EPOCH: Jointly Estimating the 3D Pose of Cameras and Humans
💡 Research Summary
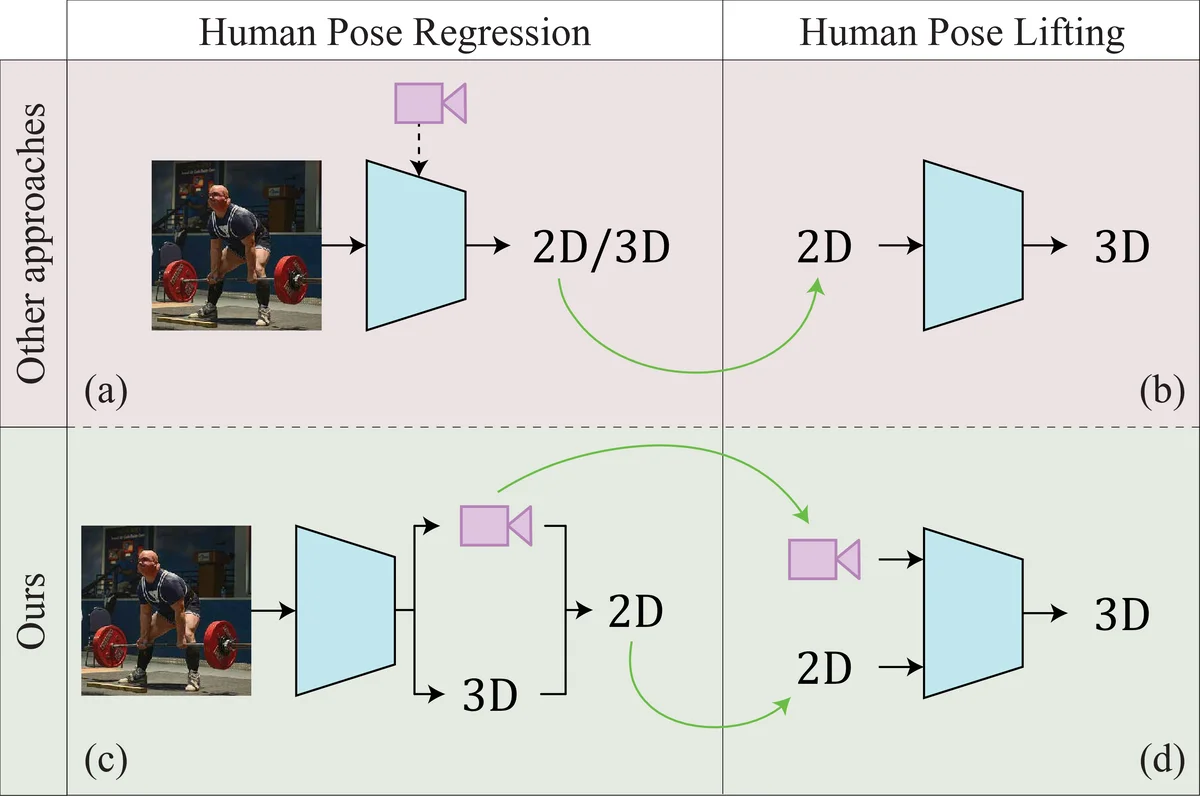
The paper introduces EPOCH, a novel framework that jointly estimates camera parameters and 3D human pose from a single RGB image. The authors argue that most monocular 3D human pose estimation (HPE) methods either rely on a weak‑perspective or orthographic camera model, which introduces depth and scale ambiguities, or they require large amounts of 3D ground‑truth data that are costly to acquire. EPOCH tackles both issues by (1) explicitly modelling the full perspective camera (intrinsic K and extrinsic R, T) and (2) learning to predict both 2D joint locations and camera parameters using only 2D pose supervision.
EPOCH consists of two sequential modules:
-
RegNet – a lightweight capsule‑based regressor that takes an image and outputs 2D joint coordinates together with the full camera matrix. RegNet is trained with weak supervision: only 2D joint annotations are needed. Internally it also predicts a provisional 3D pose, which is projected back to 2D using the estimated camera. This projection creates a self‑consistency signal that guides the learning of both pose and camera parameters.
-
LiftNet – an unsupervised 3D lifter that receives the 2D pose and camera parameters from RegNet and lifts the 2D skeleton to 3D. LiftNet is built around a cycle‑consistency architecture: a forward branch lifts 2D → 3D, rotates the 3D pose, projects it back to 2D, and compares the result with the original 2D input; a backward branch performs the inverse operations. No 2D or 3D ground truth is used in this stage; all supervision comes from reconstruction losses.
Key technical contributions in LiftNet include:
- Full perspective projection instead of the weak‑perspective used in prior work, allowing accurate handling of varying focal lengths and camera positions.
- Normalizing Flow (NF) regularizer based on the GLOW architecture (1×1 convolutions). Unlike earlier RealNVP‑based NFs that required PCA dimensionality reduction, GLOW can process the full 2D joint vector, providing a likelihood score that the projected 2D pose lies in the distribution of realistic human skeletons.
- Anthropomorphic constraints: a bone‑ratio loss that enforces near‑constant bone length ratios across subjects, and a novel limb‑fold loss that penalises implausible joint bending by measuring the alignment of limb vectors with the normal of the hip‑spine plane.
The overall loss for LiftNet combines L2 reconstruction terms, the NF negative log‑likelihood, and the two anthropomorphic penalties, ensuring that the lifted 3D pose is both geometrically consistent with the estimated camera and anatomically plausible.
Experiments on the standard benchmarks Human3.6M and MPI‑INF‑3DHP demonstrate that EPOCH achieves state‑of‑the‑art performance in both direct 3D pose regression and unsupervised lifting settings. The explicit camera estimation reduces scale and depth errors, leading to better generalisation on unseen subjects and “in‑the‑wild” scenarios. Moreover, the modular design keeps computational cost modest: RegNet’s capsule architecture is lightweight, and the GLOW‑based NF incurs minimal overhead.
In summary, EPOCH advances monocular 3D human pose estimation by (i) integrating a full perspective camera model into the learning pipeline, (ii) jointly learning pose and camera from only 2D annotations, (iii) employing a fully unsupervised cycle‑consistent lifter, and (iv) enforcing realistic human geometry through normalizing flows and dedicated anthropomorphic losses. This combination addresses the twin challenges of data scarcity and inherent 2D‑3D ambiguity, delivering robust and accurate 3D pose estimates across diverse imaging conditions.
Comments & Academic Discussion
Loading comments...
Leave a Comment