VeGaS: Video Gaussian Splatting
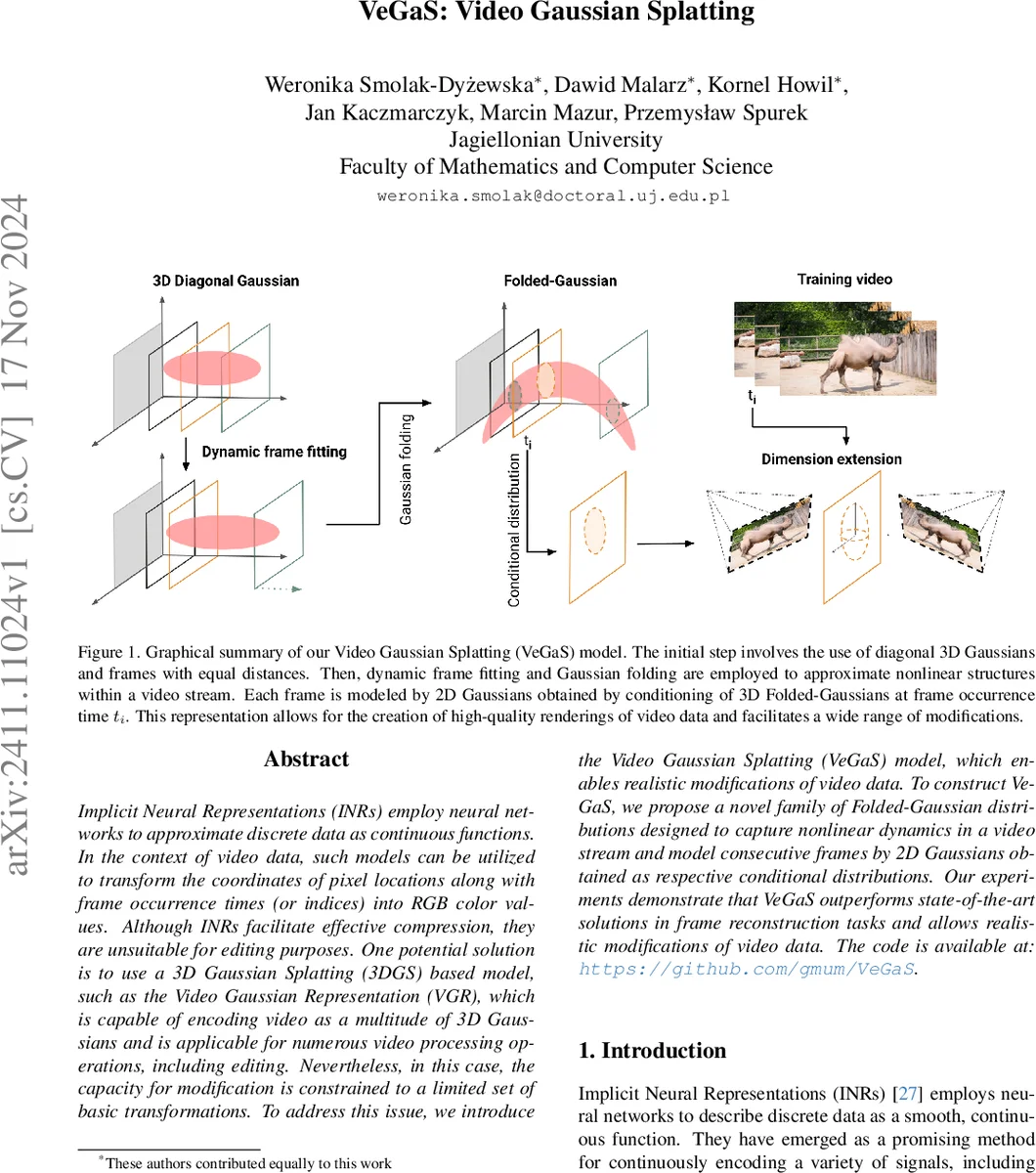
Implicit Neural Representations (INRs) employ neural networks to approximate discrete data as continuous functions. In the context of video data, such models can be utilized to transform the coordinates of pixel locations along with frame occurrence times (or indices) into RGB color values. Although INRs facilitate effective compression, they are unsuitable for editing purposes. One potential solution is to use a 3D Gaussian Splatting (3DGS) based model, such as the Video Gaussian Representation (VGR), which is capable of encoding video as a multitude of 3D Gaussians and is applicable for numerous video processing operations, including editing. Nevertheless, in this case, the capacity for modification is constrained to a limited set of basic transformations. To address this issue, we introduce the Video Gaussian Splatting (VeGaS) model, which enables realistic modifications of video data. To construct VeGaS, we propose a novel family of Folded-Gaussian distributions designed to capture nonlinear dynamics in a video stream and model consecutive frames by 2D Gaussians obtained as respective conditional distributions. Our experiments demonstrate that VeGaS outperforms state-of-the-art solutions in frame reconstruction tasks and allows realistic modifications of video data. The code is available at: https://github.com/gmum/VeGaS.
