- erder , V . Stauch, B. Lehmann, and K. Wirth, “Energy efficient building climate control using stochastic model predictiv e control and weather predictions, ” in Proceedings of the 2010 American control confer ence , no. EPFL-CONF-169733. Ieee Service Center, 445 Hoes Lane, Po Box 1331, Piscataway , Nj 08855-1331 Usa, 2010, pp. 5100–5105. [28] C. W . Anderson, D. Hittle, M. Kretchmar , P . Y oung, J. Si, A. Barto, W . Powell, and D. Wunsch, “Robust reinforcement learning for heating, ventilation, and air conditioning control of buildings, ” Handbook of Learning and Appr oximate Dynamic Pro gramming , pp. 517–534, 2004. [29] J. Pan, R. Jain, S. Paul, T . V u, A. Saifullah, and M. Sha, “ An internet of things frame work for smart energy in buildings: designs, prototype, and experiments, ” IEEE Internet of Things Journal , vol. 2, no. 6, pp. 527–537, 2015. [30] D. Minoli, K. Sohraby , and B. Occhiogrosso, “IoT considerations, requirements, and architectures for smart buildingsenergy optimization and next-generation building management systems, ” IEEE Internet of Things Journal , vol. 4, no. 1, pp. 269–283, 2017. [31] F . D. Foresee and M. T . Hagan, “Gauss-newton approximation to bayesian learning, ” in Pr oceedings of the 1997 international joint confer ence on neural networks , vol. 3. Piscataway: IEEE, 1997, pp. 1930–1935. [32] M. T . Hagan and M. B. Menhaj, “Training feedforward networks with the marquardt algorithm, ” IEEE transactions on Neural Networks , v ol. 5, no. 6, pp. 989–993, 1994. [33] D. Silver , G. Lev er, N. Heess, T . Degris, D. W ierstra, and M. Riedmiller, “Deterministic policy gradient algorithms, ” in ICML , 2014. [34] G. E. Uhlenbeck and L. S. Ornstein, “On the theory of the bro wnian motion, ” Physical r eview , vol. 36, no. 5, p. 823, 1930. [35] “TRNSYS: T ransient system simulation tool, ” http://www .trnsys.com, accessed, October 2018. [36] “Pytorch: An open source deep learning platform, ” https://pytorch.org, accessed, October 2018. [37] “MySQL: the world’ s most popular open source database, ” https://www . mysql.com, accessed, October 2018. [38] R. J. De Dear, “ A global database of thermal comfort field experiments, ” ASHRAE transactions , vol. 104, p. 1141, 1998.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment