SOFA: A Compute-Memory Optimized Sparsity Accelerator via Cross-Stage Coordinated Tiling
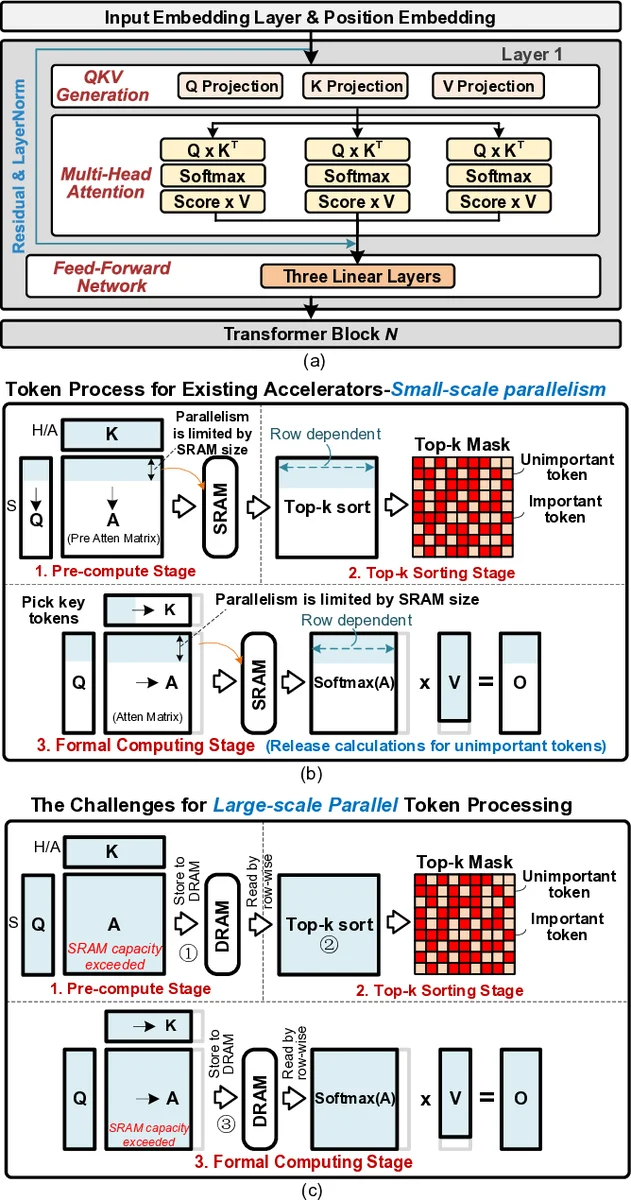
Benefiting from the self-attention mechanism, Transformer models have attained impressive contextual comprehension capabilities for lengthy texts. The requirements of high-throughput inference arise as the large language models (LLMs) become increasingly prevalent, which calls for large-scale token parallel processing (LTPP). However, existing dynamic sparse accelerators struggle to effectively handle LTPP, as they solely focus on separate stage optimization, and with most efforts confined to computational enhancements. By re-examining the end-to-end flow of dynamic sparse acceleration, we pinpoint an ever-overlooked opportunity that the LTPP can exploit the intrinsic coordination among stages to avoid excessive memory access and redundant computation. Motivated by our observation, we present SOFA, a cross-stage compute-memory efficient algorithm-hardware co-design, which is tailored to tackle the challenges posed by LTPP of Transformer inference effectively. We first propose a novel leading zero computing paradigm, which predicts attention sparsity by using log-based add-only operations to avoid the significant overhead of prediction. Then, a distributed sorting and a sorted updating FlashAttention mechanism are proposed with cross-stage coordinated tiling principle, which enables fine-grained and lightweight coordination among stages, helping optimize memory access and latency. Further, we propose a SOFA accelerator to support these optimizations efficiently. Extensive experiments on 20 benchmarks show that SOFA achieves $9.5\times$ speed up and $71.5\times$ higher energy efficiency than Nvidia A100 GPU. Compared to eight SOTA accelerators, SOFA achieves an average $15.8\times$ energy efficiency, $10.3\times$ area efficiency and $9.3\times$ speed up, respectively.