💡 Research Summary
The paper “VeGaS: Video Gaussian Splatting” addresses a fundamental limitation of current video representations: while Implicit Neural Representations (INRs) provide high‑quality reconstruction and strong compression, they embed all scene information into network weights, making frame‑level editing practically impossible. Conversely, 3‑D Gaussian Splatting (3DGS) models a scene as a set of explicit Gaussians, enabling faster rendering and some editing, but existing video‑specific extensions such as Video Gaussian Representation (VGR) only support linear transformations (translation, scaling) and cannot capture complex, non‑linear motion.
To overcome these constraints, the authors introduce a novel probability distribution called the Folded‑Gaussian. Starting from a multivariate normal distribution over a space‑time variable x = (s, t), they apply a time‑dependent affine transformation to the spatial component:
s → √a(t)·(s − m_s) + m_s + f(m_t − t)
where a(t)∈(0, 1] rescales the spatial variance based on the likelihood of the current time step, and f(·) is a polynomial that produces a non‑linear shift along an arbitrary curve. The conditional distribution s|t remains Gaussian (with mean m_s + f(m_t − t) and covariance a(t)Σ_s), but the joint distribution over (s, t) becomes non‑Gaussian, allowing the model to represent curved trajectories, objects that appear only for a subset of frames, and other complex temporal dynamics. The authors provide a rigorous derivation, showing that the transformation is affine, preserving Gaussianity conditionally, and that the overall density integrates to one.
Integrating Folded‑Gaussians into the 3DGS pipeline yields the Video Gaussian Splatting (VeGaS) framework. Initially, a dense set of diagonal 3‑D Gaussians is placed uniformly across time. Dynamic frame fitting and “Gaussian folding” then adapt each Gaussian’s parameters according to the learned a(t) and f(·) functions, effectively “folding” the 3‑D cloud along the temporal axis. Conditioning each 3‑D Gaussian at a specific frame time t_i produces a 2‑D Gaussian set that directly represents that frame. These 2‑D Gaussians are rendered using a MiraGe‑style approach, which optimizes per‑Gaussian opacity, color, and position while preserving the efficiency of splatting. The framework distinguishes between extensive Gaussians (modeling static background) and brief Gaussians (capturing transient foreground objects), achieving a compact representation that scales well with video length.
The experimental evaluation uses the DAVIS dataset and several other video benchmarks. Quantitatively, VeGaS outperforms VGR and state‑of‑the‑art INR models on PSNR (by 1.2–2.5 dB), SSIM (by 0.02–0.04), and LPIPS (by 0.05–0.08). Qualitatively, the authors demonstrate realistic editing operations: selecting individual objects, applying non‑linear motion paths, scaling, and color multiplication. These edits preserve temporal coherence and visual fidelity, unlike the limited linear transformations supported by VGR. Training time increases modestly (≈30 % over vanilla 3DGS) but remains practical, and inference runs at real‑time rates (>30 fps) on a single GPU.
Key contributions are threefold: (1) the definition of Folded‑Gaussian distributions that capture non‑linear spatio‑temporal patterns while retaining tractable conditional Gaussians; (2) the VeGaS architecture that seamlessly merges Folded‑Gaussians with 3DGS and MiraGe, enabling both global video editing and per‑frame manipulation; (3) comprehensive experiments showing superior reconstruction quality and flexible editing capabilities.
In summary, VeGaS bridges the gap between high‑fidelity video representation and practical editability. By embedding non‑linear temporal dynamics directly into an explicit Gaussian splatting framework, it offers a scalable, efficient, and versatile solution for modern video processing tasks such as interactive editing, augmented reality, and dynamic scene synthesis.
Comments & Academic Discussion
Loading comments...
Leave a Comment