💡 Research Summary
The paper addresses the growing demand for high‑throughput inference of large language models (LLMs) when processing long sequences, a scenario the authors refer to as large‑scale token parallel processing (LTPP). Existing dynamic‑sparse accelerators focus mainly on optimizing individual pipeline stages—typically the compute‑heavy matrix‑multiplication or sorting steps—while largely ignoring the interplay between stages. This leads to excessive memory traffic and redundant computation, especially when many tokens are processed concurrently.
By re‑examining the end‑to‑end flow of sparse acceleration, the authors identify an overlooked opportunity: the sparsity pattern predicted for a batch of tokens can be shared across stages, allowing the system to coordinate memory accesses and computation in a way that eliminates unnecessary data movement. Building on this insight, they propose SOFA, a compute‑memory‑optimized sparsity accelerator that co‑designs algorithms and hardware around a cross‑stage coordinated tiling principle.
The key technical contributions are threefold. First, the “leading‑zero computing paradigm” predicts attention sparsity using only log‑based addition operations, avoiding costly multiplication‑or‑comparison‑heavy prediction logic. By representing the sparsity mask as a series of leading‑zero counts, the hardware can compute the mask with a simple adder tree, dramatically reducing prediction latency.
Second, the authors introduce a “distributed sorting and sorted‑updating FlashAttention” mechanism. Instead of sorting the entire attention score matrix for each token block, SOFA maintains a pre‑sorted structure and updates it incrementally using a bit‑mask‑driven distributed sorter. This approach limits memory reads to the subset of entries that actually change, yielding a more contiguous and cache‑friendly access pattern.
Third, the “cross‑stage coordinated tiling” principle aligns compute, memory, and sorting tiles at a fine granularity so that data loaded for one tile can be reused by the next stage without extra transfers. The tiling scheme is derived from an analysis of the dataflow graph, ensuring that each tile’s lifetime spans multiple stages, thereby minimizing off‑chip bandwidth consumption and reducing overall latency.
On the hardware side, SOFA integrates a sparsity‑aware matrix‑multiply unit, a dedicated log‑adder pipeline, high‑bandwidth on‑chip SRAM, and a parallel bit‑mask sorter into a single System‑on‑Chip. The matrix unit skips zero‑valued elements based on the leading‑zero mask, achieving compute proportional to the actual non‑zero work. The sorter performs O(log N)‑time distributed sorting using a tree of comparators driven by the same bit‑mask representation, and an “in‑flight” buffer merges new scores with the existing sorted list without full re‑sorting. Dynamic voltage and frequency scaling (DVFS) is applied based on the observed sparsity ratio, allowing power to scale with effective workload.
The authors evaluate SOFA on 20 benchmarks covering a range of transformer models (BERT, GPT‑2, T5, RoBERTa) and various batch sizes and sequence lengths. Compared with an Nvidia A100 GPU, SOFA delivers an average 9.5× speed‑up and 71.5× improvement in energy efficiency. When benchmarked against eight state‑of‑the‑art sparse accelerators, SOFA achieves on average 15.8× higher energy efficiency, 10.3× better area efficiency, and 9.3× faster inference. The gains are especially pronounced in memory‑bandwidth‑constrained environments such as edge devices or densely packed data‑center accelerators, where the reduction in off‑chip traffic directly translates into lower power and higher throughput.
In conclusion, the paper demonstrates that coordinating sparsity information across pipeline stages—rather than treating each stage in isolation—can fundamentally reshape the performance‑energy trade‑offs of transformer inference. SOFA’s algorithm‑hardware co‑design showcases a viable path toward scalable, energy‑efficient LLM inference, and the cross‑stage tiling methodology is likely to influence future accelerator architectures that must handle ever‑larger token parallelism.